Uno dei compiti principali di un sistema operativo moderno è di garantire equità ai processi. Certe volte nasce l'esigenza di controllare l'uso di risorse per utente, gruppi di utenti, per tipo di applicazione. In questi casi il concetto di processo non è sufficiente per esprimere i requisiti richiesti. Per risolvere questa limitazione Linux, mette a disposizione una infrastruttura denominata cgroups. :
Overview
Uno dei compiti principali di un sistema operativo moderno e` quello di garantire equita` ai processi che si contendono l'uso di risorse.
Spesso viene concessa la possibilita` di definire diversi livelli di utilizzo, tramite priorita` (es. uso della cpu) o limiti spaziali ben definiti (utilizzo massimo di memoria), ma quasi sempre nella teoria dei sistemi operativi si fa riferimento al processo come entita` logica da limitare: priorita` per processo, massimo utilizzo di memoria per processo, etc.
Certe volte nasce l'esigenza di controllare l'uso di risorse per utente, gruppi di utenti, per tipo di applicazione, o addirittura unioni e intersezioni di tali insiemi. In questi casi il concetto di processo non è abbastanza generico
per esprimere i requisiti richiesti.
Per risolvere questa limitazione Linux, dalla versione 2.6.24 (fine 2007), mette a disposizione una infrastruttura denominata cgroups.
I cgroups forniscono gli strumenti necessari per creare gruppi generici di processi. Le regole di classificazione possono essere di qualsiasi tipo, il kernel mette solo a disposizione l'interfaccia per muovere uno o più` PID (Process ID) all'interno di un gruppo generico (cgroup). Oltre a questo l'infrastruttura dei cgroup fornisce un'ABI (Application Binary
Interface) che consente allo sviluppatore kernel di implementare policy di controllo di risorse per gruppo di processi, estendendo il concetto di singolo processo, utente o gruppo UNIX. Tali policy di controllo sono realizzate dai cgroup subsystem.
Alcuni cgroup subsystem per il controllo delle risorse piu` "note" sono gia messi a disposizione nel kernel "vanilla": CPU, memoria, I/O, network.
Esempio pratico
Consideriamo ad esempio l'attivita` che svogliamo tutti i giorni sul nostro desktop Linux: apriamo un client di posta, un browser web, un palyer di musica e un terminale per ricompilare il kernel (beh, forse quest'ultimo non lo facciamo proprio tutti).
Se inavvertitamente proviamo a lanciare un "make -j64" per ricompilare il kernel notiamo subito che il sistema diventa totalmente inutilizzabile: di default lo scheduler di Linux assegna una banda equa di CPU per processo, ma i 64 task paralleli che stanno ricompilando il kernel si prendono di fatto una quota di CPU 64 volte maggiore di quella che si prende il programma di posta (supponendo di usare un client di posta mono-task).
Chiariamo come mai succede cio` con semplice esempio. Prendiamo due applicazioni CPU-intensive, e chiamiamole app1 e app2:
$ ln -s /usr/bin/yes app1 $ ln -s /usr/bin/yes app2
Il programma "yes" stampa ripetutamente il carattere 'y' su standard output, ridirigendo l'output su /dev/null lo fa diventare un ottimo "consumatore" di CPU, molto utile per il nostro semplice test.
Adesso proviamo a lanciare 4 istanze di app1 e una sola istanza di app2 sulla stessa CPU #0:
$ for i in `seq 4`; do schedtool -a 0 -e ./app1 >/dev/null & done $ for i in `seq 1`; do schedtool -a 0 -e ./app2 >/dev/null & done
Dall'output del comando "top" vediamo quanto segue:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5364 righiand 20 0 7164 628 528 R 20 0.0 0:02.13 app1
5363 righiand 20 0 7164 628 528 R 20 0.0 0:02.12 app1
5365 righiand 20 0 7164 628 528 R 20 0.0 0:02.12 app1
5366 righiand 20 0 7164 628 528 R 20 0.0 0:02.12 app1
5368 righiand 20 0 7164 628 528 R 20 0.0 0:00.92 app2
^^^^
Ogni task si prende una quota di CPU del 20%: lo scheduler del kernel garantisce un'ottima equita` per processo. Dal nostro punto di vista pero` la decisione non risulta molto equa: app1 si e` presa il 20% della CPU, mentre app2 si e` presa l'80%.
Uso dei cgroups
Come risolvere il problema descritto sopra in modo semplice e senza entrare nei dettagli implementativi dello scheduler della CPU? Risposta: usando i cgroups.
L'interfaccia di configurazione dei cgroup e` rappresentata da un virtual filesystem: un filesysem vero e proprio dal punto di vista dell'utente che non utilizza un block device reale come "backend", ma mappa i propri file e directory all'interno di strutture di memoria kernel.
Come ogni altro filesystem, anche il cgroup filesystem (cgroupfs) va prima di tutto montato:
$ sudo mount -t cgroup -o cpu none /mnt
L'opzione "-o cpu" permette di specificare che vogliamo utilizzare il cgroup subsystem per il controllo della risorsa CPU. La directory /mnt è usata come mount-point per il cgroupfs.
Ogni directory all'interno di tale filesystem rappresenta un gruppo logico distinto (o cgroup).
A questo punto possiamo creare due gruppi distinti: uno per l'applicazione app1, l'altro per l'applicazione app2:
$ sudo chmod a+rw /mnt $ mkdir /mnt/group1 /mnt/group2
Il comando chmod serve per dare a ciascun utente i permessi per scrivere nel cgroupfs (ovviamente valgono le stesse regole di permessi UNIX anche per questo filesystem, per adesso limitiamoci al caso piu` semplice).
Per muovere un generico PID all'interno del gruppo e` sufficiente scrivere il PID stesso nel file "tasks" all'interno della directory che rappresenta il gruppo.
Esempio, per muovere la shell corrente (PID $$) all'interno del cgroup /mnt/app1:
$ echo $$ > /mnt/group1/tasks
Adesso lanciamo lo stesso esempio di prima, ma facendo girare app1 all'interno del cgroup "group1" e app2 all'interno del cgroup "group2":
- muoviamo la shell corrente all'interno del cgroup:
$ echo $$ > /mnt/app1/tasks
- lanciamo le 4 istanze di app1 (tutti processi lanciati da questo momento in poi, compresi i figli gireranno all'interno del cgroup "group1"):
$ for i in `seq 4`; do schedtool -a 0 -e ./app1 >/dev/null & done [1] 5889 [2] 5890 [3] 5891 [4] 5892
- spostiamoci nel cgroup "group2":
$ echo $$ > /mnt/app2/tasks
- lanciamo la singola istanza di app1:
$ for i in `seq 1`; do schedtool -a 0 -e ./app2 >/dev/null & done [5] 5894
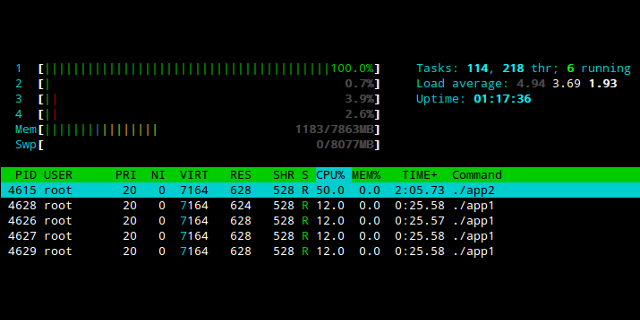
A questo punto l'output del comando "top" ci dice quanto segue:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5894 righiand 20 0 7164 628 528 R 50 0.0 0:15.33 app2
5889 righiand 20 0 7164 628 528 R 13 0.0 0:06.58 app1
5890 righiand 20 0 7164 628 528 R 12 0.0 0:06.58 app1
5891 righiand 20 0 7164 628 528 R 12 0.0 0:06.58 app1
5892 righiand 20 0 7164 628 528 R 12 0.0 0:06.58 app1
^^^^
Molto meglio. Adesso entrambe le applicazioni app1 e app2 stanno usando una quota di CPU del 50%, indipendentemente dal numero di task che essi utilizzano.
Conclusioni
In questo articolo abbiamo visto un esempio pratico di utilizzo dei cgroups molto basilare. Tuttavia anche un piccolo esempio come questo e` sufficiente a farci intuire le potenzialita` di tale infrastruttura.
L'approccio totalmente generico al raggruppamento di processi e al controllo di risorse lo rende uno strumento efficace in qualsiasi ambito: dall'ambiente desktop ai piu` complessi sistemi server e multiutente.
Ad oggi stanno nascendo tecnologie per l'hosting interamente basate sui cgroup (es. http://www.betterlinux.com/).
Addirittura i cgroup vengono usati in contesti piu` di carattere embedded: ad esempio Android usa lo stesso cgroup subsystem "cpu" (lo stesso usato nel nostro esempio), per garantire maggiore priorita` ai processi che girano in foreground e/o che hanno requisiti di reattività` maggiore, rispetto ai processi che girano in background.
In conclusione e` ipotizzabile che in futuro sentiremo parlare sempre piu` dei cgroup, e non solo in ambito server.
Riferimenti
Per approfondimenti:
http://lxr.linux.no/linux+v3.5.3/Documentation/cgroups/
http://hydra.geht.net/tino/english/faq/debian/squeeze/cgroups/
https://access.redhat.com/knowledge/docs/en-US/Red_Hat_Enterprise_Linux/6/html/Resource_Management_Guide/index.html
Andrea Righi sarà presente al Better Embedded 2012 il 24 e 25 settembre a Firenze.

Veramente interessante, non conoscevo le potenzialità dei cgroups ed inoltre, vedo ancora una volta l’importanza del comando top, con il quale ho avuto a che fare qualche tempo fa per individuare degli intrusi sul server. Poi li ho beccati 🙂
Interessante e spiegato molto bene!
Ottimo articolo, complimenti!
Oggi ho imparato qualcosa di nuovo.
🙂