Nei vecchi processori ARM l'esecuzione di un determinato programma combaciava esattamente con l'effettivo ordine delle istruzioni, un simile comportamento per quanto possa sembrare lineare e semplice non sempre ottimizzava i tempi di esecuzione. Se per esempio si effettuava una LOAD da una locazione di memoria non presente nella cache, recuperare i dati dalla memoria poteva richiedere diversi cicli d'istruzione, i nuovi processori ottimizzano così l'esecuzione proseguendo con le istruzioni in caso non dipendano dalla precedente. Questa modalità di esecuzione chiamata out-of-order execution può portare ad errori indesiderati nei processori moderni, per cui è necessario modificare il codice per ripristinare l'esecuzione nell'ordine in cui arrivano le istruzioni. In questo articolo cercheremo di capire il motivo di questi errori e i set di istruzioni per evitarli nella famiglia di processori Cortex-M.
Cortex-M e memory barrier
Vi avevamo presentato questa famiglia di processori tempo fa in un articolo, processori a bassa potenza, economici e ad alta prestazione usati nei microcontrollori, M0 ed M0+ caratterizzati da piccole dimensioni, M1 ottimizzato per gli FPGA, M3 ed M4 invece sono capaci a livello hardware di eseguire le MAC ovvero operazione di moltiplicazione e accumulo nell'ALU. Questi processori grazie al NVIC (Nested Vector Interrupt Controller) sono capaci di gestire 240 interrupt esterni gestendo fino a 256 livelli di priorità. In questi processori come già detto è necessaria l'implementazione delle memory barrier, necessaria dato che le istruzioni non vengono eseguite in ordine. Le memory barrier sono molto simili alle variabili dichiarate con la keyword volatile nel linguaggio C.
Perchè sono necessarie?
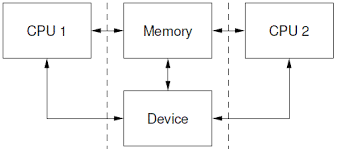
Figura1: Se più CPU o periferiche possono interagire con la memoria centrale è possibile avere errori dovuti ad una mancanza di sincronizzazione
Nei processori di ultima generazione abbiamo a che fare con sistemi multy-core come in figura 1 o con più enti capaci di interagire con la memoria centrale, per cui fin quando interagisco con locazioni di memoria con cui sono l'unico ad interagire l'esecuzione fuori ordine non mi darà mai problemi, tuttavia se due core devono accedere alla stessa locazione di memoria, uno per scrivere dentro e l'altro per leggervi, allora l'ordine in cui vengono effettuate le operazioni inizia ad essere rilevanti. Non sappiamo infatti quando avverrà l'effettiva lettura e scrittura del dato, per esempio se i sistemi 1 e 2 accedono alla variabile X,sia X una variabile locale contenente il valore 0, il sistema 1 vuole scrivere il valore 10 all'interno mentre il sistema 2 vuole leggere il dato al suo interno. Se il sistema 2 esegue l'accesso prima del sistema 1 otterrà il valore zero, ma se l'esecuzione fuori ordine mi posticipa questo accesso in memoria allora leggerò il valore 10, spetta quindi a me programmatore stabilire un giusto ordine di esecuzione per ottimizzare dove necessario senza ottenere errori indesiderati. [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2173 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:

L’evoluzione tecnologica dei sensori
Sistema di alimentazione cyber-fisico potenziato dalla rete spaziale Starlink

VALL-E: il sintetizzatore vocale in grado di imitarti
Identificazione di un modello per un motore a corrente continua (DC) con l’utilizzo di Arduino e MATLAB/Simulink

Teoria e applicazioni dei sensori magnetici digitali
