
L’apprendimento macchina (Machine Learning o ML) è finalmente esploso nell'ambito ingegneristico e nelle vite quotidiane delle persone. Questa tecnologia si sta muovendo rapidamente ed oggi non è più ad appannaggio di data center distanti e basati su cloud. Le innovazioni nelle capacità di elaborazione negli algoritmi ML hanno portato le applicazioni e l'inferenza ai bordi (Edge) della rete verso quei dispositivi intelligenti che fino a poco tempo fa servivano solo a catturare i dati. Ma come siamo arrivati a tutto questo? In questo articolo racconteremo in breve i passi nell'evoluzione tecnologica, che hanno portato dalle prime ipotesi di Intelligenza Artificiale verso l'embedded Machine Learning.
Introduzione
L'apprendimento automatico (Machine Learning) rappresenta il più rilevante punto di svolta nell’informatica da una generazione a questa parte. L'apprendimento automatico sta portando progressi enormi nelle tecnologie delle auto connesse, nell’evoluzione dell'assistenza sanitaria e nell’influenzare il modo in cui l'infrastruttura urbana viene controllata. Inoltre, la sua influenza si estende anche a settori meno ovvi come l'agricoltura, dove consente pratiche di irrigazione super efficienti, controllo mirato dei parassiti e delle malattie e l’ottimizzazione dei raccolti. Il suo potenziale è così ampio che è difficile immaginare un settore che non ne sarà influenzato.
I termini Intelligenza Artificiale (AI) e Machine Learning (ML) sono spesso usati in maniera intercambiabile. Tuttavia, nella scienza dei dati, i termini sono distinti:
- AI è un termine generico relativo all'hardware o al software che consente ad una macchina di imitare l’intelligenza umana. Vengono utilizzate una serie di tecniche per fornire "intelligenza" compreso ML, computer vision ed elaborazione del linguaggio naturale (NLP);
- ML è un sottoinsieme di AI, come mostrato nella Figura 1. ML utilizza tecniche statistiche per abilitare i programmi ad "imparare" attraverso l’addestramento, piuttosto che essere programmati con delle regole.
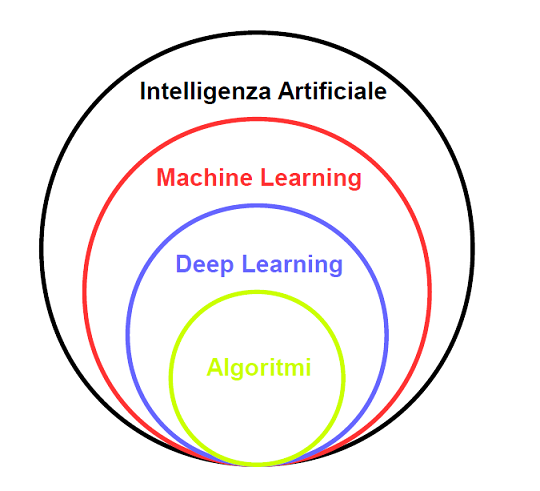
Figura 1: Intelligenza Artificiale e Machine Learning non sono la stessa cosa. ML è un sottoinsieme della grande famiglia dell'AI, mentre il Deep Learning è un sottoinsieme del Machine Learning
I sistemi ML elaborano progressivamente i dati di addestramento per migliorare le prestazioni di un'attività, fornendo risultati che migliorano con l'esperienza.
La storia
Riuscire soltanto a menzionare tutti i passaggi che hanno attraversato la storia dell'apprendimento macchina richiederebbe molto più di un singolo articolo. Per questo motivo nel seguente resoconto storico ci soffermeremo solo sugli eventi e sulle scoperte che maggiormente hanno inciso sull'evoluzione del Machine Learning.
I Pionieri
L'apprendimento automatico è, in parte, basato sul modello di interazione delle cellule cerebrali. Nel 1949 Donald Hebb mostra il modello in un libro intitolato The Organization of Behaviour. Il libro presenta le teorie di Hebb sull'eccitazione dei neuroni e sulla comunicazione tra i neuroni. Traducendo i concetti di Hebb nelle reti neurali artificiali, il suo modello può essere descritto come un modo per alterare i singoli neuroni (chiamati anche nodi) e le relazioni tra essi. La relazione tra due neuroni/nodi si rafforza se i due vengono attivati contemporaneamente e si indebolisce se vengono attivati separatamente. La parola "peso" è usata per descrivere questa relazione.
Nel 1950 Alan Turing (Figura 2), pubblica un articolo dal titolo Computing Machinery and Intelligence. Nell'articolo Turing pone una semplice domanda "le macchine possono pensare ?". Piuttosto che cercare di determinare se una macchina è in grado di pensare, Turing suggerisce le regole ("test di Turing") per definire se una macchina è in grado o meno di simulare l'umano ("gioco dell'imitazione").
Nel 1951 il matematico Marvin Minsky (Figura 2) viene assunto per lavorare al progetto SNARC. La SNARC (Stochastic Neural Analog Reinforcement Calculator) è considerata la prima macchina a rete neurale nel campo dell'Intelligenza Artificiale. Al tempo, però, non esiste ancora la tecnologia per far sì che la macchina possa apprendere in maniera autonoma.
Nel 1952, Arthur Samuel (Figura 2) dell'IBM sviluppa un programma per computer per giocare a dama. Attraverso una funzione di punteggio, basata sulle posizioni dei pezzi sulla scacchiera, si tenta di misurare le possibilità di vittoria di ciascuna parte. Il programma sceglie la mossa successiva da fare utilizzando una strategia minimax, che alla fine si evolverà nell'algoritmo minimax. Samuel progetta anche un meccanismo che consente al programma di migliorare. Denominato apprendimento meccanico, tale meccanismo registra tutte le posizioni già viste e le combina con i valori della funzione di ricompensa. Arthur Samuel utilizza per la prima volta il termine Machine Learning nel 1952.

Figura 2: Partendo da sinistra, nell'ordine Alan Turing, Marvin Minsky, Arthur Samuel
Il Percettrone
Nel 1957, Frank Rosenblatt - presso il Cornell Aeronautical Laboratory - combinando il modello di interazione delle cellule cerebrali di Donald Hebb con gli sforzi di Machine Learning di Arthur Samuel, crea il percettrone. Il percettrone, inizialmente progettato per il riconoscimento delle immagini, è il mattone base delle reti neurali. Esso cerca di simulare il funzionamento del neurone biologico.
La rappresentazione grafica del modello matematico del percettrone viene riportata in Figura 3. Nel caso più semplice l'uscita y può assumere solo uno dei due valori binari per volta. Una funzione di attivazione χ determina l'uscita a seconda del valore della sommatoria dei prodotti tra gli ingressi x e i pesi w. Il bias b rappresenta un valore di soglia che la somma pesata degli input deve superare affinché l'output sia 1. L'apprendimento consiste nel modificare i valori dei pesi e della soglia in modo che, dato un ingresso, l'uscita si avvicini il più possibile ad un valore scelto a priori.
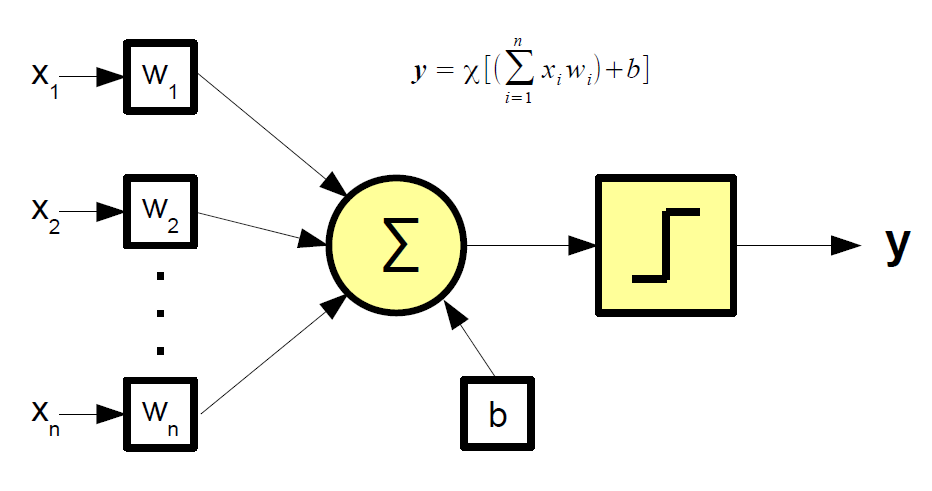
Figura 3: Rappresentazione grafica del modello matematico del percettrone
Mettendo più percettroni insieme, creando in tal modo uno strato (layer) di percettroni, è possibile realizzare attività più complesse rispetto al singolo percettrone. Sebbene tutto questo sembrasse promettente, presentò alcuni limiti, come l'impossibilità di riconoscere molti tipi di schemi visivi (ad esempio i volti), ed infrangendo le aspettative di investitori e ricercatori. Ciò comportò un rallentamento nella ricerca sulle reti neurali/apprendimento automatico per molto tempo, fino ad una rinascita negli anni '90. L'interesse comunque non svanì del tutto. Negli anni '60, l'innovazione del percettrone multistrato rinvigorì l'entusiasmo sulle reti neurali. Si trattava di utilizzare due o più strati per ottenere una potenza di elaborazione significativamente maggiore rispetto ad un solo strato. [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2107 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
La rivoluzione delle reti LoRaWAN nelle applicazioni IoT Industriali (IIoT)
Light Pollution: quali soluzioni?

Renesas RA – Famiglia di microcontrollori basata su ARM Core Cortex-M
GAN: che cos’è una rete generativa avversaria
I microfoni Mems e le loro configurazioni beamforming
