
Lo stack è un’area di memoria di fondamentale importanza, in modo particolare per le applicazioni embedded. Gli ambienti di cross compilazione forniscono strumenti in grado di definire la sua dimensione e di verificarne l’integrità in fase di run-time.
La gestione dello stack passa attraverso un particolare puntatore presente all’interno dell’architettura hardware. Con il termine stack vogliamo identificare una particolare struttura di memoria accessibile attraverso uno speciale registro, lo stack pointer. L’accesso diretto a questa zona di memoria è fortemente sconsigliato per evitare di alterarne il contenuto. Tipicamente, in uno stack sono memorizzate, in maniera dinamica, le variabili utilizzate all’interno di una funzione (variabili locali), i parametri della funzione, i dati necessari per ripristinare il precedente stack frame, incluso l’indirizzo dell’istruzione successiva alla chiamata. Oltre allo stack pointer, in alcune applicazioni si utilizza anche il frame pointer (fp). Lo stack pointer è una caratteristica propriamente hardware del processore; il frame pointer, al contrario, è un concetto utilizzato dai linguaggi di programmazione evoluti con lo scopo di attribuire una struttura dati a ciascuna funzione: una specie di stack secondario. Il listato 1 mostra la differenza tra questi due oggetti.
func(a, b);
move a, -(a7) ; inserisci sullo stack il parametro a (a7 = stack)
move b, -(a7) ; inserisci b
jsr func ; inserisci l’indirizzo di ritorno sullo stack
; e salta alla funzione func
—————
int func(int a, int b)
link a6,#-8 ; inserisci il contenuto di a6 sullo stack, a7 in a6
; a6 è il frame pointer della funzione func
; decrementa a7 di 8 per allocare spazio per a e b
; a6 è il frame pointer ed è utilizzato per le variabili locali
; a7 è lo stack pointer ed è utilizzato come buffer per
; inserire l’indirizzo di ritorno della funzione
unlk a6 ; copia a6 in a7, recupera il vecchio frame pointer
rts ; prende dallo stack pointer l’indirizzo di ritorno
| Listato 1 – Stack e frame pointer |
In questo articolo ci soffermeremo sullo stack pointer in quanto diretta espressione dell’hardware utilizzato per il controllo del flusso di esecuzione e come zona di memorizzazione dei dati sulle e tra le funzioni. Il listato 1 mostra un esempio con un processore 68k. Questo processore utilizza l’istruzione link per definire un frame pointer. Le variabili locali di una funzione possono essere referenziate specificando l’offset dallo stack pointer. Tuttavia, poiché nuovi dati sono impilati ed estratti, questo offset muta, per questa ragione si usa referenziare le variabili locali, e i parametri, mediante un offset dal frame pointer o A6. Ogni accesso allo stack è fatto con la modalità di tipo LiFo (Last In First Out): l’ultimo oggetto inserito è il primo a uscire. Alcuni processori utilizzano due istruzioni dedicate per intervenire su questa struttura, per esempio i processori x86 prevedono l’uso di push e pop: push aggiunge un elemento, mentre pop lo estrae dallo stack. Altri processori, al contrario, non hanno istruzioni dedicate: si accede allo stack attraverso un qualunque registro, se opportunamente inizializzato. In sostanza, lo stack è un insieme di segmenti logici (stack frame) che vengono impilati quando, per esempio, si chiama una funzione, ed estratti quando la funzione chiamata cede il controllo al chiamante. Secondo l’implementazione, lo stack, cresce verso l’alto o il basso. La figura 1 pone in evidenza questa particolarità dello stack.
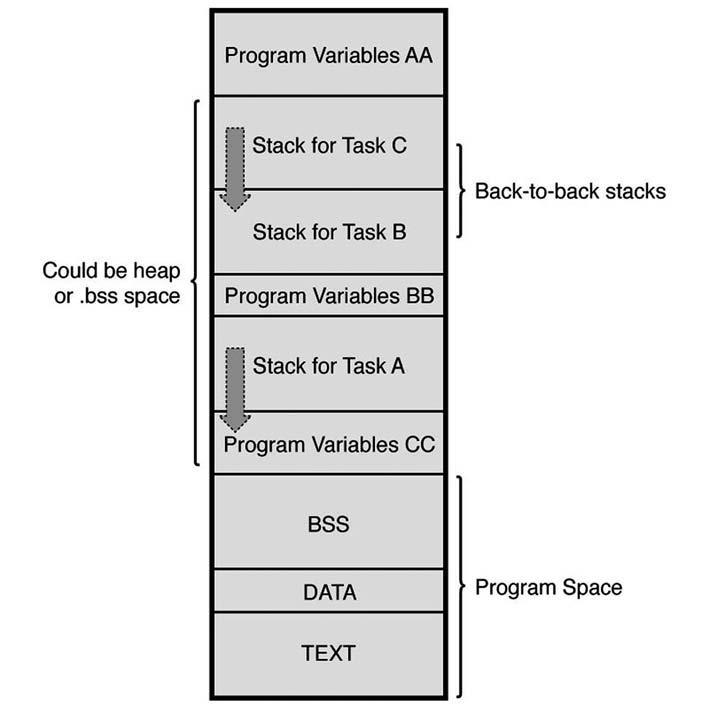
Figura 1: crescita
dello stack.
Esistono differenti metodi per tentare di gestire e tenere sotto controllo lo stack. Alcuni propongo di utilizzare, in Code Composer Studio, la funzionalità di Unified Breakpoint Manager, mentre altri preferiscono utilizzare un RTOS con funzionalità di stack checking (ad esempio RTX). Con Unified Breakpoint Manager si defisce una zona di memoria da monitorare attraverso simboli come stack o TSK0$stack, in seguito si imposta la modalità di accesso in scrittura. A questo punto il Code Compose Studio è attivo su ogni accesso in scrittura nella porzione di memoria selezionata. La figura 2 mostra lo stato del sistema con l’Unified Breakpoint Manager correttamente attivato, mentre la figura 3 pone in evidenza la violazione dello stack (lo vediamo nella finestra di watchpoint).
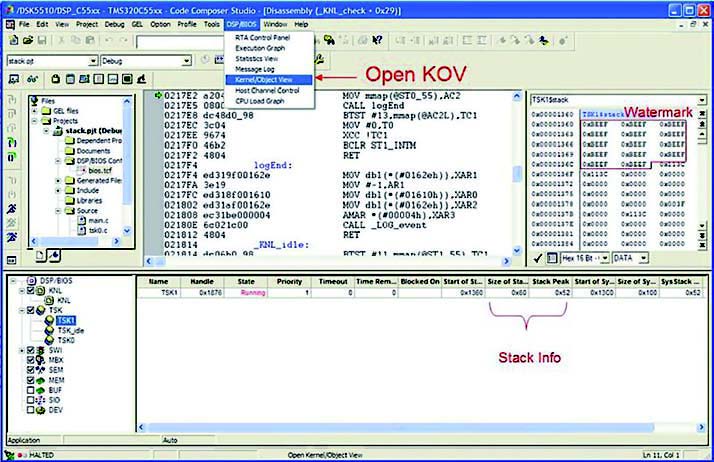
Figura 2: prima dello stack overflow.
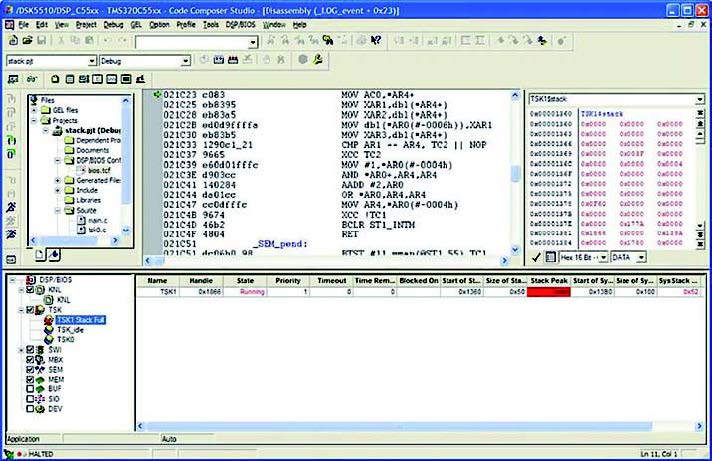
Figura 3: dopo lo stack overflow.
Lo stack e il mondo embedded
Lo stack pointer è una zona di memoria molto vulnerabile, tanto che eventuali problemi in quest’area possono compromettere il normale funzionamento dell’applicazione. Ad esempio, lo stack overflow è una particolare anomalia che si presenta quando un processo in esecuzione (ISR o semplice task) viola l’integrità dello stack: il suo contenuto è modificato o i limiti non sono più rispettati. In questo caso il processo corrente si comporta in maniera anomala e non più prevedibile. Per tentare di risolvere questo problema spesso si utilizza una MMU in grado di controllare i limiti di una zona di memoria sollevando, in caso di violazione, un’eccezione, oppure spesso ci si affida alle funzioni di un sistema operativo. In applicazioni embedded di piccole dimensioni, queste prerogative a volte non sono disponibili e la quantità di memoria è molto piccola tanto da non giustificare l’uso di un RTOS. Per questi motivi, per non incappare in uno stack overflow (o smash), alcuni sviluppano il loro codice seguendo delle linee di condotta suggerite dal buon senso e dalla singola esperienza professionale. Ad esempio, alcuni usano utility in grado di analizzare staticamente un’applicazione embedded; in particolare, dal sito della rivista è possibile scaricare un piccolo tool, scritto in Perl, che analizza staticamente un programma per il processore AVR. In qualsiasi applicazione embedded, la prima cosa da fare è quella di determinare la quantità di stack che la nostra applicazione ha necessità di utilizzare. In realtà, questo non è proprio un impegno di poco conto. Per ricavare la quantità di stack possiamo fare ricorso a tre modi: sperimentale, analitico o casuale. L’ultimo è sicuramente quello più utilizzato. Quali sono le considerazioni da tenere presenti indipendentemente dal processore in uso? Vediamone brevemente gli aspetti, anche se l’elenco non è chiaramente esaustivo:
» occorre controllare il disegno del nostro programma e verificare se esiste la reale esigenza di utilizzare eventi asincroni. È vivamente opportuno non utilizzare ISR. In caso contrario, si eviti di inserire nel corpo di una ISR delle chiamate a funzioni;
» utilizziamo preferibilmente nella nostra applicazione funzioni di tipo inline di low level;
» è da preferire l’ottimizzazione del codice in velocità rispetto a quelle di spazio. Alcune ottimizzazioni influiscono in maniera determinante sulla quantità dello stack e sul codice prodotto. Ad esempio, alcuni riducono la quantità di stack semplicemente utilizzando direttamente i registri per il passaggio di parametri tra funzioni;
» analizzare l’albero delle chiamate nella nostra applicazione e cercare di determinare un percorso migliore;
» preferire le istruzioni di tipo salto a quelle con ritorno (tecnica però da non preferire);
» fare attenzione alle funzioni. Sicuramente non è molto agevole determinare in maniera analitica l’uso dello stack in applicazioni che utilizzano la ricorsione. A questo proposito, la ricorsione non è un’ottima idea per le applicazioni embedded. Inoltre, a volte può essere utile usare le chiamate indirette a funzioni. Questo uso non risponde propriamente ai requisiti di sicurezza, ma utilizzare le funzioni in questo modo può comportare risparmi considerevoli in fatto di stack;
» non utilizzare le funzioni standard, per esempio printf, perché consumano parecchio stack;
» usare utility in grado di controllare staticamente il codice, come Lint;
» localizzare lo stack all’inizio o alla fine della memoria (dipende dalla crescita dello task) e inserire tutte le variabili nella parte finale della memoria e marcare le zone libere;
» riuscire a determinare il tipo di stack andato in overflow. Infatti, alcuni processori utilizzano differenti stack allocati per usi diversi. Ad esempio, alcuni RTOS utilizzano, oltre a uno stack generale, anche uno stack per ogni processo;
» infine, particolare attenzione va posta nella scrittura e nell’interfacciamento verso altri linguaggi, per esempio l’assembler. Occorre controllare le strutture dati utilizzate e la sequenza di store/restore nello stack.
Stack checking con ARM e Keil
Il controllo dello stack passa attraverso diverse vie. Oltre a sfruttare le prerogative di un compilatore, esiste la possibilità di utilizzare altri tipi di controlli. Ad esempio, con ARM, Keil offre un’interessante applicazione: l’uso di una cross factory insieme ai servizi di un RTOS (RTX kernel, vedi figura 4).
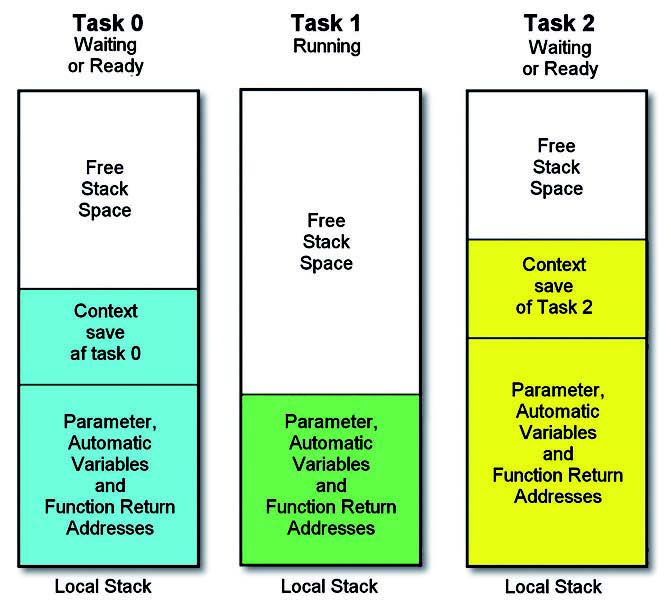
Figura 4: stack per task.
Può succedere che in un’applicazione lo stack sia riempito a causa di chiamate ricorsive a funzioni o a uso eccessivo di variabili automatiche. In Keil è possibile abilitare la funzione “Stack Checking”, in questo caso il kernel monitora gli accessi allo stack e, a condizione avvenuta, esegue una funzione dedicata, os_stk_overflow. In Keil per abilitare questo meccanismo, occorre abilitare la definizione di OS_STKCHECK. È chiaro che con questa funzionalità le prestazioni del sistema ne risentono perché il kernel ha la necessità di eseguire codice addizionale per controllare lo stato dello stack. Il tool di Keil ci viene in aiuto, la figura 5 mostra la finestra dei task attivi e con il campo “stack load” ci informa della quantità di stack utilizzato per ogni task.
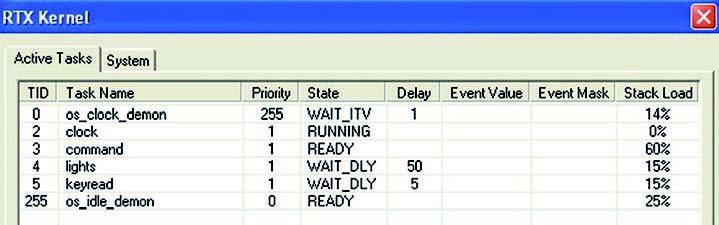
Figura 5: RTX kernel.
In questo ambiente operativo, spesso per risolvere un problema sullo stack basta aumentare la quantità di memoria riservata a ogni task. A questo proposito si ricorre alla ridefinizione della costante OS_STKSIZE. Per trattare tutto il contesto di un processo, sono richiesti 64 byte. Infatti, la definizione:
#define OS_STKSIZE 100
permette di riservare a ogni task una quantità di 400 byte. In keil è anche possibile aumentare il valore dello stack di un singolo task: questa funzionalità è svolta in fase di creazione del task stesso. Così, in RTX:
OS_TID tsk1,tsk2;
static U64 stk2[400/8];
tsk2 = os_tsk_create_user (task2, 1,
&stk2, sizeof(stk2));
Controlli con GCC
Come abbiamo visto in precedenza, esistono differenti tecniche per controllare la corruzione dello stack. Ad esempio, c’è chi utilizza un timer; infatti, dopo aver armato un timer a un periodo prefissato e riempito lo stack di valori conosciuti (per esempio, 0x5A5A5A5A), a ogni occorrenza dell’interrupt del timer, una funzione software si preoccupa di controllare la presenza del pattern confrontandoli con i limiti dello stack. Con GCC diventa superfluo definire delle routine particolari per controllare lo stack, ma basta fare ricorso alla tecnica Stack-Smashing Protector. La tecnica Stack Smashing è il meccanismo di protezione utilizzato da GCC per rilevare situazioni di stack overflow. Il listato 2 mette in evidenza della possibilità, a fronte di una stringa in ingresso maggiore del valore 10, di provocare una corruzione dello stack.
#include <stdio.h>
void func()
{
char array[10];
gets(array);
}
int main(int argc, char **argv)
{
func();
}
| Listato 2 – Stack smashing |
In questo caso, GCC inserisce un valore, chiamato canary, che ha la funzione di proteggere lo stack. È possibile poi disabilitare la protezione utilizzando l’opzione in fase di compilazione:fno-stack-protector. La soluzione di questo tipo è anche chiamata StackGuard e presenta una soluzione di tipo sistematica al problema. StackGuard prende l’avvio con il progetto Immunix e si presenta come una semplice estensione del compilatore in grado di limitare i danni di un attacco da buffer overflow. Le modalità operative utilizzano una tecnica di compilazione che assicura l’integrità dell’area di memoria contenente l’indirizzo di ritorno del record d’attivazione della funzione. StackGuard si presenta come una piccola patch da applicare a gcc, che aggiunge del codice specifico al prologo e all’epilogo di ogni funzione. Il codice aggiuntivo, inserito nel prologo, piazza una canary word vicino all’indirizzo di ritorno nello stack. Il codice inserito nell’epilogo verifica che la canary word sia intatta, prima di saltare all’indirizzo di memoria a cui punta l’indirizzo di ritorno della funzione. La canary word può essere un semplice numero casuale di 32 bit scelto al run-time. Per ottenere questo particolare controllo si deve prelevare la patch ed eseguire la procedura mostrata nel listato 3: in questo modo si installa correttamente nel nostro ambiente di lavoro.
Ipotizziamo di voler proteggere la versione 3.4 di GCC nella cartella /usr/app: a. preleviamo la versione 3.4.4 di GCC dal sito ufficiale b. utilizziamo il comado tar: tar zxf gcc-3.4.4.tar.gz; cd gcc-3.4.4 c. tar zxf protector-3.4.4-1.tar.gz d. applichiamo la patch: patch -p0 < gcc_3_4_4.dif e. mkdir obj; cd obj f. ../configure —prefix=/usr/pp g. If you want to enable the stack protection as defaults, ../configure —prefix=/usr/pp —enable-stack-protector make bootstrap; make install prefix=/usr/pp add /usr/pp/bin in the beginning of the PATH environment
| Listato 3 – Patch per StackGuard |
Questa non è l’unica possibilità offerta in GCC; infatti, il compilatore dispone di altri innumerevoli controlli sullo stack. Accanto a quelle proprie dell’ambiente di lavoro, esiste anche la possibilità di utilizzare funzionalità proprie di un processore, quali AVR o ARM. La tabella 1 mostra le diverse opzioni che il compilatore è in grado di garantire per un processore ARM.

Tabella 1 – Stack con GCC su ARM
Nella maggior parte dei casi, il GCC non esegue controlli di stack overflow se non espressamente richiesto. Ciò comporta, in caso di corruzione dello stack, dei comportamenti anomali da parte dell’applicazione di difficile individuazione. Nell’ambiente GCC, per attivare i controlli sullo stack è necessario utilizzare l’opzione --fstack-check., così:
gcc –c -fstack-check esempio.c
In questo modo si chiede a GCC di generare codice supplementare al fine di controllare lo stack. L’uso dello switchfstack-check comporta diverse operazioni a seconda della presenza di particolari macro all’interno dell’ambiente, ad esempio:
» se il valore della macro STACK_CHECK_BUILTIN non è zero, al lora il controllo dello stack è fatto attraverso il file di configurazione;
» viceversa, se la macro STACK_CHECK_BUILTIN è uguale a zero e si è definito un patter n chiamato check_stack, allora in GCC il controllo è svolto utilizzando questo pattern;
» se nessuna delle due condizioni sopra esposte è vera, allora il controllo dello stack è svolto utilizzando uno dei valori delle seguenti macro in expr.h (listato 4):
STACK_CHECK_PROBE_INTERVAL,
ST ACK_CHECK_PROBE_LOAD,
STACK_CHECK_PROTECT,STACK_CHEC
K _ M A X _ F R A M E _ S I Z E ,
STACK_CHECK_FIXED_FRAME_SIZE,
STACK_CHECK_MAX_VAR_SIZE.
GCC, come abbiamo visto, è estremamente versatile sulle diverse opzioni di compilazione, Ad esempio, per default il compilatore traduce un’istruzione switch del C in una tabella di salti (jump table).
/* Supply a default definition of STACK_SAVEAREA_MODE for emit_stack_save. Normally move_insn, so Pmode stack pointer. */ #ifndef STACK_SAVEAREA_MODE #define STACK_SAVEAREA_MODE(LEVEL) Pmode #endif /* Supply a default definition of STACK_SIZE_MODE for allocate_dynamic_stack_space. Normally PLUS/MINUS, so word_mode. */ #ifndef STACK_SIZE_MODE #define STACK_SIZE_MODE word_mode #endif /* Provide default values for the macros controlling stack checking. */ #ifndef STACK_CHECK_BUILTIN #define STACK_CHECK_BUILTIN 0 #endif /* The default interval is one page. */ #ifndef STACK_CHECK_PROBE_INTERVAL #define STACK_CHECK_PROBE_INTERVAL 4096 #endif /* The default is to do a store into the stack. */ #ifndef STACK_CHECK_PROBE_LOAD #define STACK_CHECK_PROBE_LOAD 0 #endif /* This value is arbitrary, but should be sufficient for most machines. */ #ifndef STACK_CHECK_PROTECT #define STACK_CHECK_PROTECT (75 * UNITS_PER_WORD) #endif /* Make the maximum frame size be the largest we can and still only need one probe per function. */ #ifndef STACK_CHECK_MAX_FRAME_SIZE #define STACK_CHECK_MAX_FRAME_SIZE \ (STACK_CHECK_PROBE_INTERVAL - UNITS_PER_WORD) #endif
| Listato 4 – expr.h, estratto |
Ora, è possibile scegliere una differente implementazione intervendeno sullo switch -fno-jump-tables. Inoltre, alcune versioni di GCC utilizzano per default la protezione sullo stack, in questo caso per disabilitare questa interessante prerogativa basta intervenire con l’opzione -fno-stack-protector. L’algoritmo implementato da GCC per la protezione dello stack è molto semplice come possiamo vedere da un esempio concreto. All’avvio dell’applicazione, l’ambiente di run-time sceglie un valore da assegnare a canary. Il valore è inserito in una locazione particolare, 0x14, dall’inizio del segmento GS. Quando una funzione utilizza delle variabili o strutture dati che vanno a finire nello stack, il compilatore ne abilita la protezione. Aggiunge, cioè, un codice all’inizio della funzione. Il listato 5 mostra un esempio con Intel 0x86. Viceversa, il listato 6 presenta la situazione prima del ritorno: è necessario verificare che il valore non sia stato modificato in operazioni precedenti. In caso affermativo è invocata la funzione stack_chk_fail. che è parte della libreria di sistema. Un controllo di questo tipo introduce overhead nel sistema e penalizza le sue prestazioni. In realtà, un costo bisogna pur pagarlo per evitare problemi di stack overflow.
804a654: 65 a1 14 00 00 00 mov eax,gs:0x14 804a65a: 89 45 ec mov DWORD PTR [ebp-0x4],eax 804a65d: 31 c0 xor eax,eax
| Listato 5 – Inizio della funzione |
804aec0: 8b 45 fc mov eax,DWORD PTR [ebp-0x4]
804aec3: 65 33 05 14 00 00 00 xor eax,DWORD PTR gs:0x14
804aeca: 74 05 je 804aed1
804aecc: e8 07 e6 ff ff call 80494d8
<__stack_chk_fail@plt>
804aed1: c9 leave
804aed2: c3 ret
| Listato 6 – Termine della funzione |

