
In molte applicazioni critiche l’efficienza del funzionamento dell’applicazione deve essere garantita, per questo esistono alcune tecniche di diagnostica.
Molte applicazioni di supervisione e controllo mantengono la CPU per lo più inoperosa, a passare il tempo in attesa di eventi esterni, al verificarsi dei quali il microcontrollore si attiva per espletare le funzioni proprie del sistema (la cosiddetta “missione”). Spesso queste applicazioni sono critiche dal punto di vista sicurezza operativa, essendo preposte a gestire situazioni di emergenza per cose o persone o comunque anomalie rispetto allo stato di riposo. È quindi auspicabile prendere tutte le precauzioni volte a garantire che l’apparecchiatura sia efficiente nella più o meno remota occorrenza in cui il suo intervento sia richiesto. E’ ad esempio il caso degli Airbag montati sulle moderne autovetture, protezioni da sovracorrenti di impianti elettrici, più banalmente antifurti e sistemi di controllo degli accessi. È possibile impiegare il tempo della CPU in funzioni di autodiagnostica che aumentino la confidenza del funzionamento dell’applicazione, apparentemente silente.
Le capacità di autodiagnostica possono essere coadiuvate e rese più sofisticate con l’aggiunta di componenti dedicati, aumentando però costo e complessità del sistema. Il bilancio ottimale va cercato caso per caso, come sempre, pesando sicurezza di funzionamento verso costo, complessità e consumi. Molte possono essere le cause di interferenza con il funzionamento dell’applicazione tali da pregiudicare la missione affidata. Possiamo considerare guasti veri e propri della circuiteria di controllo o dei sensori ad essa collegati, oppure potremmo subire cause esterne temporanee, quali disturbi elettromagnetici di eccezionale intensità. In ogni caso, la tempestiva segnalazione del guasto o meglio, il ripristino automatico sono certamente desiderabili. Prendiamo in esame nel seguito varie sezioni di una tipica applicazione a microprocessore, analizzando alcuni dei possibili accorgimenti. Alcune precauzioni si possono prendere già nel processo di selezione del microprocessore da usare. Preferiremo quindi componenti dotati di interrupt su codice operativo illegale e magari supervisione del corretto funzionamento dell’oscillatore di clock, con commutazione automatica su un oscillatore secondario. Questo consente al micro di mantenere il controllo del sistema e portarlo in una condizione di sicurezza. Particolare cura va naturalmente riservata all’affidabilità e disponibilità dell’alimentazione. L’argomento, molto vasto, viene lasciato ad un futuro articolo.
CPU
L’argomento “verifica della corretta funzionalità della CPU e dell’esecuzione del codice” potrebbe essere molto vasto, andando da precauzioni hardware (watchdog) fino allo stile di codifica (tecniche di “programmazione difensiva”). Per quest’ultime ci limiteremo qui a sottolineare quanto sia opportuno un controllo dell’integrità dei dati distribuito in tutto il programma. A spese di un po’ di velocità di esecuzione e spazio di memoria, verificare che i dati passati ad ogni funzione siano nei range attesi è certo un buon investimento. La protezione classica contro la perdita del corretto flusso di esecuzione (corruzione del Program Counter) è costituita da un circuito monostabile, tipicamente in grado di generare un reset, periodicamente confermato in modo che non raggiunga mai il timeout e quindi non intervenga a reinizializzare l’esecuzione del programma. Questa protezione viene denominata ‘watchdog’ (cane da guardia). Praticamente tutti i moderni microcontrollori integrano questo circuito, offrendo anche vari modi “protetti” per impedirne una disabilitazione involontaria, in seguito ad errore software o programma fuori controllo. Alcuni semplicemente non prevedono la possibilità di disabilitare il watchdog una volta attivato, altri componenti usano sequenze complesse di attivazione/disattivazione, in modo da rendere minimo il rischio di operazione involontaria. In applicazioni sofisticate, quando si voglia una sicurezza ancora maggiore circa il fatto che il watchdog non sia disattivabile per errore, si può ignorare il circuito interno e realizzare esternamente la funzione. Si potrà ricorrere ad un semplice monostabile retriggerabile fino ad usare un piccolo microcontrollore, incaricato di inviare periodicamente un interrupt non mascherabile alla CPU principale, fornire una stringa di dati, attendere la risposta della CPU ed intervenire qualora la stringa di ritorno, calcolata in base ad un algoritmo definito, risulti non corretta. Il principio di base del watchdog è applicabile non solo a CPU. In apparecchiature realizzate su più schede, le singole schede output, ad esempio, possono avere un proprio watchdog locale. Se scade il timeout a causa dell’assenza del rinfresco periodico da parte della CPU di sistema, le uscite potrebbero essere portate in una condizione di riposo, impedendo di propagare gli effetti di guasti.
MEMORIA CODICE
L’integrità della memoria contenente il codice da eseguire è evidentemente fondamentale. Il suo controllo via software può essere eseguito registrando nella memoria non volatile un codice di controllo, ottenuto applicando al contenuto di memoria un algoritmo più o meno sofisticato. La soluzione più semplice è la cosiddetta ‘checksum’, ottenuta semplicemente sommando tutte le word della memoria programma, trascurando il riporto. L’algoritmo è semplice e veloce ma ha lo svantaggio di una limitata capacità nel rilevare errori multipli (più di un bit alterato). Algoritmi più sofisticati rimediano a tale limitazione a prezzo di maggior complessità e tempo di esecuzione. Tra questi troviamo i CRC (codici a ridondanza ciclica), algoritmi che calcolano il quoziente tra due polinomi. Il polinomio dividendo è l’intero contenuto di memoria codice, considerato come un unico lungo numero binario. Il divisore è fisso, definito dal tipo di CRC scelto. L’errore residuo non rilevabile dipende dalla lunghezza del codice adottato. Ad esempio, un CRC16 applicato ad un blocco di dati limitato può avere una copertura del 99.998% contro un 99,29% del semplice checksum (vedi Rif 1 e 2 e le bibliografie in essi contenute).
MEMORIE NON VOLATILI
Le memorie non volatili, FLASH in particolare, presentano registri di stato che segnalano il completamento dell’operazione di modifica avviato, ad esempio la cancellazione di un banco FLASH. In condizioni normali, questo assicura che, nel caso preso ad esempio, le soglie elettriche di tutte le celle FLASH appartenenti al banco sono state riportate ad un valore tale da essere lette come ‘1’ senza alcuna incertezza in tutto il range operativo definito dalla specifica della memoria. Tale meccanismo potrebbe essere inefficace in presenza di reset o cadute di tensione durante l’operazione di modifica. Al ripristino delle condizioni di funzionamento corrette, i registri di stato potrebbero restituire ‘operazione completata’ mentre le soglie elettriche delle celle di memoria potrebbero invece ancora trovarsi in condizioni intermedie tra cella scritta a ‘0’ e cella completamente cancellata, causando perdita di affidabilità delle operazioni sulla memoria interessata. È possibile, anche se non semplice, cautelarsi da tali eventualità implementando un proprio registro di stato (“user”), ad esempio in un altro banco di FLASH, scritto all’inizio dell’operazione di cancellazione con un codice improbabile (evitare ‘0000’ o ‘FFFF’). Il codice andrebbe sovrascritto in accordo con il registro di stato hardware della FLASH solo al termine dell’operazione di modifica. L’interruzione di alimentazione provocherebbe il rilevamento di un codice “modifica FLASH in corso” al controllo del proprio “registro di stato” eseguito durante la seguente inizializzazione del micro, rendendo conto del problema intercorso e consentendo di rilanciare la procedura non completata. La complessità nasce quando si voglia ottenere affidabilità` molto spinta. Cosa accade ad esempio, se si verificano cadute di tensione o reset durante la scrittura del registro di stato “user”? Qualsiasi anomalia del genere andrebbe prevista e gestita.
ADC
Molte precauzioni possono essere prese per verificare il corretto funzionamento di un convertitore ADC e rendere più affidabile il dato. Le più semplici consistono nel determinare il valore da passare al programma di elaborazione con una conversione multipla, con scarto del minimo e massimo valore e media sugli altri. Naturalmente, questo riduce molto la velocità di conversione (o più esattamente, il tempo richiesto per rendere disponibile ogni misura). Anche il confronto con limiti predefiniti aiuta a discriminare false conversioni dovute ad esempio a rumore elettrico. Se stiamo misurando la temperatura di un forno, difficilmente un valore prossimo a zero si potrà considerare realistico. Anche il confronto con l’ultimo valore acquisito o con una media di alcuni valori, può essere significativo. In questo modo sfruttiamo la conoscenza del processo sotto controllo per definire una velocità di variazione massima della grandezza sotto osservazione. Con un po’ di hardware aggiuntivo si può anche verificare il corretto funzionamento della circuiteria del convertitore. Una tensione di valore noto con precisione, relativamente indipendente dalla tensione di alimentazione, può essere periodicamente letta e confrontata con il valore atteso. La tensione può essere ricavata ad esempio da un riferimento di tensione a band-gap (soluzione molto stabile e precisa ma costosa) o da uno zener con basso coefficiente di deriva con la temperatura. Periodiche conversioni di un ingresso tenuto a massa ed al positivo di alimentazione possono costituire un’alternativa a basso costo, consentendo anche la correzione di offset ed errore di guadagno (difficilmente questo è necessario con componenti moderni). Funzioni di self-check ed autocalibrazione sono spesso rese disponibili dai componenti più recenti.
I/O DIGITALI
Una prima precauzione nella gestione delle porte digitali consiste nella periodica conferma dei registri di configurazione (direzione, pull-up o pull-down eccetera). Questa operazione è tipicamente eseguita durante l’inizializzazione del programma ma ripeterla periodicamente aiuta il mantenimento della consistenza del sistema. Occorre accertarsi che la riconfigurazione non crei glitch di tensione sui pin del microprocessore, glitch che potrebbero essere erroneamente interpretati come segnali validi dalla circuiteria esterna. Anche nel caso degli ingressi digitali una sorta di filtro, realizzato con letture multiple, si rivela utile. L’acquisizione dello stato logico viene confermata solo dopo che un certo numero di letture dello stesso input restituisce il medesimo valore, confermando l’assenza di transitori e rumore. È anche consigliabile, anche se costosa, una conferma intrinseca della consistenza dell’informazione in ingresso. Ad esempio, anziché leggere lo stato di un contatto elettromeccanico con un solo ingresso è possibile usare un contatto in deviazione e leggere lo stato di entrambi i rami, vedi figura 1. Naturalmente, il software deve essere abbastanza sofisticato da gestire le commutazioni, discriminando tra manovra in corso e guasto, quest’ultimo riconoscibile dalla lettura stabile di una condizione illegale (ad esempio 00 nel caso in figura 1). Analogamente, la rilettura dello stato delle uscite è utile come self-check, con le precauzioni opportune quando la circuiteria esterna possa indurre in errore, caso che potrebbe presentarsi ad esempio nel pilotaggio della base di un transistor bipolare. Il livello ‘1’ potrebbe non essere riletto correttamente, anche in presenza di pilotaggio elettricamente corretto. In qualche caso si può implementare un controllo dell’alimentazione di potenza degli attuatori con un meccanismo simile al watchdog, già introdotto. Un segnale di consenso all’erogazione dell’alimentazione potrebbe essere ottenuto filtrando un segnale periodico provenente dal micro. La sua scomparsa può essere sintomo della perdita di controllo e quindi della necessità di mettersi in una condizione di default.
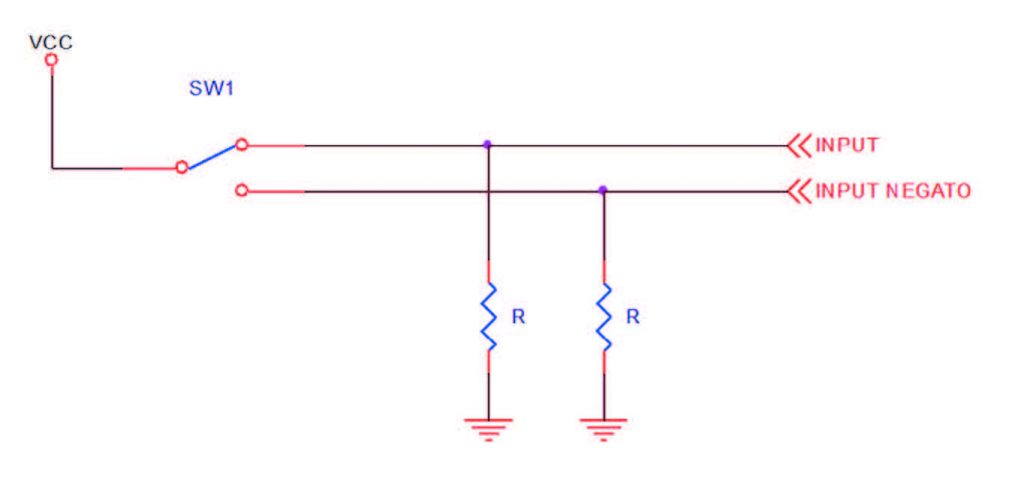
Figura 1: acquisizione di un ingresso digitale con verifica.
SOLUZIONI AVANZATE
Tecniche sofisticate di ridondanza delle unità di calcolo sono state sviluppate per applicazioni spaziali ed avionica. Esse consentono la rilevazione di errori ed eventualmente la prosecuzione delle operazioni grazie a sistemi con esecuzione parallela e decisione a maggioranza in presenza di dati non omogenei. Il progresso nell’integrazione rende ora possibile diffondere tali tecnologie anche dove all’esigenza di sicurezza operativa, deve essere associato un basso costo. Iniziano ad essere disponibili componenti che integrano due CPU identiche, capaci di eseguire lo stesso codice in parallelo e segnalare eventuali discrepanze affinché il sistema si porti in condizioni di sicurezza. Le routine di autodiagnostica possono essere eseguite all’interno del loop di programma principale o nella task di default di un sistema multitasking. Naturalmente, occorre accertarsi che le analisi siano completate entro un tempo ragionevole e compatibile con il livello di protezione desiderato.

Articolo estremamente interessante. Penso che ormai tutti i dispositivi esistenti dispongono di sistemi di auto-diagnostica. Alcuni sono realizzati utilizzando lo spesso processore, in pratica è la stessa CPU o MCU che si auto-controlla. I sistemi più costosi, invece, prevedono delle CPU esterne. Alcuni metodi utilizzano addirittura Internet, come veicolo di scambio di test e misure a ogni intervallo di tempo. Sarà poi il server centrale a controllare la bontà del sistema e a fornire soluzioni, in tempo reale.
Le tecniche di autodiagnostica sono diventate parte integrante dei moderni dispositivi. E’ necessario poter quantificare la reliability di un sistema e fare delle analisi sul tasso di guasto considerando anche il Mean Time Between Failures, ovvero il tempo che intercorre tra due guasti successivi.
L’idea che un sistema elettronico riesca a controllare se stesso è certamente molto interessante e sicuramente rassicurante per chi usa il sistema. Il fatto che poi questi sistemi di controllo siano addirittura integrati all’interno di una CPU ci fa anche pensare come essi abbiano decisamente un punto di accesso preferenziale rispetto a quello che un tecnico può fare dall’esterno..
Sarebbe interessante conoscere anche quali siano gli sviluppi del settore in termini di procedure di recupero. Mi aspetto nel breve termine grandi passi avanti in questo settore. Nel caso del watchdog ad esempio, esso si occupa di effettuare un reset, ma si potrebbe pensare ad un software evoluto in grado di stabilire quali flussi del codice hanno impedito l’aggiornamento del contatore del watchdog e prendere eventuali contromisure per evitare che ciò riaccada.
Un sistema che protegge da se stesso l’ambiente con cui vi interagisce. La progettazione delle tecniche volte ad intercettare o addirittura a predire prima che accadano malfunzionamenti del sistema arrecanti potenziali danni agli utilizzatori finali, credo rappresenti un settore aziendale su cui un’impresa che mette in produzione tali sistemi deve investire tanto e in maniera continua. La tecnologia avanza e con essa anche la complessità dei sistemi. Faccio fatica a pensare che la gestione dei percorsi critici che possono portare ad instabilità del sistema siano lasciati a un RTOS o comunque a routine software ad alto livello. Tanto è vero che questi automatismi di protezione non di rado sono implementati direttamente tramite accorgimenti hardware o integrati negli stessi processori. Il CTRL+ALT+CANC non esiste per un’auto con servo freno elettronico. Detto ciò, mi immagino che a breve vedremo affiancati, alle protezioni hardware, degli algoritmi di machine learning e di AI (con possibili invii di dati ad un server elaboratore tramite connessione mobile e veloce tipo 5G) aventi la funzione di predire quanto non si sia ancora verificato e di mettere il sistema in uno stato di arresto preventivo evitando l’insorgere del pericolo.