
Il Direct Memory Access, o DMA, insieme alla cache rappresentano gli elementi fondamentali di un sistema embedded quando si vuole incrementare le sue prestazioni. In un’architettura multi-core come ARM11 o Cortex-A9, quali sono le considerazioni da tenere presente? O meglio, come si relazionano con le risorse di un sistema operativo come Linux?
L’uso della cache e di un DMA comportano diverse considerazioni. Il progettista di applicazioni firmware, quali ad esempio un device driver, ha la necessità di garantire la coerenza della memoria shared in un sistema quando, a maggior ragione, sono presenti diversi core nel sistema. Non solo, la presenza di un sistema multi-core ha degli impatti significativi anche nel boot di un sistema operativo come Linux. A questo proposito la figura 1 pone in evidenza il meccanismo di boot su un ARM con sistema operativo Linux.
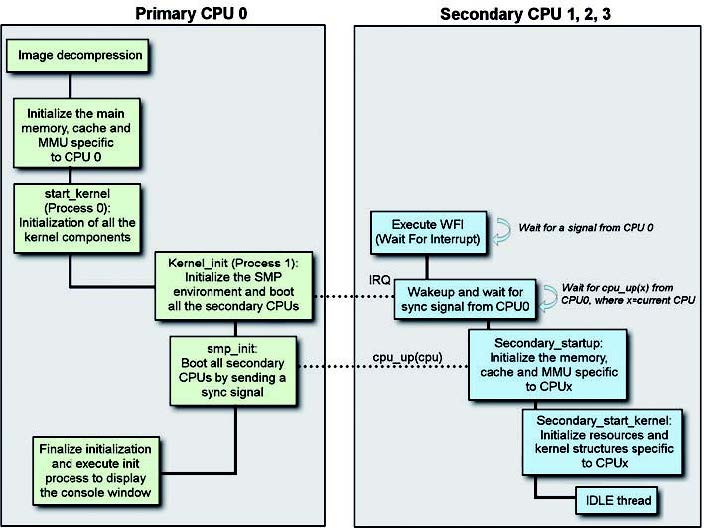
Figura 1: boot Linux in un sistema multicore.
Il bootloader, al termine della fase preliminare, sposta il controllo all’immagine del kernel passando alcuni parametri per dare precise indicazioni di boostrap. L’inizio della parte compressa del codice di Linux si trova nel file assembler arch/arm/boot/compressed/head.S. Da questo punto, il processo di boot si compone da tre fasi principali. Per prima cosa il kernel decomprime sé stesso e, subito dopo, il controllo passa alla sezione del kernel dipendente dal processore (ad esempio ARM 11 MPCore): si inizializza così la CPU e la memoria. Al termine di questa procedura il controllo viene ceduto alla parte del kernel indipendente dal processore in uso: si effettua il boot della parte SMP di tutti i core ARM11 e si inizializzano tutte le componenti del kernel e la relativa struttura dati. In un ambiente Linux SMP, la CPU0 è responsabile dell’inizializzazione di tutte le risorse così come in un ambiente a singolo core. Una volta configurata, tutte le risorse sono controllate con un meccanismo di sincronizzazione, quale spinlock. La CPU0 ha la responsabilità poi di configurare la cosiddetta boot page translation, in questo modo un eventuale un core secondario può effettuare il boot da una sezione secondaria di Linux senza ricorrere alla tabella dei vettori. Quando un core secondario poi effettua il boot della stessa immagine di Linux, questo accederà ad una locazione specifica in questo modo si inizializzeranno solo le risorse specifiche a loro assegnate (cache o MMU) con nessun impatto alle risorse già inizializzate e pronte all’uso. Questo è, in maniera sommaria, quelle che succede al momento del boot di Linux in un’architettura SMP. Il sistema operativo Linux, dalla versione 2.6, ha tenuto pesantemente in considerazione meccanismi di questo tipo per garantire la coerenza dei dati. Quando parliamo di coerenza delle informazioni, in un sistema come Linux dalla versione 2.6 è necessario introdurre il concetto di SMP o Symmetric Multi-Processing. Il Symmetric MultiProcessing è un meccanismo che si utilizza quando dobbiamo utilizzare un processore composto di due o più core perfettamente equivalenti che condividono la memoria principale con gli stessi diritti di accesso. Tipicamente un sistema operativo dovrebbe girare su tutti i core in maniera perfettamente trasparente attraverso di versi task o processi. Qualora questi core utilizzino una cache locale allora sarà necessario definire e utilizzare un meccanismo per rendere coerente l’informazione in essa contenute. I processori come ARM11 MPCore o Cortex-A9 MPCore dispongono di un componente hardware conosciuto come Soop Control Unit, o SCU. La coerenza delle informazioni tra i dati della cache e i processori è in carico a questo modulo hardware.
Coerenza della cache
La coerenza della cache in un sistema multicore è di estrema importanza perché un errato funzionamento renderebbe le informazioni ivi contenute inservibili. In un sistema con cache, memoria condivisa o multicore, il meccanismo implementato per mantenere la coerenza tra tutti i processori e le cache locali è anche chiamato cache coherency protocol. Questo meccanismo è in realtà una macchina a stati utilizzata per governare il corretto funzionamento, con le relative condizioni, di ogni cache assegnata ad ogni core nel corso del loro funzionamento. Per fare questo di solito si utilizza un meccanismo a tagging sulle cache con un identificatore del loro stato in relazione al comportamento del sistema. Lo stato è gestito, in maniera trasparente, da un componente hardware. Su ARM11 e su Cortex-A9 MPCore esiste il MESI cache coherency protocol. In maniera continua, nel corso del loro funzionamento, ogni cache è dinamicamente tracciata e marcata mediante uno stato definito come, ad esempio, Modified, Exclusive, Shared o Invalid secondo l’operazione associata. Il protocollo MESI prende il nome, infatti, da Modified, Exclusive, Shared e Invalid. Il MESI è un protocollo write-back: i blocchi sono aggiornati in memoria solo quando una CPU finisce di scriverci. Con lo stato Modified la cache corrente è identificata come inconsistente, vale a dire che è in corso l’aggiornamento con il proprio livello di gerarchia, con la cache secondaria o memoria principale. In sostanza, dati sono presenti solo in una identificata cache e risulta non allineata Al contrario, con lo stato di Exclusive si indica che la cache corrente non è inconsistente ed è in corso l’aggiornamento con il proprio livello di gerarchia, della cache L2 o della memoria principale. In sostanza, i dati sono presenti solo in una identificata cache e risulta allineata. Con lo stato Shared si identificano due situazioni; infatti, oltre a ricordare che la cache è soggetta alle modifiche, ovverosia è in corso di aggiornamento, con il proprio livello di gerarchia, ma anche è duplicata in un’altra, o più di altre, core cache. In sostanza, l’informazione è presente in più cache e la memoria risulta allineata. Infine, con lo stato Invalid si suole indicare che la cache non dispone di dati coerenti. La lettura di un blocco MODIFIED obbliga il richiedente ad attendere ed il possessore ad allineare la memoria (ridiventa SHARED). La scrittura di un blocco MODIFIED obbliga inoltre il possessore a marcare il blocco come INVALID dopo averlo copiato in memoria. Si veda la figura 2 e 3 per lo stato delle linee.
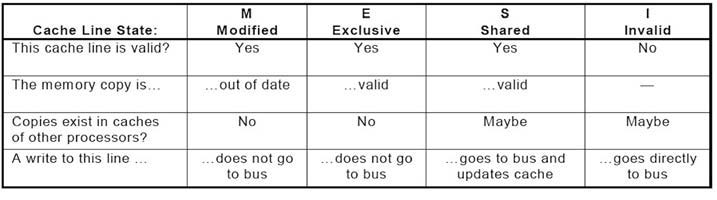
Figura 2: protocollo MESI.
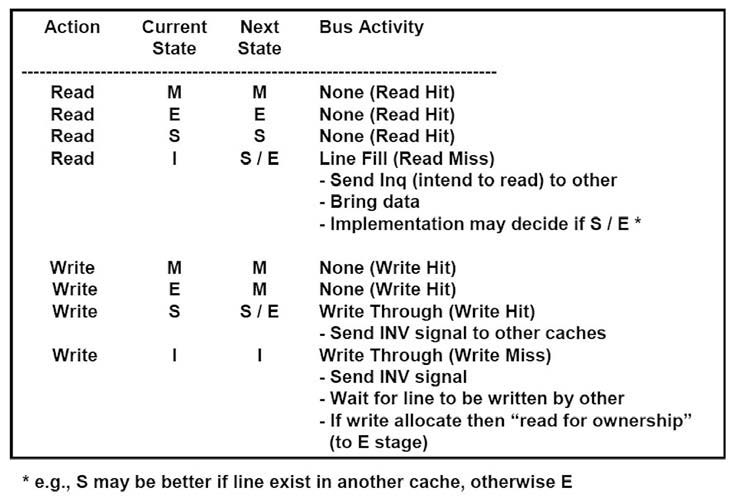
Figura 3: lo stato delle linee nel protocollo MESI.
In un ARM MPCore la coerenza è implementata e gestita dal modulo SCU. Questo modulo SCU monitora il traffico tra la cache locale L1 con il livello successivo della gerarchia. Al momento del boot, ogni core può essere selezionato per definire il dominio della coerenza, in questo modo il modulo SCU dovrà mantenere il dominio così registrato allo startup. La figura 4 mette in evidenza la relazione del modulo SCU.
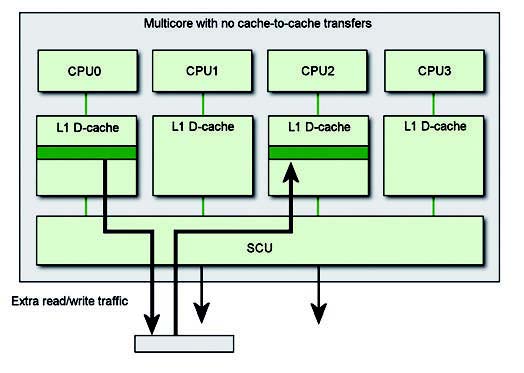
Figura 4: i dati vengono trasferiti da una cache all’altra passando per la memoria esterna.
Occorre a questo punto chiarire un importante aspetto. Vale a dire, diventa necessaria chiarire il ruolo e il funzionamento dei processori multi-core di tipo simmetrico con la modalità operativa del sistema operativo in relazione ai core presenti. In un’implementazione letterale del MESI cache coherence protocol si dimostra che la sua realizzazione è piuttosto inefficiente; infatti, un processo ha la necessità di dover emigrare per accedere a locazioni di memoria che risultano inserite in una cache primaria, L1 di un altro core (write-back). Per prima cosa il core originale avrà la necessità di invalidare e pulire la cache attinente rispetto al suo immediato livello di memoria. Una volta che i dati risultano disponibili ad un livello condiviso dell’architettura di memoria relativa (ad esempio, cache L2 o memoria principale), questi saranno caricati nel nuovo core. Si veda a questo proposito la figura 4. L’ARM 11 MPCore e il Cortex-A9 mantengono la compatibilità verso il protocollo MESI cercando di migliorare e perfezionare le prestazioni, oltre a ottimizzare i passaggi, allo scopo di risolvere i problemi evidenti di cui sopra, attraverso un Direct Data Intervention (DDI) e Cache-to-cache Migration. Con il primo passaggio, lo SCU cerca di capire a chi compete una richiesta corrente di memoria prima di interrogare i livelli di gerarchia diretti; al contrario, nel secondo caso, le eventuali richieste di memoria presenti su un altro core sono girati all’interrogante senza passare attraverso la memoria esterna, figura 5.
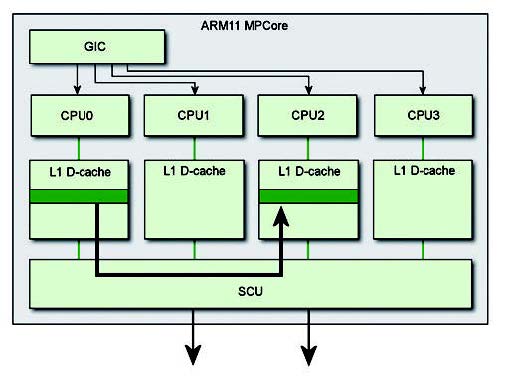
Figura 5: le richieste vengono inoltrate senza passare attraverso la memoria esterna.
Com’è naturale, oltre ai benefici prestazionali inerenti (si pensi ad un sistema senza la cache L2) è possibile ricavare anche un buon grado di ottimizzazioni. Infatti, in questo modo si riducono il traffico di memoria in ingresso e in uscita (L1) dal sottosistema così identificato riducendo il carico complessivo sulle interconnessioni e, a maggior ragione, si ottiene anche una riduzione del power consumption eliminando interazione con le memorie esterne. I due metodi correttivi, DDI e cache-to-cache migration, traggono particolari benefici da un sistema operativo di tipo SMP, dove i processi e dati possono emigrare tra core. Occorre notare, ad ogni modo, che, a maggior ragione, i due metodi hanno anche il beneficio di ridurre l’effetto collaterale di un software non coerentemente progettato. Alcune tecniche, quali il task affinity, rendono l’approccio più interessante alfine di migliorare le prestazioni del sistema. In realtà, nei moder ni sistemi operativi come Linux 2.6, si mira a gestire processi che sono eseguiti sulla stessa CPU (questa pratica è noto come l’affinità soft). Dalla versione 2.5.80 di Linux sono state inserite alcune chiamate di sistema così come mostrate nel listato 1: si utilizza un identificatore di processo per selezionare uno specifico core attraverso un’opportuna maschera al momento della sua chiamata.
#include <sched.h> int sched_setaffinity(pid_t pid, unsigned int cpusetsize, cpu_set_t *mask); int sched_getaffinity(pid_t pid, unsigned int cpusetsize, cpu_set_t *mask);
| Listato 1 – chiamata di sistema presente in Linux |
In diversi sistemi embedded a volte si utilizzano bus master; non solo, si utilizzano anche diversi livelli di memorie cache anche per aumentare le prestazioni complessive. In questo scenario, occorre mantenere la coerenza tra la CPU e i dati generati, o consumati, dai vari dispositivi di I/O. Il Cortex-A9 è il primo processore ARM in grado di offrire una piena coerenza sugli I/O per mezzo dell’ACP, o Accelerator Coherence Port. L’ACP, caratteristica opzionale del Cortex-A9, fornisce una porta AXI slave a 64-bit verso una DMA engine; grazie a questo si offre l’accesso al DMA attraverso lo SCU del Cortex-A9. Gli indirizzi di ACP sono fisici e possono essere acceduti dal modulo SCU alfine di offrire piena coerenza di I/O. Le letture sull’ACP permette di vedere la D-cache primaria, L1, di qualsiasi CPU, la scrittura su ACP consente, invece, di invalidare qualsiasi dato, vecchio, in L1. In questo modo l’ACP consente a qualsiasi dispositivo ester no, ad esempio DMA, di accedere direttamente ai dati nonostante la presenza di memoria L1 e indipendentemente dalla gerarchia in gioco. Si offre coerenza automatica in modo simile a quello che succede nel Cortex-A9 MP tra le CPU L1 D-cache. Il kernel di Linux è in grado di supportare arch_is_coherent(), una chiamata che permette di conoscere la coerenza di tutti i DMA.
DMA
Il DMA, o direct memory access, è una parte fondamentale dei moderni sistemi. Attraverso il DMA è possibile trasferire blocchi di dati senza l’intervento del processore risparmiando sull’overhead complessivo. I canali DMA operano in maniera indipendente dalla CPU e permettono di leggere/scrivere in memoria senza nessun intervento del processore. Il processore, o CPU, gestisce le operazioni di DMA attraverso un DMA controller. Durante i trasferimenti dei dati, opportunamente programmate dalla CPU, il processore può svolgere le sue normali operazioni senza per questo disturbare il trasferimento, o viceversa. Come si è scritto, la gestione del DMA è programmabile; in questo modo è possibile, al termine di un trasferimento, o inviare un interrupt al processore o segnalare la fine dell’operazione semplicemente abilitando un opportuno flag. Nel primo caso la gestione è anche chiamata a interrupt, mentre l’altra modalità è definita polling. Tipicamente un DMA è utilizzato per trasferire un blocco di memoria su di un network routing o per la gestione di un video streaming. L’opportunità di utilizzare un DMA è fortemente dipendente dal tipo di applicazione che si vuole realizzare o dalla quantità dei dati stessi. Grazie al controller del DMA è possibile definire la granularità del trasferimento liberando il processore da operazioni continue e ripetitive a carico del processing timing del sistema.
DMA in un sistema cached
L’uso del DMA in un sistema con presenza di memoria cache comporta alcune considerazione di ordine pratico. Sicuramente, l’uso di un DMA solleva considerazioni sia in un ambiente a core singolo sia con multi-core. La maggior parte dei sistemi operativi includono delle primitive in grado di gestire la coerenza tra CPUs e dispositivi esterni che accedono alla stessa memoria fisica. La tabella 1 pone in evidenza i possibili servizi che Linux permette per realizzare un ipotetico device driver.

Tabella 1 – funzionalità Linux
Quando si vuole, nella mappa di memoria, riservare zone di memoria non cache, allora è necessario configurare la memoria selezionata come uncached. I cambiamenti della configurazione di memoria, una volta definiti, sono immediatamente visibili a tutti i core presenti nel sistema. Quando il progettista software vuole utilizzare memoria di tipo cache è necessario specificare l’operazione che si vuole condurre sul DMA; a questo scopo si utilizza FROM_DEVICE o TO_DEVICE. Un meccanismo Zero-copy su DMA dovrebbe essere utilizzato ogni volta che risulti possibile. Un’user page risulta definita attraverso l’area di memoria, in questo modo i trasferimenti hanno direttamente luogo dalla porzione di memoria nel suo spazio di indirizzamento. Al contrario, un meccanismo di tipo non-zero-copy dovrebbe copiare i dati dai diversi buffer intermedi tra user e ker nel space aggiungendo un considerevole overhead al trasferimento. La versione 2.6 di Linux supporta la funzionalità di zero-copy sul DMA. Il modulo SCU su ARM11 MPCore non gestisce la coerenza. Esistono differenti soluzioni su ARM 11 MPCore che, tra l’altro, sono esposti sommariamente in tabella 2.

Tabella 2 – meccanismi utilizzati
Su un Cortex-A9 MPCore la gestione di una cache può essere fatta con il meccanismo di broadcat attraverso l’hardware verso le altre CPU in un sistema a memoria condivisa. Le operazioni su un’area non-shared non possono essere indirizzate come broadcast. La CPU sulla quale si compie l’operazione sulla cache traduce l’indirizzo da virtuale a fisico. Una CPU invierà solamente le operazioni di gestione della cache (broadcast) verso le altre CPU solo quando il bit SMP e FW è abilitato. Viceversa, una CPU può ricevere operazioni di broadcast quando il suo bit SMP è abilitato.

Le architetture dei sistemi multi core si suddividono in due gruppi principali: AMP e SMP. SMP (Symmetric Multi Processing) è l’architettura a cui si fa riferimento nell’articolo, tipica ad esempio dei sistemi desktop o dove comunque interessa aumentare il numero di core per ottenere migliori performance. Asymmetric Multi Processing (AMP) permette invece di avere più architetture, anche differenti tra loro, integrate nello stesso sistema. Il vantaggio è quello di poter attivare contemporaneamente sistemi operativi differenti tra loro, come ad esempio Android su un core e Linux o Windows su un altro core.