
Negli ultimi anni, il paradigma noto come GPGPU (General Purpose computing on Graphics Processing Units) ha rivoluzionato l'approccio ai problemi di High-Performance Computing (HPC), in cui sono richieste elevate capacità di calcolo, per le quali anche le moderne CPU, ormai, non sono più adatte. L'idea è semplice: sfruttare un tipo di hardware, inizialmente progettato per asservire ad un determinato scopo, per eseguire elaborazioni generiche. L'implementazione, però, è più complessa, e richiede numerosi accorgimenti, la cui comprensione è essenziale per sfruttare al meglio le potenzialità offerte dalle GPU. Approfondiamo, quindi, in questo articolo il funzionamento dell'architettura per il GPGPU più diffusa al giorno d'oggi, CUDA, mettendone in evidenza i principali vantaggi, e mostrando alcune situazioni nelle quali può veramente fare la differenza.
Introduzione
Chiunque abbia familiarità con l'architettura dei calcolatori sa che la CPU è il "cervello" di un computer: coordina le altri componenti, gestendo il passaggio dei dati tra dispositivi di I/O, memoria ed ALU. Per far questo, deve essere in grado di eseguire un gran numero di istruzioni, anche complesse, in maniera efficace (ergo, il più velocemente possibile). Purtroppo, però, la perfezione non esiste, e le CPU soffrono di due grossi limiti. Il primo è legato al fatto che le ALU sono in grado di eseguire un'istruzione in un tempo nettamente inferiore rispetto a quello necessario ad estrarre i dati da elaborare dalla memoria: ci saranno, quindi, inevitabilmente, dei cicli in cui la CPU sarà inattiva, con un chiaro spreco di risorse. Inoltre, le CPU possono eseguire le istruzioni solo in maniera sequenziale, e questo mal si adatta a problemi in cui le elaborazioni possono essere eseguite su più dati contemporaneamente. Per risolvere, almeno parzialmente, questi problemi, le moderne CPU sfruttano diversi layer di memoria ad alta velocità di accesso (registri e cache), dalla capacità sempre crescente, e sofisticati meccanismi di multithreading. Le GPU hanno un'architettura molto differente, e sono paragonabili ai "muscoli" del computer: sono composte da migliaia di unità di calcolo, su ognuna delle quali viene eseguito un thread differente; sfruttando questo massiccio grado di parallelismo, è possibile "nascondere" le latenze legate agli accessi in memoria, e quindi utilizzare meno layer di cache, ognuno di dimensioni inferiori. Facciamo ora un breve excursus storico, alla scoperta delle evoluzioni che hanno portato al paradigma GPGPU.
Voodoo Child
Tutte le GPU sono, in qualche modo, "figlie" della gloriosa Voodoo, introdotta da 3dfx nel 1996 per migliorare l'aspetto grafico nei videogames: la scheda garantiva, sul "pezzo forte" dell'epoca (Quake), 50 fps alla "mirabolante" risoluzione di 640 x 480, laddove i migliori Pentium arrivavano a malapena a 320 x 240, a 25 fps. La più importante innovazione tecnologica apportata dalla Voodoo fu la rendering pipeline, ossia una serie di step necessari a proiettare, sullo schermo del nostro computer, un rendering bidimensionale delle primitive poligonali definite da un motore grafico tridimensionale. Le prime rendering pipeline erano anche chiamate fixed-function pipeline, in quanto i passi erano predefiniti, e lo sviluppatore poteva soltanto modificare i parametri passati alle singole funzioni. Dopo qualche anno, grazie anche alla gara tecnologica tra nVidia ed ATI, furono introdotte le programmable rendering pipeline, che permettevano di programmare le pipeline, adattandole alle esigenze dello sviluppatore definendo degli shader, ossia apposite sequenze di istruzioni. I primi tipi di shader permettevano di manipolare i pixel (pixel shader) e di mappare i vertici dei poligoni da uno spazio tridimensionale ad uno bidimensionale (vertex shader); furono poi introdotti degli shader per creare nuovi tipi di primitive grafiche (geometry shader) e per modificare la granularità poligonale della scena a seconda dell'inquadratura (tesselation shader). L'evoluzione portò quindi ai compute shader, o compute kernel, svincolati dal rendering grafico, ed in grado di eseguire istruzioni di natura eterogenea, aumentando di conseguenza i campi di applicazione delle GPU.
Contestualmente, si assistette ad un'evoluzione dell'hardware; infatti, fino all'architettura G80 di nVidia, i differenti tipi di shader erano gestiti da unità dedicate, con la conseguenza che esisteva un tipo di scheda grafica per ogni specifica esigenza del mercato. Ad esempio, il rendering grafico nei videogames richiedeva operazioni complesse sui singoli pixel, per cui le macchine domestiche avevano un numero elevato di pixel shader; le applicazioni per il mercato business, di contro, richiedevano processing più elaborato sui singoli vertici (si pensi, ad esempio, al CAD), per cui le GPU dedicate avevano un maggior numero di vertex shader. Con l'aumentare della complessità delle applicazioni, però, nacque la necessità di allocare le risorse in maniera dinamica: questa maggiore flessibilità, assieme alla riduzione dei costi di fabbricazione dell'hardware, portò all'introduzione della Unified Shader Architecture, in cui i vari tipi di shader sono interscambiabili, grazie a degli instruction set molto simili tra loro. Nasce così il GPGPU come lo conosciamo oggi: le schede grafiche possono essere programmate per eseguire i task più disparati, ed i risultati ottenuti portano, in molti casi, ad un aumento delle performance di uno-due ordini di grandezza. L'evoluzione delle GPU è riassunta in Figura 1.
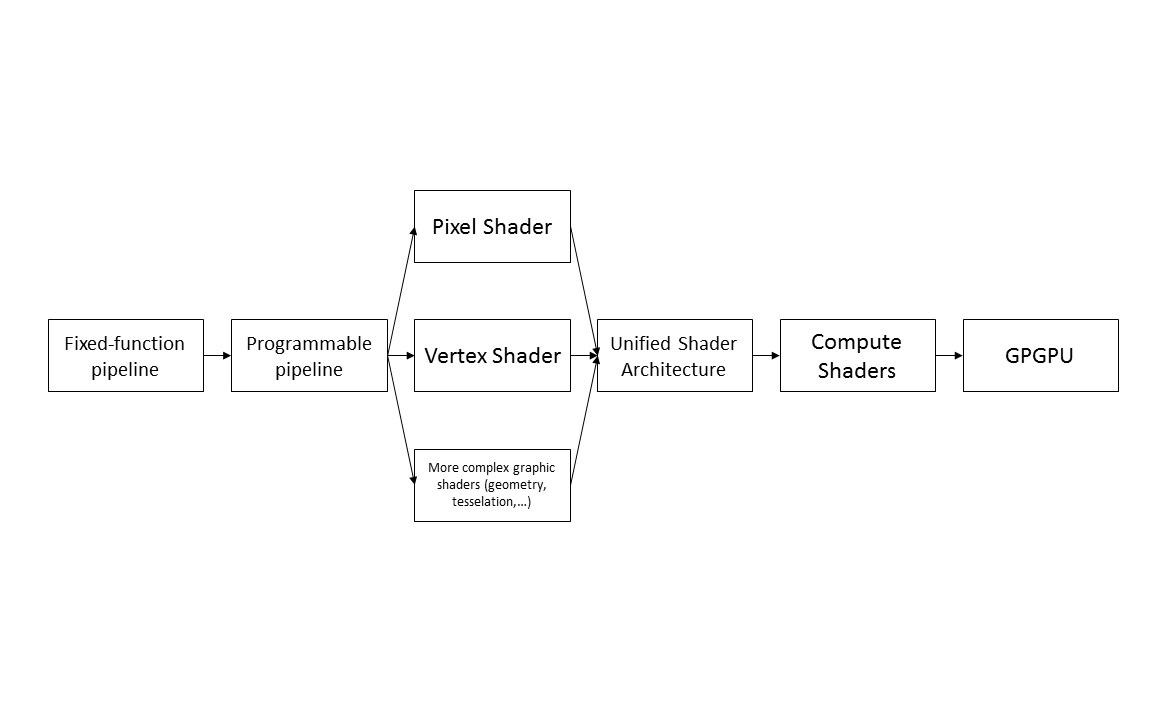
Figura 1. L'evoluzione delle GPU
Tutto risolto, quindi?
Da quanto appena detto, può apparire che, in linea di principio, basta istruire la CPU per "spostare", in qualche modo, l'elaborazione sulla GPU, per aumentare enormemente la velocità di esecuzione dei programmi. Questo non è sempre vero, dato che, affinché la GPU lavori in maniera efficiente, è necessario che l'algoritmo abbia due proprietà:
- elevato parallelismo a livello di dati
- elevata intensità di troughput
Usiamo un esempio classico: il filtraggio del rumore su un'immagine digitale. Sappiamo che l'immagine è rappresentata, in digitale, come una matrice a valori interi, le cui dimensioni sono pari ai pixel dell'immagine. Per eliminare il rumore, è possibile usare, nei casi più semplici, un filtro di media, che, se applicato su ciascun pixel, permette di smussare le variazioni di colore particolarmente brusche, attenuando il tipico effetto granulare che si osserva nelle immagini rumorose. Dal punto di vista matematico, il filtro di media è rappresentabile come una matrice di convoluzione, di dimensioni 3 x 3, in cui la somma degli elementi è pari ad 1; facendo scorrere questa matrice sull'immagine originale I, di dimensioni m x n, è possibile ottenere un'immagine O tale che, per ogni valore (i,j), con i = 1,...,m e j = 1,...,n il pixel O(i,j) assuma valore pari alla media dei pixel appartenenti all'intorno, di dimensioni pari a quelle della maschera di convoluzione (e quindi 3 x 3), centrato su I(i,j). Uno schema di questo algoritmo è mostrato in Figura 2.
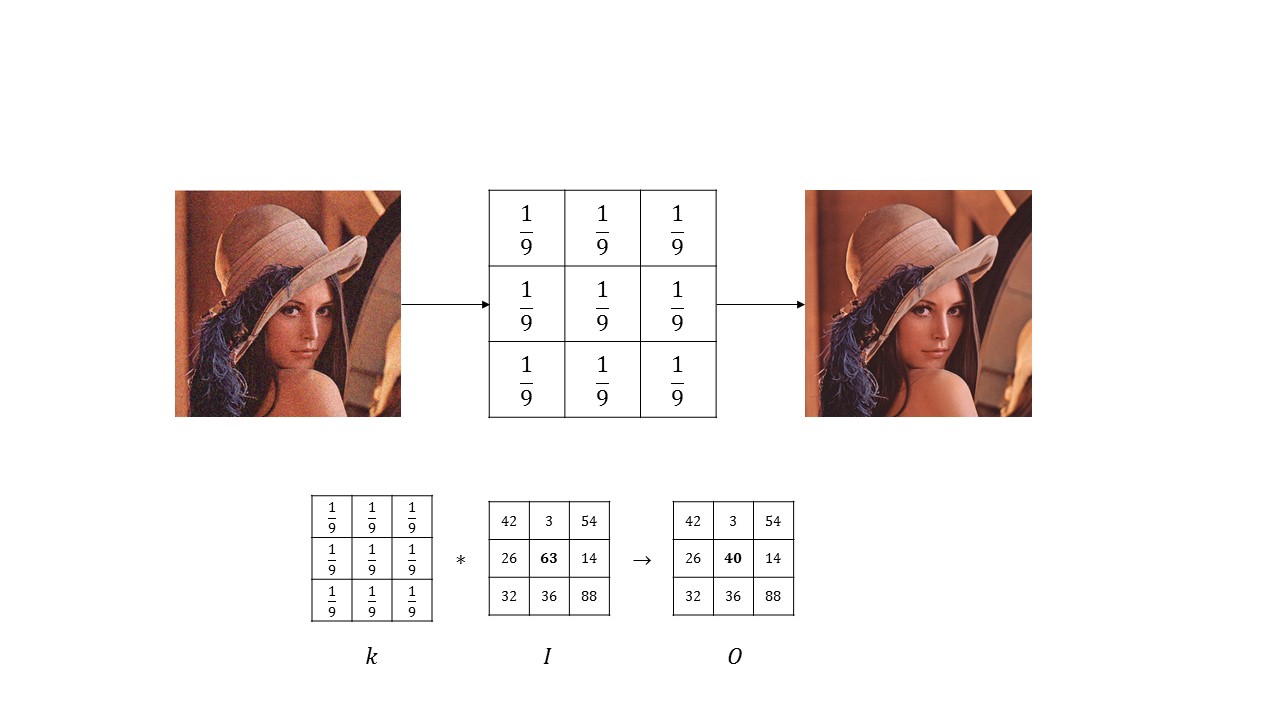
Figura 2. Principio di funzionamento di un filtro di media
E' importante notare che ogni pixel dell'immagine iniziale va elaborato in maniera indipendente dagli altri: questo è un classico esempio di operazione ad elevato parallelismo. Ovviamente, è necessario che vi sia uno scambio di dati tra le unità che effettuano l'elaborazione in parallelo: infatti, ognuna di queste dovrà accedere in memoria, estrarre la porzione di immagine che interessa, ed effettuare le operazioni richieste. Questi accessi comportano, come prevedibile, una certa latenza: di conseguenza, è necessario che il numero di dati su cui effettuare l'operazione (e quindi il throughput complessivo) sia tale da giustificare il costo aggiuntivo. A questo punto, però, nasce una domanda: perché le GPU sono adatte a risolvere problemi con queste caratteristiche?
Meet CUDA
Per rispondere a questa domanda, può essere utile parlare di CUDA, acronimo che sta per Compute Unified Device Architecture, paradigma introdotto da nVidia a partire dalle architetture G80, ed attualmente accettato come standard de facto (tant'è che, al momento, AMD è praticamente tagliata fuori dal mercato GPGPU). Alla base di CUDA vi sono alcuni concetti fondamentali: organizzazione gerarchica dei thread, che prevede che lo sviluppatore scomponga il problema in sotto-problemi, più semplici, che possono essere risolti in parallelo; shared memory, che permette di condividere, in un'area specifica di memoria, i dati tra i thread che lavorano, in parallelo, allo stesso problema, e barrier synchronization, concettualmente simile ad una barriera alla quale l'esecuzione del programma principale si interrompe, in attesa che i singoli thread in quel momento attivi, terminino le loro elaborazioni, per garantire la coerenza dei dati. Inoltre, vi sono due entità fondamentali, che vanno a definire il concetto noto come heterogeneous programming: da un lato, c'è un device, ossia la GPU, su cui sono eseguiti i thread; dall'altro, vi è l'host, ossia la CPU, fisicamente separato dal device, che esegue il programma principale. E' quindi importante notare come la parte GPGPU sia concettualmente, e fisicamente, separata da quello che potremmo definire come main thread: infatti, sia l'host sia il device hanno a disposizione memorie ben distinte (si parla, rispettivamente, di host memory e device memory): è l'host che si occupa di estrarre i dati dalla sua memoria, ed inviarli al device mediante le API messe a disposizione da CUDA; il device, dal canto suo, effettuerà le elaborazioni richieste, in maniera indipendente dall'host, e, una volta terminate, restituirà i risultati a quest'ultimo. [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2233 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
EOS-Book @8 Speciale Arduino

Progetto di una console Bluetooth di videogiochi retrò con Arduino e HC-05

Costruiamo un robottino in LEGO – Applicazioni

I pericoli nascosti degli assistenti vocali IoT: quello che c’è da sapere
