
Android, fin dall’inizio, ha catalizzato l’interesse di aziende e sviluppatori. Infatti, da sempre questa piattaforma software è stata costantemente migliorata sia in termini di caratteristiche sia di hardware supportato e, allo stesso tempo, si è cercato di assicurare la sua compatibilità verso nuovi dispositivi e applicazioni.
Introduzione
Android occupa una significativa quota di mercato nel segmento della telefonia. Tuttavia, una sua importante caratteristica non è stata ancora sufficientemente considerata: le sue eventuali applicazioni di tipo real-time in ambito embedded. Sappiamo che Android è una piattaforma open source inizialmente prevista in ambito della telefonia, basata sul sistema operativo Linux e sviluppata dall’Open Handset Alliance. La piattaforma mette a disposizione librerie dedicate (come il database SQLite o SGL e le OpenGL per le applicazioni in ambito grafico), un application framework, la Dalvik virtual machine (una Java virtual machine modificata) come ambiente di runtime e una serie di applicazioni preinstallate. Il sistema operativo è stato reso pubblico nell’autunno del 2008 e, da allora, sta guadagnando sempre più forza nel settore della telefonia e nel settore dei tablet su differenti architetture hardware. Il primo dispositivo mobile dotato della piattaforma Android è stato il T-Mobile G1, prodotto dalla società taiwanese HTC e commercializzato dal carrier telefonico T-Mobile: la nuova soluzione è stata presentata il 23 settembre di tre anni fa a New York. Oggi l’interesse crescente da parte dell’industria nasce per due aspetti fondamentali: la sua natura open source e il suo modello architetturale.
Infatti, grazie alla particolarità di essere un prodotto open source, Android può essere completamente studiato e compreso, insieme con la possibilità di gestire e implementare direttamente nuove funzionalità o trattare il bug fixing in totale autonomia. Non solo, non si deve trascurare la possibilità di poter effettuare il porting verso soluzioni architetturali diverse o custom. D’altra parte, l’apporto del kernel di Linux in Android ci permette di sfruttare le conoscenze a suo tempo acquisite assieme alle sue funzionalità, estremamente interessanti: entrambi questi aspetti fanno di Android un target interessante da utilizzare in ogni ambiente di lavoro. Le applicazioni Android sono basate su Java e questo comporta l’uso di un ambiente VM, una Virtual Machine, con vantaggi e problemi noti. Allo stato attuale presenta caratteristiche non ancora prese seriamente in considerazione, inclusa la possibilità di utilizzare Android in ambienti di tipo real-time. In effetti, esistono serie ragioni di fattibilità, anche per via dell’esperienza accumulata su lavori già svolti sul kernel di Linux o nella gestione della memoria in altri ambienti VM, per ritenere fattibile l’eventuale rispetto dei vincoli temporali al fine di utilizzarlo su sistemi embedded real-time, e questa particolare scelta diventa oggi indispensabile se si vogliono utilizzare applicazioni di tipo multimediale o se si ha necessità di gestire particolari risorse che devono garantire precise richieste temporali.
L’ARCHITETTURA DI ANDROID
Android, come Linux, non è un sistema in tempo reale. Di certo, è possibile portare Android in un contesto real-time e deterministico, ma questo è un compito non privo di rischi e costi. In effetti può anche succedere che, una volta terminato il porting, il lavoro ultimato presenti seri problemi d’incompatibilità, per via delle nuove prestazioni ricavate e per i driver utilizzati, tanto che alcuni ritengono che la soluzione migliore sia quella di utilizzare un sistema operativo commerciale e certificato. Android non è un sistema operativo propriamente detto perché, in realtà, è una suite di strumenti e librerie per realizzare applicazioni mobile. In effetti, analizzando la sua architettura, si scopre che Android è una piattaforma di lavoro che offre allo sviluppatore, o a un vendor di dispositivi, tutto ciò di cui ha bisogno per realizzare l’obiettivo preposto. Android è un sistema open source fornito dalla Open Handset Alliance: la piattaforma comprende un sistema operativo, middleware e applicazioni. L’architettura di Android si presenta suddivisa in cinque livelli, come mostrato in Figura 1, ovvero lo strato di Linux, le librerie, la parte di Runtime, le Application Framework e, per ultimo, le applicazioni propriamente dette.
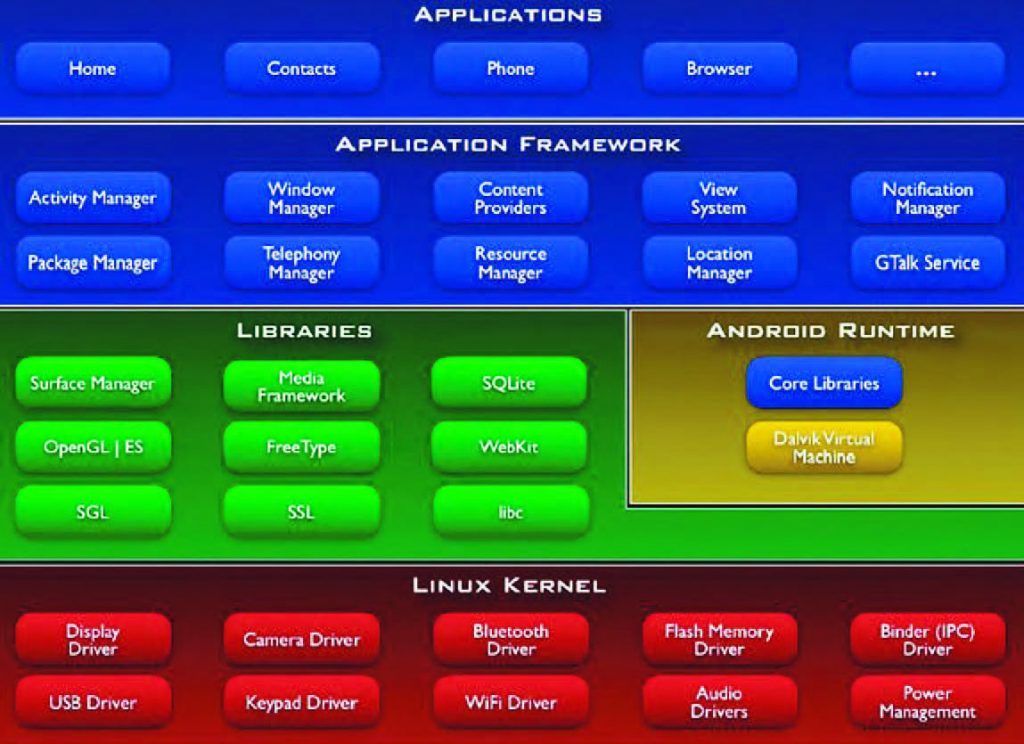
Figura 1: stack di Android
IL SISTEMA OPERATIVO
Il sistema operativo, il kernel di Linux, si basa sulla versione 2.6.x ed è utilizzato come livello di astrazione hardware. Questo strato comprende i servizi e i driver per i dispositivi principali come il Wi-Fi, la videocamera, l’audio e le memorie flash o la gestione dei processi. Non è una vera distribuzione Linux: il modulo non supporta le glibc o le native windowing system, e non comprende alcune utilities già presenti in una distribuzione standard. Alcuni hanno stimato la presenza di almeno 115 patch per garantire il supporto verso Android. Tra i moduli opportunamente inseriti nel kernel Linux spiccano le IPC binder o il Power Management. L’IPC, o Inter Process Communication, offre un sistema che permette di gestire le Inter Process Communication (IPC), simile agli standard CORBA e Java RMI per Sistemi Distribuiti. L’IPC binder nasce da un vecchio progetto open source e, come tale, ha diversi limiti che però possono essere trascurati in un sistema non real-time. A questo proposito possiamo individuare almeno due possibili problemi in fatto di sicurezza: il ruolo e il funzionamento delle Application e delle Services che, seppur possano essere messe in esecuzione in processi separati, devono potersi scambiare i dati durante il normale funzionamento, oltre al significativo overhead introdotto.
LE LIBRERIE
L’altro strato dell’architettura è identificato dalle librerie; in effetti, sopra il layer costituito dal kernel di Linux 2.6 abbiamo un insieme di librerie native realizzate in C e C++ che rappresentano il core vero e proprio di Android. Possiamo trovare la Libc, ossia l’implementazione della libreria standard C ottimizzata per i dispositivi basati su Linux embedded o la SSL, libreria per la gestione dei Secure Socket Layer. La SSL assicura una comunicazione sicura e una integrità dei dati su reti TCP/IP o la SQLite, una libreria in-process che implementa un DBMS relazionale. La SQLite non ha la necessità di essere configurata e risulta abbastanza compatta perché è realizzata in C in modo da utilizzare solo poche delle funzioni ANSI per la gestione della memoria. Non solo, la SQLite non utilizza alcun processo separato per operare ma coesiste nello stesso spazio del processo dell’applicazione che lo usa, da cui il termine in-process.
IL RUNTIME
Il Runtime di Android è costituito dalla Dalvik Virtual Machine anche se non è strettamente una macchina virtuale Java. La Dalvik è stata progettata in modo specifico per Android e si basa non sul concetto di stack ma su quello di registro. In effetti, la Virtual Machine presente in Android deve essere in grado di funzionare anche su piattaforme con risorse limitate e rappresenta un’ottimizzazione della macchina virtuale di Sun Microsystem, che permette di sfruttare al massimo le caratteristiche del sistema operativo ospitante. In Dalvik è possibile includere più classi in un unico file, oltre alla possibilità di eseguire ottimizzazioni durante la generazione del file da elaborare. Il file .dex, Figura 2, può anche vantare un buon rapporto di compressione, il che consente di dimezzare lo spazio adibito alla memorizzazione, rispetto ai file jar non compressi. La riduzione dello spazio utilizzato deriva dal fatto che stringhe e costanti presenti in più classi vengono incluse solo una volta nel singolo file .dex. La VM di Android si basa su un’architettura a registri, ciò significa che richiede il 30% di istruzioni in meno rispetto a una macchina a stack, a discapito di una maggiore elaborazione in fase di compilazione. La DVM permette, inoltre, una maggiore efficacia in esecuzione di più processi contemporaneamente. Infatti, ciascuna applicazione sarà in esecuzione all’interno del proprio processo Linux; ciò comporta alcuni vantaggi dal punto di vista delle performance e allo stesso tempo qualche implicazione dal punto di vista della sicurezza.
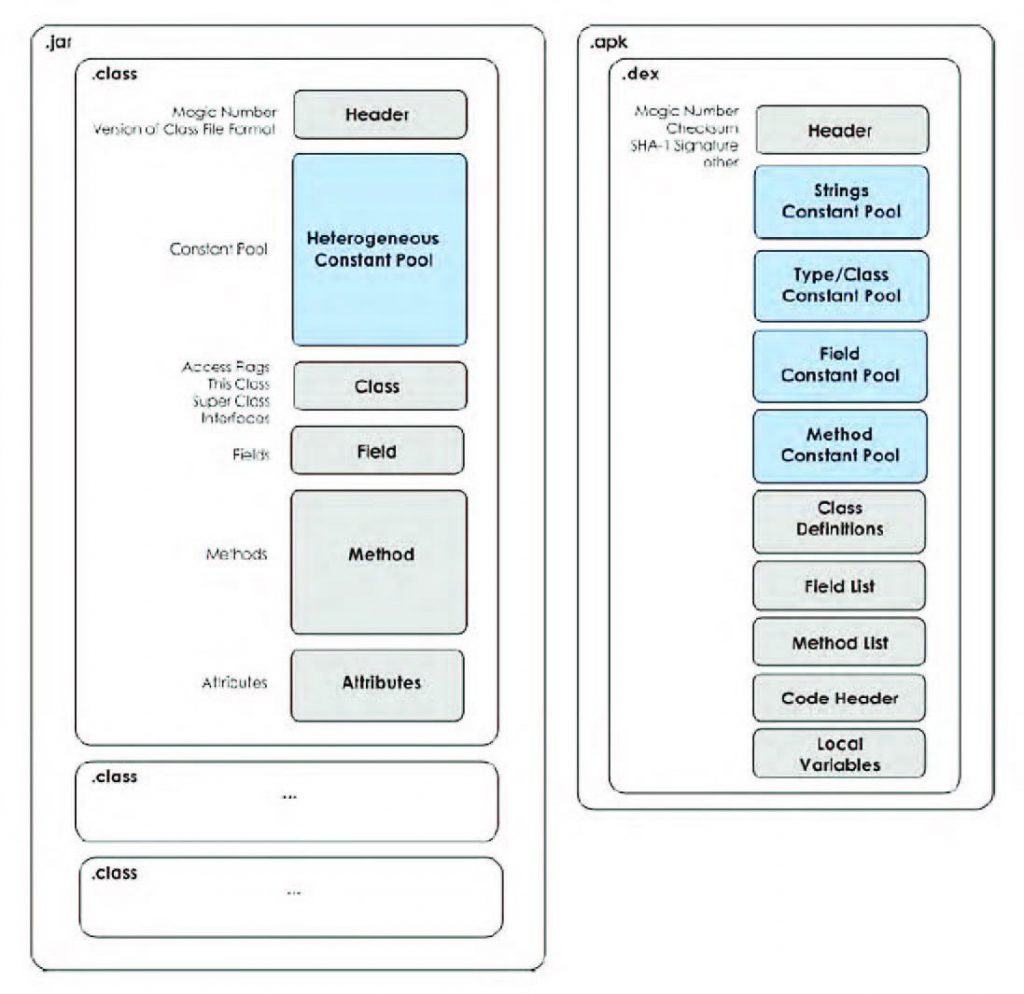
Figura 2: file .dex
L’APPLICATION FRAMEWORK
L’application framework è costituito da un insieme di API che sfruttano le librerie sottostanti dello stack Android e permettono allo sviluppatore di realizzare applicazioni estremamente ricche e innovative. Lo strato Application Framework comprende tutti i server messi in esecuzione nell’ambiente Android, sviluppati alla pari delle applicazioni che gestiscono attivamente le funzionalità del sistema operativo. Possiamo ricordare le Activity Manager o il Package Manager. Il primo è un modulo che si occupa della gestione delle activity, ovvero quelle entità che permettono all’utente finale di interagire con l’applicazione. Il suo compito è di gestire il ciclo di vita delle activity e di organizzare le loro schermate in uno stack secondo l’ordine di visualizzazione sullo schermo. Il Package Manager gestisce il processo di installazione e di rimozione di un’applicazione. Esiste anche il modulo Window Manager, ossia un server che gestisce lo schermo o il Resource Manager, che svolge il lavoro di gestore delle risorse di sistema.
LE APPLICAZIONI
All’ultimo livello dello stack architetturale di Android troviamo le applicazioni. In questo strato si trova un certo numero di applicazioni che sono regolarmente distribuite con Android. Queste possono sovrintendere alle diverse funzionalità quali e-mail, SMS o browser web. In Android le applicazioni sono scritte in linguaggio Java; il bytecode compilato e le risorse necessarie alla singola applicazione vengono riuniti con l’ausilio del tool aapt in un pacchetto .apk (Android Package). È questa la forma in cui un'applicazione può essere distribuita e installata in un dispositivo reale. Ogni applicazione in esecuzione nel sistema operativo, se lanciata, esegue un proprio processo Linux in seno a una propria istanza JVM privata; lo User ID del processo viene assegnato da Android in modo univoco nell’insieme dei processi in esecuzione (se non esplicitamente definito) e i permessi dei file vengono impostati così che ogni applicazione non possa accedere direttamente a risorse non proprie. Seguendo le indicazioni presenti in letteratura possiamo certamente dividere i sistemi in tempo reale in due grandi famiglie secondo la loro tolleranza ai guasti e alla loro deadline.
In effetti, quando si parla di real-time si vuole intendere che il sistema deve essere in grado di garantire la risposta a un evento, ossia che questa sia evasa in un determinato intervallo temporale: real-time non è sinonimo di veloce, semmai di deterministico. Nei sistemi di tipo hard real-time il sistema di controllo completa la sua attività entro il tempo stabilito dalla specifica, mentre quelli di tipo soft real-time non devono garantire la risposta entro certi vincoli temporali, anche se questa deve comunque avvenire. Per questa ragione in un sistema hard real-time la tolleranza è zero per non provocare una fault di sistema. Pensiamo a un sistema di arresto di una vettura: i dati devono essere garantiti in un determinato intervallo temporale indipendentemente dal carico dell’elaboratore. Abbiamo affermato che Android si basa su versione 2.6 di Linux: la riscrittura dell’algoritmo di scheduling è stata uno dei più importanti cambiamenti nel passaggio a Linux 2.6. Ricordiamo che lo scheduling è un algoritmo software utilizzato allo scopo di assegnare al meglio il carico di CPU. Per eseguire quest’operazione occorre decidere di assegnare il processore fisico a un processo pronto per l’esecuzione. A ogni processo corrispondono due parametri fondamentali: la politica di schedulazione e la priorità.
La versione standard del kernel di Linux permette tre politiche di schedulazione, divise in due categorie: politiche a priorità dinamica (OTHER) e politiche a priorità statica (FIFO e RR). In effetti l’algoritmo di schedulazione, almeno nelle prime versioni (anche se si può senz’altro affermare che il kernel 2.4 era già largamente utilizzato e affidabile), era molto semplice e intuitivo: ogni volta che avveniva uno switch di processo, il kernel controllava la lista dei processi running, aggiornava le loro priorità e selezionava, eseguendolo, il processo da mettere in esecuzione. Una gestione di questo tipo conduce, però, a spendere parecchio dal punto di vista computazionale. In questo contesto, lo scheduler era del tipo O(n), ossia più task sono presenti nel sistema e più tempo è richiesto dallo scheduler per effettuare la scelta del processo migliore. Fino alla versione 2.4 il kernel Linux si può considerare come un sistema di tipo preemptible per quanto riguarda i processi: a un processo può essere tolto il controllo anche se il processo stesso non lo concede esplicitamente. Al contrario, il kernel di Linux non è preemptible, ossia lo scheduler può funzionare solo in alcuni momenti predefiniti oppure quando il kernel volontariamente ne invoca l’esecuzione. Quest’ultima particolarità può evidenziare un potenziale problema, anche un processo “real-time” deve attendere che lo scheduler gli assegni la CPU e questo può avvenire con tempi massimi (deadline) non predicibili.
Al contrario, lo scheduler introdotto dal kernel 2.6 è più sofisticato e garantisce ottime prestazioni anche a fronte di un numero elevato di processi presenti in memoria; il suo peso in termini prestazionali infatti è costante, O(1). Lo schedulatore è stato sviluppato per sfruttare una possibile pluralità di CPU; ogni core, infatti, dispone della sua lista di processi runnable. In questa versione è stata anche migliorata la distinzione tra processi batch e processi interattivi. In ambiente Linux ogni processo è schedulato in accordo a una particolare classe. La classe SCHED_RR risulta simile alla politica FIFO anche se il processo scelto dallo schedulatore può funzionare solo per un periodo massimo di tempo, scaduto il quale il controllo passa a un altro processo e quando tutti i processi hanno esaurito il proprio quanto temporale tutti i contatori vengono re-inizializzati. La classe SCHED_RR appartiene a una classe di processi real-time con gestione Round Robin. Il suo funzionamento è abbastanza semplice: quando viene assegnata la CPU a uno di questi processi, lo scheduler mette il rispettivo descrittore di processo in coda alla runqueue list così da assicurare un’assegnazione della CPU equa ai processi di questa classe. Con la classe SCHED_FIFO occorre introdurre il concetto di priorità statica dei processi. In effetti, la priorità è rappresentata da un numero intero compreso tra 0 e 99, i processi con priorità statica più alta sono considerati più prioritari e una priorità statica maggiore di zero può essere assegnata solo ai processi real-time (ossia ai processi con politica SCHED_FIFO, o SCHED_RR, con gestione First-in, First-out).
Se lo scheduler assegna la CPU a un processo appartenente a questa classe, viene lasciato il rispettivo descrittore di processo nella runqueue list. Se non ci sono altri processi real-time con priorità maggiore, il task è posto in esecuzione fino a quando non si sospende, anche se sono disponibili processi con la stessa priorità. Un processo continua a mantenere il controllo della CPU fino a quando non diventa eseguibile un altro processo con priorità statica più elevata. Quando un processo FIFO diventa eseguibile, allora questo è messo in fondo alla lista di processi eseguibili con priorità pari alla sua. Un unico processo può controllare la macchina per il 100% del tempo. Infine, la SCHED_NORMAL è una classe per processi convenzionali di tipo time-shared. In questo caso si utilizza la priorità dinamica, un valore di base sommato al numero di tick mancanti all’esaurimento del time quantum per il processo, e il time quantum per decidere quale processo far girare. La priorità dinamica di un processo viene fatta decrescere nel corso del time quantum associato al processo stesso. In questo modo si favorisce una equa distribuzione del tempo macchina. Ogni processo non in ambito real-time ha la propria priorità statica, un parametro che usa lo scheduler per trattare ogni processo adeguatamente, nel rispetto degli altri processi nel sistema. Il kernel riserva 40 valori per rappresentare questo ambito, da 100 (priorità maggiore) a 139 (priorità minore): all’aumentare del valore, la priorità del processo diminuisce. Un nuovo processo eredita sempre la priorità statica del padre; tuttavia, un utente può configurare la priorità di un processo modificando il nice del processo attraverso le chiamate a sistema nice() e setpriority(). Ogni processo real-time dispone di una priorità real-time che va da 1 (priorità più bassa) a 99 (priorità più alta).
A differenza dei processi convenzionali, quelli real-time sono sempre attivi. Se più processi real-time hanno la stessa priorità, lo scheduler sceglie quello che risulta primo della lista di priorità a cui appartiene (di una data CPU). Un processo real-time viene rimpiazzato da un altro a determinate condizioni. Questo può accadere quando il processo subisce prelazione da un altro processo con maggiore priorità, l’osservazione sembra piuttosto scontata. Il processo esegue un’operazione bloccante ed è messo a “riposo” (nello stato TASK_INTERRUPTIBLE), il processo è stato fermato (nello stato TASK_STOPPED o TASK_TRACED), oppure se è “ucciso” (tramite comando kill, quindi in stato EXIT_ZOMBIE o EXIT_DEAD), il processo rilascia volontariamente la CPU lanciando la chiamata di sistema sched_yield() o il processo è in Round Robin real-time (SCHED_RR) e, una volta ultimato il suo quanto temporale, subisce prelazione. La versione del kernel 2.6, rispetto alle precedenti, è differente perché implementa un nuovo scheduler e riesce a eseguire tutte le operazioni critiche in un tempo costante e indipendente dal numero di processi presenti sulla macchina. L’obiettivo è stato raggiunto intervenendo nel codice e riscrivendo, ad esempio, le strutture dati che contengono i descrittori dei processi. Il kernel di Linux offre meccanismi che permettono ai programmatori di sfruttare una politica di schedulazione di tipo preemptive fixed priority. In realtà, quando si utilizza questo tipo di politica non è possibile ottenere un comportamento in tempo reale.
Ecco perché, da più parti, si è deciso di realizzare sistemi di schedulazione di tipo dinamico: invece di usare priorità statiche si preferisce utilizzare il concetto delle scadenze dinamiche. Questi schemi di programmazione, o scheduling, dinamici hanno il vantaggio di assicurare il pieno utilizzo CPU ma, allo stesso tempo, presentano un comportamento imprevedibile di fronte a sovraccarichi di sistema. Dalla versione 2.6.23 il kernel Linux utilizza il Completely Fair Scheduler, CFS, e si applica nel momento in cui si assegnano le attività. Il sistema assicura l’equità anche se l’algoritmo non fornisce alcuna garanzia temporale sulle attività in esecuzione. Non solo, Android, allo scopo di rispondere ai requisiti di memoria, utilizza una propria versione di Virtual Machine, la Dalvik. In sostanza, la Dalvik è stata appositamente realizzata per rispondere ai requisiti stringenti delle applicazioni mobile, quali l’ottimizzazione della memoria e il risparmio energetico della batteria. Il gestore della memoria, così come la sua Virtual Machine, si basa sui servizi del kernel di Linux, rivelando anche i suoi limiti in fatto di esecuzione temporale. La Dalvik Virtual Machine assicura l’esecuzione di multiple istanze di processi ognuno con la sua porzione di address e memory space, implementa il Java Concurrency Model mentre la parte di schedulazione e la gestione degli interrupt sono delegate al kernel di Linux. Lo stack Android, chiamato anche da alcuni linux-derived, ricava da Linux tutti i suoi modelli comportamentali in fatto di gestione dei processi, della memoria, dei driver di periferica, fino a supportare le librerie condivise e a implementare il proprio modello di sicurezza basato su permessi. Di conseguenza utilizzare Android in situazioni real-time embedded significa dover ripensare alla sua architettura, anche se non nel suo complesso. Da una parte può essere necessario sostituire la Virtual Machine attualmente presente con una dalle migliori caratteristiche in tempo reale e con un maggiore controllo delle risorse fisiche, mentre dall’altra diventa anche necessario introdurre in Linux i criteri di real-time.
Su questo aspetto esistono almeno quattro classi di pensiero:
- il primo approccio considera la sostituzione del sistema operativo Linux con uno che rispetti i paradigmi di real-time assieme all’inserimento di una VM in tempo reale;
- il secondo approccio rispetta l’architettura standard di Android proponendo, però, l’estensione della Dalvik come così il sistema operativo;
- il terzo approccio sostituisce semplicemente il sistema operativo Linux per una versione, sempre di Linux, ma in tempo reale;
- il quarto approccio propone l’aggiunta di un Real-Time Hypervisor in grado di supportare l’esecuzione parallela della piattaforma Android in una partizione.
Nel primo caso, Figura 3, si sostituisce il kernel standard di Linux con un vero e proprio sistema operativo in tempo reale: in questo modo si introduce la predictability e il determinismo nell’architettura di Android.
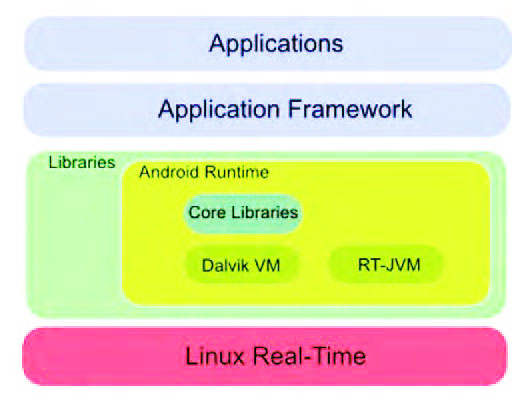
Figura 3: Android full real-time
Con questa scelta si introducono nuove dinamiche in tempo reale con opportune politiche di schedulazione insieme con una gestione dell’inversione di priorità e una migliore strategia sull’uso delle risorse. Questa scelta non è indolore perché comporta una ridefinizione dei vari driver presenti nella suite di lavoro che, al momento, sono supportati in modo nativo; infatti, sarebbe necessario integrare in Linux, o nel sistema scelto, i differenti driver in modo da garantire una maggiore integrazione e flessibilità. Il secondo approccio è maggiormente intrusivo perché prevede, insieme con la sostituzione di un kernel real-time, di includere una real-time virtual machine, Figura 4.
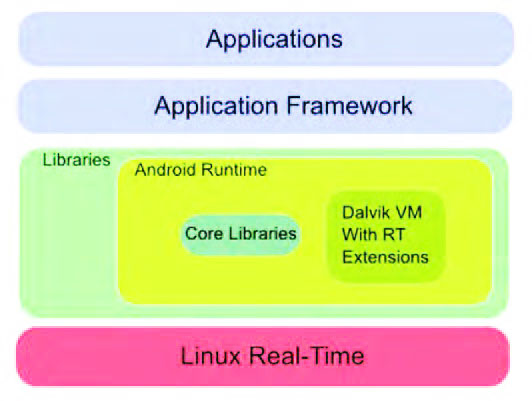
Figura 4: real-time esteso
Per molti questa possibilità è da preferire perché garantirebbe un maggiore controllo della memoria e la sua gestione in tempo reale. Non solo, una soluzione di questo tipo sposerebbe anche i diversi criteri di sincronizzazione e d’inversione di priorità. È inutile precisare che una VM real-time interagisce direttamente con il kernel al fine di gestire, in modo corretto ed efficiente, i diversi requisiti di controllo e gestione fino alla scelta di una politica di schedulazione più efficace. Inoltre, un aspetto da considerare è l’integrazione delle due VM, quella di Dalvik e la parte real-time, tanto che le due specificità dovranno, per forza di cose, coesistere per evitare problemi di portabilità delle applicazioni. È necessario inserire nei file .dex e nell’interprete, quelle specificità di tempo reale che non possono assolutamente mancare. Può anche succedere, per via di questa integrazione, di dover definire nuove politiche di schedulazione e algoritmi di allocazione e controllo della memoria allo scopo di ottenere un sistema flessibile, sicuro e ottimizzato. Questa soluzione è una delle più onerose e intrusive perché è necessario ridiscutere l’architettura di Android, del suo sistema operativo e della sua Virtual Machine anche se, probabilmente, l’aspetto più delicato è la messa a punto di una versione della Dalvik con funzionalità estese basate sulle caratteristiche della RTSJ, ossia la Real-Time Specification per Java. In sostanza, può essere necessario inserire nuove funzioni quali RealTimeThread e NoHeapRealTimeThread o nuove strutture per la schedulazione in tempo reale della gestione della memoria fisica con l’aggiunta di algoritmi di sincronizzazione e del trattamento degli eventi asincroni. È chiaro che molto dipende dal grado di real-time o di sicurezza che vogliamo conferire alla nostra architettura. Esiste anche una terza possibilità, ossia utilizzare una versione di Linux real-time. In questo caso, Figura 5, è possibile distribuire le nostre applicazioni direttamente su Linux sfruttando direttamente le sue prerogative, in special modo per quelle applicazioni che non hanno l’esigenza di sfruttare la Virtual Machine.
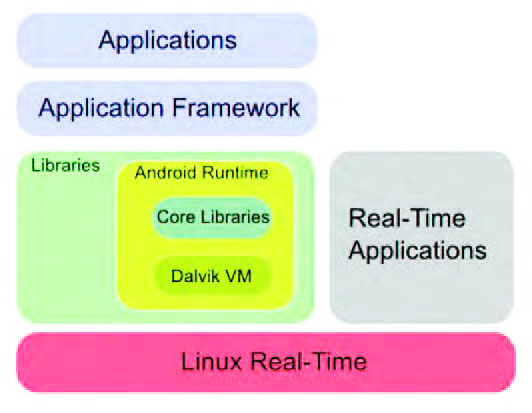
Figura 5: Android parzialmente real-time
Al contrario, quelle che ne necessitano non potranno utilizzare i benefici di un sistema sicuro e affidabile; in sostanza, in questo modo è il consumatore finale, in base alle sue esigenze, a decidere la sua architettura di lavoro in modo perfettamente trasparente. Con una scelta di questo tipo, poiché le applicazioni con i requisiti di real-time devono essere realizzate utilizzando direttamente un sistema operativo di questo tipo, non si ha la necessità di utilizzare una Virtual Machine e ciò comporta un impatto minimo in fase di integrazione. L’ultima possibilità sfrutta un Real-Time Hypervisor, Figura 6, al fine di garantire l’uso di Android all’interno, però, di un sistema partizionato, come guest, in modo da utilizzare le differenti funzionalità in partizioni diverse.
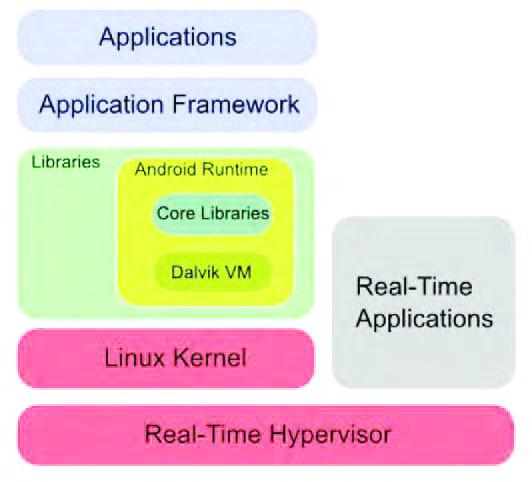
Figura 6: Android con Hypervisor
Questa scelta, è bene ricordarlo, è già la strada in soluzioni Linux alternative quali RTLinux o RTAI: in questo modo si garantisce l’esecuzione delle applicazioni in parallelo a Linux con differenti livelli di priorità. Un approccio di questo tipo introduce, nel contempo, diverse limitazioni; in effetti, le applicazioni utente in questo nuovo sistema dipendono fortemente dai gradi di libertà dell’Hypervisor presente e ciò potrebbe comportare una perdita di alcune funzionalità oppure della Virtual Machine di Dalvik o dei servizi che Linux mette a disposizione. A questo proposito esiste un’interessante distribuzione, CodeZero, che permette di virtualizzare Android e Linux su processori multicore delle serie ARM. CodeZero assicura la virtualizzazione delle applicazioni ricorrendo a soli 12 API e con 10 kb di codice scritto in linguaggio C [4].
CONCLUSIONI
Nella prossima parte vedremo alcuni aspetti della Virtual Machine utilizzata in ambito Android e diverse considerazioni legate all’hardware. In particolare, approfondiremo i meccanismi da utilizzare per effettuare il porting di Android su una scheda embedded.


