
NanoBASIC, un piccolo interprete BASIC da installare su una schedina Arduino Nano Every per provare ad emulare quella antica tecnologia a 8 bit degli home computer. Naturalmente, quella di Arduino è una tecnologia più evoluta, non paragonabile a quella degli anni 80-90 dello scorso secolo, ma sotto certi aspetti, non così distante dai "primordiali" computer che hanno fatto la gioia di tanti giovani informatici dell’epoca.
Introduzione
Recentemente, mi è capitato di rimettere in sesto una vecchia gloria degli home computer, un Commodore VIC 20 (anno 1982!); dopo averne ripristinato il circuito e testato il corretto funzionamento, collegandolo tramite apposito cavo adattatore ad un monitor provvisto di presa scart, sono rimasto per qualche istante a fissare la schermata iniziale, quella con cui il computer si presenta al mondo, niente di speciale se non per l’indicazione della memoria (RAM) disponibile, “… 3.583 bytes free“ (Figura 1). Mi ricordo di aver pensato quanto la tecnologia a 8 bit dei primi home computer fosse lontana dall’attuale mondo dell’informatica dove ormai un notebook con prestazioni nella media deve possedere una RAM di diversi ordini di grandezza superiore a quei pochissimi bytes del VIC20. Eppure, all’epoca era possibile far eseguire alla macchina programmi e video giochi di discreta complessità.

Figura 1: Schermata iniziale del Commodore VIC 20
Avendo avuto passate esperienze professionali come sistemista ed essendo da sempre appassionato nello sviluppo di applicativi in linguaggio C, un pò per gioco e un pò per sfida mi sono domandato se si potesse mettere a punto un interprete BASIC utilizzando l’ambiente di sviluppo integrato di Arduino per poi caricarlo su una delle numerose schede a 8 bit in circolazione. Scartate le schede basate sull’ATMEGA 328P (Arduino UNO, ecc..) a causa della poca RAM, solo 2Kb, la scelta della board da utilizzare è caduta su Arduino Nano Every, che con i suoi 6Kb di memoria RAM e i suoi 48Kb di memoria flash sembra essere il candidato ideale per testare quanto pensato. Prima di addentrarci nella descrizione del software, spendiamo qualche parola sui concetti di interpreti e compilatori.
Interpreti e compilatori
Spesso, si fa confusione su questi due tipi di applicativi e soprattutto chi da poco ha iniziato a programmare tende a sovrapporre le due cose. Esistono interi corsi universitari e numerosi testi di riferimento su argomenti relativi al funzionamento, allo sviluppo e all’implementazione di questi tipi di software e non potrebbe essere diversamente visto che si tratta di applicativi che sono alla base del “colloquio” uomo-macchina. Si tratta di una materia generalmente complessa, ma voglio dedicare alcune righe a chiarire la differenza che esiste tra un interprete e un compilatore.
In linea di principio, sia i compilatori che gli interpreti hanno il compito di tradurre in linguaggio macchina, ovvero in istruzioni in codice binario immediatamente eseguibili dalla CPU, i comandi ad alto livello inseriti dal programmatore. La differenza sostanziale è come avviene questa traduzione: i compilatori come ad esempio il compilatore C/C++, presente nell’IDE di Arduino, traducono con una serie di passaggi il codice sorgente direttamente in linguaggio macchina in un formato (il file .hex) che può essere direttamente caricato sulla scheda ed eseguito dal microcontrollore. Gli interpreti invece sono degli applicativi normalmente residenti sul computer o nel nostro caso sulla board Arduino Nano che all’acquisizione del file con il codice sorgente eseguono in tempo reale le istruzioni in esso contenute.
Appaiono subito chiare alcune differenze:
- un codice sorgente interpretato è eseguito più lentamente rispetto a un codice sorgente precedentemente compilato e tradotto in linguaggio macchina. Questo perché l’interprete deve tradurre in tempo reale il codice sorgente, cosa che il compilatore ha già fatto nella fase di traduzione in linguaggio macchina.
- L’interprete esegue una linea di codice per volta e si ferma ogni volta che intercetta un errore. Un compilatore acquisisce l’intero codice sorgente e produce l’intera lista di eventuali errori, questo determina una maggiore difficoltà nel “debugging” dei programmi compilati rispetto a quelli interpretati.
- Un interprete oltre che più lento è molto meno efficiente rispetto ad un compilatore.
- Un interprete è comunque, nella maggioranza dei casi, molto più contenuto come dimensioni e complessità rispetto ad un compilatore.
Per chi vuole approfondire, nella sezione Bibliografia alla fine dell'articolo troverà qualche suggerimento.
L’interprete BASIC
Terminata questa brevissima introduzione sulle differenze tra compilatori ed interpreti e lungi da me l’idea di fare una lezione specifica, introducendo concetti come analisi lessicale, sintattica, semantica, tabella dei simboli, type checking, ecc., mi limiterò alla descrizione dei concetti fondamentali e come questi sono stati messi in pratica. Esistono numerosi tipi di linguaggi di programmazione, alcuni studiati e sviluppati in maniera specifica per determinati scopi; basti pensare al FORTRAN, un linguaggio di programmazione appositamente sviluppato per il calcolo numerico, altri come il BASIC creati per essere facilmente utilizzabili.
BASIC, infatti, è un acronimo e sta per “Beginner's All-purpose Symbolic Instruction Code”, fu sviluppato all’inizio degli anni 60 del secolo scorso presso l’università di Dartmouth per facilitare la stesura e l’inserimento dei programmi realizzati dagli studenti nell’unità centrale, ma successivamente, con l’avvento degli home computer, il suo utilizzo si diffuse notevolmente sia per il basso dispendio di risorse macchina che normalmente richiede, sia per la semplicità di utilizzo da parte dei programmatori.
Personalmente, ho sempre visto il BASIC come una sorta di versione fortemente semplificata dell’Assembly, d’altronde similmente all’Assembly, il BASIC, nella sua configurazione originale, è un linguaggio destrutturato basato su pochissime istruzioni e in cui si fa uso massiccio di salti condizionati e subroutine. Come anticipato nel precedente paragrafo, in generale l’interprete BASIC è un applicativo che quando è in esecuzione nel computer è capace per l’appunto di “interpretare” comandi ed istruzioni inserite dal programmatore e di farle eseguire dal microprocessore. Nel nostro caso, similmente a quanto succedeva con i primi home computer, l’interprete è dotato di una semplice SHELL o editor a riga di comando (Figura 2) che permette di inserire e far eseguire direttamente istruzioni e comandi.
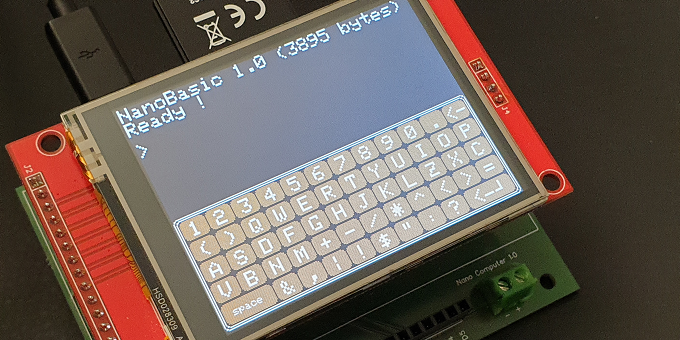
Figura 2: La SHELL (editor a riga di comando) di NanoBASIC
Il suo funzionamento è piuttosto semplice, in pratica, grazie alle funzionalità touch del display tramite una tastiera virtualizzata sarà possibile comporre una stringa alfanumerica con lunghezza massima di 127 caratteri (statement) che alla pressione del tasto "<─┘" (enter) verrà inviata alla funzione principale dell'interprete per essere successivamente convertita in una linea di codice da inserire in un programma o in una serie di istruzioni/comandi da eseguire immediatamente.
Lo sviluppo dell'interprete in linguaggio C
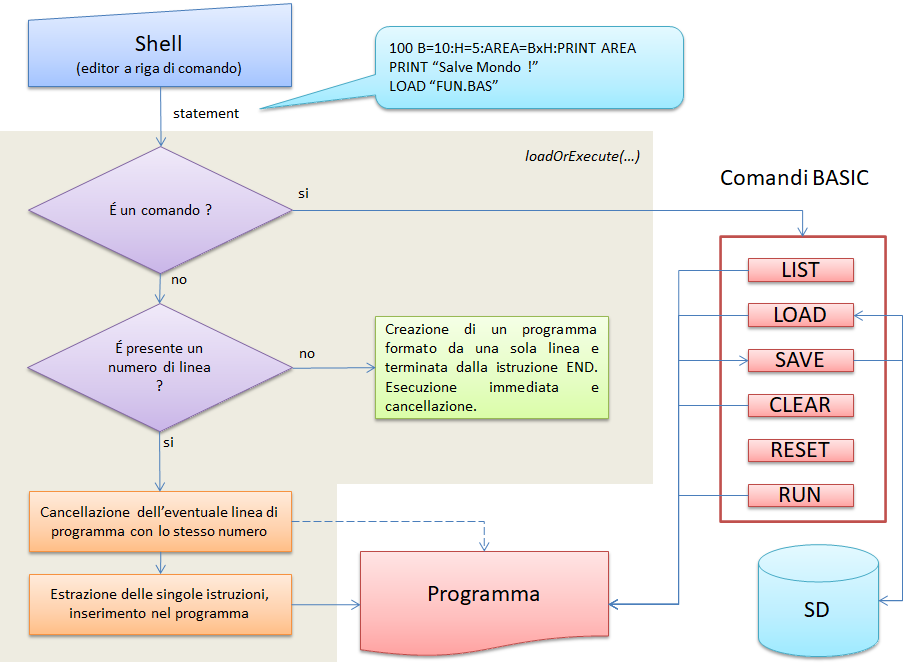
Figura 3: Schema a blocchi della funzione "loadOrExecute(...)"
Premetto che ci sono innumerevoli approcci che possono essere utilizzati per sviluppare un interprete, nel caso specifico si è cercato di coniugare la semplicità con un occhio di riguardo al consumo di risorse, in particolare di memoria. Di seguito, vedremo lo sviluppo della funzione centrale che governa in pratica l'intero funzionamento dell'interprete e che fa riferimento al diagramma di flusso di Figura 3 e successivamente la struttura dati utilizzata per contenere il programma.
Iniziamo con il dire che se si vuole realizzare un'applicazione per una scheda microcontrollore a 8 bit con l'obiettivo di minimizzare l'uso delle risorse e massimizzare la velocità di esecuzione dell'applicazione, occorrerebbe utilizzare un linguaggio di programmazione il più possibile a basso livello, l'ideale sarebbe utilizzare direttamente l'assembly ma spesso la complessità dei progetti porta a preferire un linguaggio che sia un giusto compromesso tra semplicità nella scrittura del codice e prestazioni. Nella fattispecie possiamo dire che il linguaggio C sia un'ottima soluzione.
Detto questo, torniamo al diagramma di flusso di Figura 3 e diamo le seguenti definizioni:
- Una istruzione BASIC è un oggetto rappresentato da una sequenza di caratteri codificata la cui esecuzione da parte dell'interprete determina un qualche tipo di evento, come ad esempio la stampa a video del risultato di una operazione matematica o la variazione di stato di una porta del microcontrollore, ecc..
- Una linea di programma, in inglese spesso chiamata "statement", è una sequenza di istruzioni BASIC separate dal carattere ":" (due punti) eventualmente preceduta da una etichetta numerica.
- Un programma è una sequenza di linee ordinate sulla base dell'etichetta numerica posta all'inizio della linea stessa.
- Infine, definiamo un comando BASIC come una particolare istruzione che non può essere inserita in un programma, ma che ha lo scopo di operare direttamente su di esso; tipicamente, sono i comandi che servono per eseguire il programma (RUN) o cancellarlo dalla memoria (CLEAR) o di salvarlo sulla scheda SD (SAVE), ecc...
La distinzione tra istruzioni e comandi é specifica di NanoBASIC, in realtà si tratta di due sinonimi, ma questa distinzione lessicale ci è utile per meglio comprendere come è stato sviluppato l'interprete.
Partendo da queste definizioni possiamo dire che le sequenze di codice inserite saranno divise in 3 tipologie di oggetti:
- Linee di istruzioni precedute da un'etichetta numerica le quali dovranno essere inserite in maniera ordinata nel programma che si va a sviluppare in memoria.
- Linee di istruzioni non precedute da etichette numeriche, le quali quindi saranno immediatamente eseguite.
- Comandi che determineranno qualche tipo di azione sul programma.
Compito di fare questa elaborazione è dato alla funzione loadOrExecute, che inserita in un loop infinito, riceve tramite la SHELL la sequenza di caratteri digitata (statement), la analizza ed esegue le opportune operazioni in funzione di quanto abbiamo sopra descritto:
Di seguito il codice sorgente della funzione:
ERR loadOrExecute(char *statement, int *exit_at_line) {
bool exit_loop = false;
ERR err = NO_ERROR;
int line_number = 0;
BASCMD cmd = NOCMD;
// check if the statement is a basic command RUN,LIST,LOAD ...//
cmd = getCommandCode(statement);
// if is not a basic command //
if (cmd == NOCMD) {
// try to get the line number of the statement //
line_number = getStatementLineNumber(statement);
// a line number must be greater than zero !
if (line_number < 0) return WRONG_LABEL;
// if a program line is inserted with a line number already present, the
// previous program line is deleted
if (line_number && start_program_pointer != NULL )
searchinstructionTodelete(line_number);
// splits the program line into the individual instructions to be executed //
while (!exit_loop) {
char instruction[MAXSTRING] = "";
// split the statement into single program instruction //
exit_loop = splitStatement(statement, instruction);
// if it is not empty, it is inserted in the program list//
if (*instruction != '\0') {
*exit_at_line = line_number;
err = insert_program_line(line_number, stringTrim(instruction));
if (err) return err;
}
}
// if the program line does not have a line number, it is executed immediately! //
if (!line_number) {
// end the program line with the "END" instruction //
insert_program_line(0,(char *) "END");
err = execRUN(exit_at_line);
searchinstructionTodelete(0); // delete program line number 0 //
if (err) return err;
deleteVariableList(); // delete variables list //
}
return NO_ERROR;
} else {
if (cmd == _RUN) {
// runs the stored program //
err = execRUN(exit_at_line);
if (err) return err;
} else
if (cmd == _LIST) {
// displays the stored program //
err = execLIST();
if (err) return err;
} else
if (cmd == _LOAD) {
// load a program from an external file
err = execLOAD(statement, exit_at_line);
if (err) return err;
} else
if (cmd == _SAVE) {
// save a program in an external file
err = execSAVE(statement);
if (err) return err;
} else
if (cmd == _CLEAR) {
// deletes the stored program //
err = execCLEAR();
if (err) return err;
} else
if (cmd == _RESET) {
// software board reset //
execRESET();
}
}
return NO_ERROR;
}
La gestione del programma e la sua esecuzione
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2928 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.



