Vi siete mai chiesti se è possibile parlare in qualche modo con il vostro fidato Raspberry Pi? La risposta è si ed è ciò di cui parleremo in questo blog post.
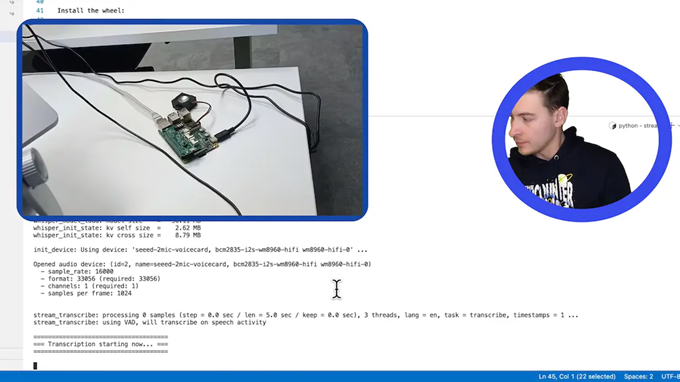
L'installazione di un modello di apprendimento automatico speech-to-text su un Raspberry Pi non è qualcosa di estremamente complesso. Con i recenti progressi architetturali nella progettazione di modelli di Machine Learning, questi vengono eseguiti senza problemi su piattaforme hardware anche meno potenti e con basse risorse di calcolo, e questo ha permesso di includere funzionalità basate sull'apprendimento automatico praticamente in tutti i tipi di progetti su cui si lavora. Gli strumenti corretti utilizzati variano per ogni caso d'uso, ma un'esigenza molto comune è quella di convertire il parlato in testo, ciò consente di impartire comandi verbali a un computer che può controllare una casa intelligente, interagire con un chatbot di grandi dimensioni o qualsiasi altra cosa. Tuttavia, al netto dell'entusiasmo iniziale, l'installazione di tutte le dipendenze e i framework, nonché la risoluzione dei problemi, portano a ore e ore di lavoro. E poiché l'installazione di quel modello speech-to-text è solo una funzione di supporto, non il punto principale del progetto, può essere un diversivo sgradito che distrae dai veri problemi da risolvere. Seguendo alcuni passaggi presentati nel video tutorial di seguito, puoi avere il tuo sistema di sintesi vocale attivo e funzionante in pochi minuti, senza che ciò distolga la tua attenzione da obiettivi più importanti.
Nel video di cui sopra, un Raspberry Pi con una nuova copia del sistema operativo viene utilizzato a scopo dimostrativo, anche se altri computer a scheda singola possono essere utilizzati in modo simile. Solo alcune dipendenze, come git e pip, devono essere installate, quindi deve essere clonato un fork di whispercpp per correggere alcuni problemi con il repository di origine. Dopo aver impartito alcuni altri comandi, il sistema sta già trascrivendo accuratamente il linguaggio parlato.
Ma cosa succede se il tuo progetto sta già mettendo a dura prova il tuo povero piccolo computer a scheda singola e non hai cicli di processore di riserva?
Nessun problema. Maslov, ideatore del progetto, discute anche di come faster-whisper possa essere integrato in whispercpp. Questo pacchetto offre le stesse funzionalità di sintesi vocale, ma è molto più veloce del tempo reale. In una dimostrazione, è stato mostrato che una clip audio di 11 secondi è stata trascritta in circa 1,5 secondi. Se hai bisogno del controllo vocale in qualsiasi progetto imminente, assicurati di dare un'occhiata a questo video. Ci sono anche alcuni link utili nella descrizione del video tutorial.



Inutile