
Da un po' di tempo, l'aggettivo "semantico" viene utilizzato sempre più spesso in ambito informatico, principalmente per definire una particolare tipologia di motori di ricerca più evoluti ed efficienti. In questo articolo, provo a spiegare in maniera sufficientemente chiara ed esaustiva cosa sono il web semantico e i motori di ricerca semantici; inoltre, illustro una mia personale idea su come se ne potrebbe realizzare uno.
Introduzione
Un motore di ricerca è un sistema informatico che consente di effettuare ricerche di pagine web digitando uno o più termini che descrivano ciò che si sta cercando. Comunicando al motore di ricerca tali termini, esso restituisce in tempo reale un elenco completo di tutte le pagine contenenti i vocaboli specificati.
Il lavoro dei motori di ricerca si divide principalmente in tre fasi:
- analisi del web effettuata tramite particolari software chiamati crawler (o spider o robot) che scandagliano il web e inseriscono i documenti trovati all’interno del database del motore di ricerca (indicizzazione);
- catalogazione del materiale ottenuto mediante l’utilizzo di opportune parole chiave (keyword);
- risposta alle richieste dell'utente, che avviene cercando nel database quei documenti che contengono le keyword inserite dall'utente ed elencando i siti trovati in ordine di rilevanza rispetto alla richiesta ricevuta.
Ogni motore di ricerca sfrutta propri algoritmi per classificare le pagine, controllando, per esempio, quante volte le parole chiave vengono ripetute, quanti link riceve quel documento, in quali punti della pagina sono poste le keyword, quanti siti del database contengono link verso quella pagina, o quante volte un utente ha visitato quel sito.
I motori di ricerca semantici
Gli attuali motori di ricerca vengono definiti sintattici o lessicali, in quanto si limitano a cercare nei siti indicizzati la presenza dei termini digitati dall’utente, senza in alcun modo tentare di determinare il contesto in cui questi termini vengono utilizzati. Invece, un motore di ricerca semantico è un ipotetico motore di ricerca in grado di estrapolare ed interpretare il significato logico di una frase tenendo anche conto del contesto in cui ciascuna parola è collocata. Ad esempio, se l’utente digita una query contenente il termine “lancia”, sta cercando un’automobile o qualche informazione sull’antica arma da lancio? Un motore di ricerca in grado di fare questo rappresenterebbe un vantaggio notevole per chiunque.
La ricerca semantica consentirebbe di semplificare la gestione della conoscenza non strutturata (libri, giornali, documenti, ecc.) che, a differenza dei database (conoscenza strutturata), non è immediatamente accessibile dalle tecnologie informatiche tradizionali. La ricerca semantica tenta infatti di avvicinarsi al meccanismo di apprendimento umano: il lettore non memorizza le singole parole, bensì tenta di sviluppare una "mappa cognitiva" che gli consenta di estrarre il significato di quanto sta leggendo. Quindi i motori di ricerca semantici dovrebbero analizzare il testo in maniera molto simile a quanto fanno le persone, interpretando il significato logico delle frasi e tentando di carpirne il significato dal contesto. In sintesi, con un motore di ricerca semantico si potrebbe trovare tutto, prima e meglio, senza doversi improvvisare maghi delle parole chiave, ma semplicemente domandandolo al computer come se fosse un’altra persona.
Secondo alcuni esperti, oggi non è pensabile un motore di ricerca semantico per tutto il web come Google; ma per alcuni settori, quando il problema non è troppo complesso e ci si limita ad un contesto specifico, sarebbe possibile implementare soluzioni che consentano di ottenere risultati migliori rispetto ai comuni motori di ricerca. In altre parole, prima di tutto occorrerebbe capire quale tipo di conoscenza debba essere gestita: manuali di auto, programmi tv, eccetera. Implementare un motore di ricerca semantico richiederebbe molto lavoro anche per adattarlo ad ogni lingua e cultura. L'aspetto linguistico è assolutamente imprescindibile perché gli stessi oggetti si possono indicare con termini differenti; inoltre, ci sono concetti che non esistono neppure in culture differenti, o che vengono indicati con parole diverse. Se poi ci si esprime per metafore, diventa tutto ancor più complicato.
Secondo altri esperti, l’interpretazione semantica delle query, poiché necessita sempre di una contestualizzazione nel dominio specifico, non rappresenterebbe la soluzione più economica per incrementare l’efficienza dei motori di ricerca. Per tale motivo, si stanno sviluppando anche tecnologie capaci di dare un supporto attivo alla ricerca senza dover ricorrere alla semantica. Ad esempio, esistono motori di ricerca che strutturano i risultati creando delle categorie tematiche, come per esempio Clusty (www.clusty.com).
Esistono diversi motori di ricerca che vengono spacciati per semantici, ciascuno dei quali andrebbe esaminato per verificare quanto effettivamente sia tale. Alcuni, come Accoona (www.accoona.eu) e Ask Jeeves (uk.ask.com), sembra si siano rivelati totalmente farlocchi.
Il più famoso tra i presunti motori semantici probabilmente è BING (www.bing.com) della Microsoft, nato nel 2009, anche se non tutti sono concordi nel definirlo semantico. Il più efficiente invece sembra essere WolframAlpha (www.wolframalpha.com), che è in grado di proporre direttamente delle risposte a domande (in inglese) inerenti principalmente argomenti scientifici invece che offrire una lista di collegamenti ad altri siti web. E’ inoltre in grado di elaborare input in linguaggio matematico oltre che in linguaggio naturale (ovvero possiede anche le funzionalità di una calcolatrice scientifica); ad esempio, digitando una funzione otteniamo come output il suo grafico con i relativi zeri.
Presumibilmente, esisteranno motori perfettamente semantici solo quando l’intelligenza artificiale dei computer eguaglierà quella umana.
Il web semantico
Parlando di motori semantici, è inevitabile imbattersi nel concetto di web semantico. Prima di definirlo, cominciamo col dire che il web semantico ed i motori di ricerca semantici non sono la stessa cosa, sebbene il primo faciliti il compito dei secondi strutturando semanticamente la “conoscenza” del web.
Tim Berners-Lee, l’inventore del world wide web, coniò il termine web semantico (o web 3.0) per descrivere una auspicabile evoluzione del web verso un ambiente dove i documenti pubblicati (pagine HTML, file, immagini, e così via) siano associati a dati (metadati) che ne specifichino il contesto semantico in un formato adatto all'interrogazione, all'interpretazione e, più in generale, all'elaborazione automatica.
L'evoluzione del web in web semantico inizia con la definizione, da parte del W3C (l'organizzazione internazionale, di cui è presidente Berners-Lee, nata nel 1994 con l'obiettivo di portare il web alle sue massime potenzialità), dello standard RDF (Resource Description Framework), una particolare variante del linguaggio di marcatura XML che standardizza la definizione di relazioni tra informazioni ispirandosi ai principi della logica dei predicati (o logica predicativa del primo ordine) e ricorrendo agli strumenti tipici del web, come ad esempio l’URI (Uniform Resource Identifier), una stringa che identifica una risorsa nel web (un documento, un'immagine, un file, un indirizzo e-mail, ecc.) in maniera univoca.
In estrema sintesi, secondo la logica dei predicati, le informazioni sono esprimibili con asserzioni costituite da triple formate da soggetto, predicato e valore (complemento). Ad esempio, le seguenti affermazioni sull’ex Presidente della Repubblica Ciampi:
- “Il Signor Ciampi vive a Roma.”
- “Il Signor Ciampi ha codice fiscale CMPCLZ20T09E625V.”
possono essere schematicamente scomposte tramite la seguente tabella:

Per alcuni di questi elementi è possibile reperire sul web degli URI che li possano identificare univocamente, quali ad esempio:
- "Il Signor Ciampi": http://www.quirinale.it/ex_presidenti/Ciampi/ciampi.htm
- "vive a": http://it.wiktionary.org/wiki/vivere
- "Roma": http://www.comune.roma.it/index.asp
- "ha codice fiscale": http://it.wikipedia.org/wiki/codice_fiscale
La logica predicativa del primo ordine è estremamente complessa e l’RDF ne può esprimere solamente una porzione molto ristretta. Per questo motivo, è stato formulato un nuovo standard più ricco ed espressivo dell’RDF: l'OWL (Ontology Web Language), un linguaggio di marcatura col quale poter rappresentare esplicitamente il significato dei termini tramite vocabolari e relazioni tra i vocaboli. Tale rappresentazione dei termini e delle relative relazioni costituisce quella che si definisce un'ontologia.
In informatica, col termine ontologia (che proviene dalla filosofia e, in greco, significa “studio dell’essere”) si indica uno schema concettuale esaustivo e rigoroso nell'ambito di un dato dominio, che consiste generalmente in una struttura dati gerarchica contenente tutte le entità rilevanti, le relazioni esistenti fra di esse, le regole, gli assiomi ed i vincoli specifici del dominio. Un'ontologia che non sia legata ad un particolare dominio di applicazione, ma cerchi di descrivere entità più generali, si definisce ontologia costitutiva oppure ontologia superiore.
L'obiettivo è permettere a dei software di elaborare il contenuto delle informazioni dei documenti scritti in OWL. Su tali documenti, ossia le ontologie, si può eseguire un vero e proprio ragionamento deduttivo inferenziale (l'inferenza è quel processo con il quale da una proposizione ritenuta vera si passa ad una proposizione la cui verità è contenuta nella prima) tramite particolari software chiamati ragionatori automatici.
Volendo ricapitolare molto sinteticamente quanto detto finora, si potrebbe dire che, per realizzare un motore di ricerca semantico supportato dal web semantico, occorrerebbe “semantizzare” il web mappandolo su delle ontologie, ovvero documenti scritti in OWL, e dotare il motore di ricerca di un ragionatore automatico con cui poter usufruire di tali ontologie per essere in grado di esaminare il web semanticamente. Uno schema che illustri il funzionamento di un tale motore di ricerca potrebbe essere il seguente:
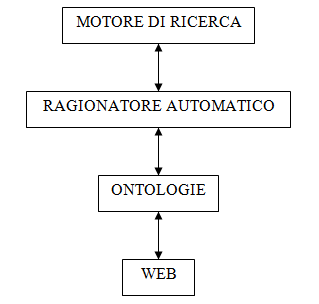
Diverse aziende e università hanno aperto numerosi programmi di ricerca legati a questi temi. Una cosa già possibile e praticata è la creazione di molte ontologie, ciascuna limitata ad un dominio ben preciso. Tuttavia è facile esprimere una critica alla effettiva validità di questo ambizioso progetto che è il web semantico. Quanto tempo servirebbe per mappare tutto il web su delle ontologie? Inoltre, quand’anche ciò fosse fatto, come far comunicare fra loro ontologie diverse? E’ infatti evidente che una ontologia avrà validità solo per il dominio per il quale è stata progettata.
Pensare al web come ad un’infrastruttura regolata nel suo complesso da una struttura semantica significa disegnare una prospettiva incerta, quantomeno nel medio periodo. Diverso è il discorso se parliamo dell'uso di schemi semantici all'interno di architetture legate ad un dominio ben definito, quindi a servizio di comunità ristrette di utenti, orientati ad uno scopo preciso. Qui le prospettive immediate sono visibili più chiaramente. Per esempio, col web semantico si potrebbe risolvere un tema finora solo parzialmente soddisfatto dagli attuali strumenti informatici: la gestione della conoscenza aziendale, ovvero la capacità non solo di trattare le diverse anagrafiche (di prodotto, clienti, fornitori, dipendenti, ecc.) e di classificare i documenti tecnici o amministrativi (analisi di mercato, specifiche tecniche, norme, procedure, ecc.), ma di arrivare anche a gestire i contenuti di questi documenti permettendo, ad esempio, il reperimento delle informazioni in funzione delle specifiche esigenze del richiedente, integrando quanto reso disponibile da fonti diverse.
La (mia) teoria dei codici semantici
Ora vorrei esporre la mia personale idea su come si potrebbe realizzare un motore semantico. Consideriamo le seguenti tre locuzioni:
- “Il volume di un cubo (di una sfera, di un cono, ecc.)”;
- “Il volume di un televisore (di una radio, di uno stereo, ecc.)”;
- “Il volume di una biblioteca (di una libreria, di un’enciclopedia, ecc.)”.
Esse contengono tutte la parola “volume” che notoriamente ha più di un significato. Ciascuna di esse ha un senso differente dalle altre che è determinato dal significato del termine “volume” all’interno di essa. Da cosa si evince l’accezione di un vocabolo avente più significati all’interno di una frase e conseguentemente della frase stessa? Ovviamente dal contesto in cui esso è presente, ovvero dall’abbinamento della parola con gli altri termini presenti nella frase. Tali termini (tutti o solo alcuni di essi) individuano una classe di vocaboli che rappresenta una certa area semantica alla quale apparterrà anche la parola che stiamo considerando. Questo discorso può essere schematizzato dal seguente disegno:
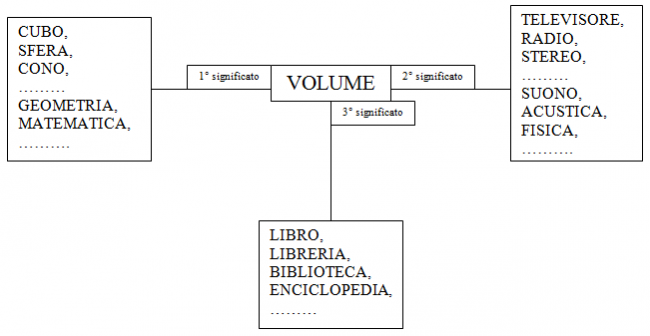
Quindi il problema è come far capire ad un motore di ricerca che, se abbiniamo il vocabolo “volume” a termini come “cubo”, “sfera”, ecc., stiamo parlando di geometria e per volume si intende la misura dello spazio occupato da un corpo solido, mentre, se lo accostiamo a parole come “biblioteca”, “enciclopedia”, ecc., esso assume il significato di libro.
Indichiamo con 1 la prima area semantica (cubo, sfera, cono, ecc.), con 2 la seconda (televisore, radio, stereo, ecc.) e con 3 la terza (biblioteca, libro, enciclopedia, ecc.); consideriamo inoltre i seguenti quattro sottoinsiemi di N (l’insieme dei numeri naturali): {1}, {2}, {3}, {1, 2, 3}. Associando a “volume” {1, 2, 3} e a “cubo” {1}, l’argomento (ovvero il dominio semantico) della query “il volume di un cubo” risulterà individuato dall’intersezione dei due sottoinsiemi:
Ovviamente, ciò varrà anche per “Il volume di un televisore” e “Il volume di una biblioteca”:
L’esempio è stato fin troppo semplice e banale ma dovrebbe aver reso l’idea. Ogni vocabolo (esclusi articoli, pronomi, preposizioni e tutti gli altri vocaboli irrilevanti) appartiene ad uno o più domini semantici, a ciascuno dei quali possiamo abbinare un ben preciso codice numerico o alfanumerico che io chiamerei codice semantico. Indichiamo con C l’insieme di tutti questi codici. Ora consideriamo una qualsiasi query contenente n termini rilevanti, a ciascuno dei quali sarà associato un sottoinsieme Ck di C, con k = 1, 2, ..., n. L’intersezione degli n sottoinsiemi Ck
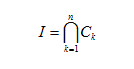
ci fornisce l’argomento della query, a patto che contenga un unico codice semantico (card(I) = 1).
Questa è (molto) a grandi linee l’idea che sviluppai nel 2008 nell’ambito di un progetto dell’azienda informatica presso cui lavoravo a quei tempi, un’idea su cui, a mio avviso, si potrebbe lavorare per sviluppare un algoritmo di ricerca semantica. Per ovvi motivi, ho volutamente omesso diversi dettagli, come, ad esempio, cosa dovrebbe fare l’algoritmo qualora I non contenesse alcun codice o ne contenesse più di uno (card(I) ≠ 1), e come dovrebbe procedere una volta individuato l’argomento della query. Progettai un prototipo di tale algoritmo e anche il database relazionale che lo supporta; purtroppo però, l’azienda interruppe il progetto impedendomi così di realizzare il mio motore di ricerca, o perlomeno di provarci (naturalmente, permangono ancora alcuni problemi da risolvere e molto lavoro da fare prima di arrivare alla realizzazione di un motore di ricerca vero e proprio). È da allora che sono alla ricerca di qualcuno a cui possa interessare la mia idea e mi possa consentire di portare a termine il mio lavoro.
Marco Giancola è autore dell'e-book SATELLITI ARTIFICIALI, un testo, finalizzato alla divulgazione dei principali rudimenti della tecnologia satellitare, che è annoverabile tra i pochi manuali in lingua italiana che trattano argomenti di carattere spaziale.

Si, Giorgio.
Sono perfettamente d’accordo con te.
Da bravo matematico, mi è sembrato che Marco abbia analizzato con scrupolo ogni aspetto della questione fino a gettare completamente tutte le basi utili a sviluppare il concetto.
Sarebbe un po’ come insegnare ad un motore di ricerca a “pensare umano”… 🙂
Io però non ho capito quanto ci siamo vicini e quanto ci è andato vicino l’autore…
A che punto era arrivato Giancola nei suoi studi?
Ci saranno dettagli in un prossimo articolo?
Vorrei aggiungere, all’ottimo articolo di Marco, anche un altro fattore da considerare: la SEO.
Infatti, da ormai molti anni, riuscire ad essere in cima ai motori di ricerca è sinonimo di importanti guadagni e quindi importanti budget vengono spesi per farsi gioco del sistema.
Un algoritmo di un motore di ricerca in grado di difendersi da questi attacchi deve necessariamente contenere una variabile RND
Da studente, ebbi la fortuna di avere tra i miei insegnanti uno dei principali esponenti italiani di intelligenza artificiale e, nello specifico, di linguistica computazionale (perlomeno a detta dei suoi colleghi docenti dell’università “La Sapienza” di Roma).
Se, come immagino, l’aiuto di cui necessiti è principalmente nell’investimento economico, be’, non credo si possa far nulla. Tuttavia, se la cosa può interessarti, potrei introdurti a questo professionista, magari le piace il tuo progetto e ti indirizza verso qualcosa di concreto. Ammesso ovviamente che dopo 10 anni lei si ricordi ancora di me…….
Fammi sapere se sei interessato, in caso ci sentiamo poi in pvt.
Vi ringrazio innanzitutto dei complimenti.
Non è escluso che possa approfondire uno o più aspetti di tale argomento in un prossimo articolo. Tuttavia, per ovvi motivi, ho intenzione di fornire maggiori ragguagli riguardo alla mia idea solo a qualcuno che possa consentirmi di concretizzarla o quantomeno che sia in grado di valutarla e dirmi quanto sia fattibile. L’aiuto di cui necessito ovviamente è anche di tipo economico, e soprattutto per tale motivo (considerando che siamo in Italia e, come se non bastasse, considerando pure l’attuale crisi economica) non nutro grandi speranze (per usare un eufemismo).
Attualmente, motori al 100% semantici non esistono e, come ho scritto, secondo me li avremo solo se e quando l’intelligenza artificiale eguaglierà quella umana (come prospettato da innumerevoli racconti di fantascienza; magari ci vorrano secoli o addirittura millenni ma credo che ciò avverrà). Riguardo ai motori di ricerca che attualmente vengono propinati come semantici, sono un po’ scettico (al massimo, potranno essere parzialmente semantici). A tal proposito, vi suggerirei di provare a testare BING (il famoso motore di ricerca della Microsoft creato dall’ingegnere italiano Lorenzo Thione, esperto di linguistica computazionale) sia con query italiane che inglesi (teoricamente BING dovrebbe essere più semantico in inglese) e poi di provare a fare le stesse ricerche con Google; io l’ho fatto e francamente non ho rilevato una grande differenza nei risultati, e quindi cosa abbia di speciale BING, ovvero perché sarebbe semantico, proprio non l’ho capito. Invece un motore di ricerca veramente portentoso è Wolfram Alpha, almeno per quanto riguarda gli argomenti scientifici e tecnologici; il suo neo è che, almeno per il momento, “parla” solo inglese.
Sì certamente, grazie.