
La natura, il numero e la modalità con cui i singoli neuroni artificiali sono connessi tra loro occupa un ruolo fondamentale nella definizione dell'architettura di una rete neurale. Scopriamo in questo articolo quali sono le principali architetture di reti neurali utilizzate nel deep learning e a quali applicazioni si rivolgono
Introduzione
Anche se la prima definizione di rete neurale risale ormai a oltre settanta anni fa, solo di recente si è assistito a un proliferare di nuove architetture rivolte soprattutto alle applicazioni di deep learning. L'approfondita attività di ricerca compiuta negli ultimi venti anni, unitamente alla disponibilità di unità di elaborazione grafica (GPU) in grado di supportare algoritmi paralleli su un numero elevatissimo di core, ha permesso la formulazione di nuove architetture per il deep learning. Nel corso dell'articolo esamineremo cinque tra le principali e più famose architetture per il deep learning:
- reti neurali ricorrenti, note anche con il termine RNN (acronimo di Recurrent Neural Network);
- reti neurali a breve e lungo termine, note anche con il termine LSTM (acronimo di Long Short Term Memory). A questo gruppo appartengono anche le reti neurali di tipo GRU (acronimo di Gated Recurrent Unit);
- reti neurali convoluzionali, note anche con il termine CNN (acronimo di Convolutional Neural Network);
- reti DBN (acronimo di Deep Belief Network);
- reti DSN (acronimo di Deep Stacking Network).
È importante sottolineare come il deep learning non consista in un singolo approccio all'applicazione, ma comprenda piuttosto un insieme di algoritmi e differenti architetture di reti neurali applicabili a un ampio spettro di problemi. Oltre alle GPU, un fattore che negli ultimi anni ha contribuito all'evoluzione e all'espansione delle reti neurali è attribuibile all'enorme quantità di dati e informazioni aggregate oggi disponibili (il cosiddetto Big Data). Per loro natura, infatti, molte tipologie di reti neurali sono basate su algoritmi di apprendimento supervisionato (supervised learning): maggiore è la disponibilità di dati, migliore e più rapida sarà la fase di addestramento della rete.
GPU e deep learning
Come dice il nome stesso, il deep learning è caratterizzato dalla presenza di architetture "deep", cioè composte da più livelli (o layer) interconnessi in vario modo tra loro. Ciascuno di questi livelli fornisce una funzionalità ben precisa (come ad esempio la feature extraction o il pooling), mentre il tipo di layer e la modalità con cui sono posti in sequenza sono intimamente collegati al tipo di applicazione di rete neurale. In questo contesto i processori grafici (GPU) svolgono un ruolo cruciale, consentendo sia l'addestramento che l'esecuzione di reti neurali "deep" con architetture anche molto complesse. Rispetto ai processori di tipo tradizionale (CPU), le GPU raggiungono dei livelli di efficienza nettamente superiori. Come visibile in Figura 1, un processore tradizionale con architettura multi core contiene attualmente da un minimo di quattro fino a oltre venti CPU per impieghi generici. Una GPU, viceversa, contiene da un minimo di circa mille fino a qualche migliaio di core progettati per applicazioni specifiche (si osservi la Figura 2). L'elevata densità di core permette alle GPU di eseguire algoritmi paralleli, intendendo con ciò la possibilità di spezzare il normale flusso di programma (tradizionalmente di tipo sequenziale) in più parti, ciascuna eseguita su uno specifico core. Proprio per questo motivo le GPU si prestano ad essere utilizzate nella fase di addestramento ed esecuzione di una rete neurale, dove l'attivazione di molti neuroni può essere processata operando in modo simultaneo. Anche le CPU tradizionali includono più core, ma il loro numero non è comparabile a quello di una GPU. Le GPU sono inoltre molto efficienti nell'eseguire i calcoli in virgola mobile, un requisito fondamentale per le reti neurali dove occorre eseguire numerose operazioni di moltiplicazione e addizione. Tutti questi aspetti fanno sì che l'architettura delle GPU, applicata al contesto delle reti neurali, permetta di avvicinarsi al cosiddetto "parallelismo perfetto" (perfectly parallel), dove non è richiesto alcuno sforzo (o quasi) per convertire un'algoritmo tradizionale in uno con esecuzione parallela.
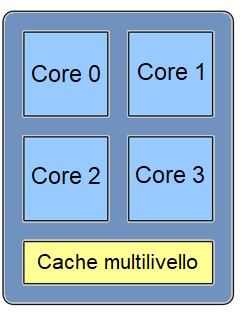
Figura 1: schema a blocchi di una CPU multi core per impieghi generici
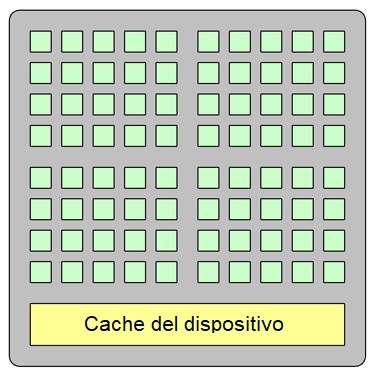
Figura 2: schema a blocchi di una GPU
Le architetture per il deep learning
Come anticipato in precedenza, l'esistenza delle reti neurali risale ormai a oltre settanta anni fa, ma soltanto nelle ultime due decadi si è assistito a un proliferare di nuove architetture e modelli di connessione tra i neuroni adatti a un utilizzo nelle applicazioni di deep learning. In Figura 3 possiamo osservare un diagramma temporale in cui è collocata, grosso modo, la nascita di ogni particolare architettura di rete neurale. Possiamo ad esempio subito osservare come le architetture LSTM e CNN siano tra le più anziane, nonostante siano ancora oggi quelle maggiormente impiegate a livello pratico. [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2792 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:

Il versatile mondo del LiDAR
Sensori per sistemi embedded – Parte 2

Sensori industriali: caratterizzazione, principi di funzionamento e applicazioni

Starlink: quanto c’è da sapere sul sistema di telecomunicazioni più famoso ad oggi

Giochiamo con Arduino: strumento musicale ad ultrasuoni “no touch”
L’apprendimento profondo sta rapidamente emergendo come componente chiave di un ampia platea di applicazioni di intelligenza artificiale stimolanti e incredibilmente utili, e le GPU offrono un potente strumento per esplorare la potenza e il potenziale del deep learning. Questi strumenti rappresentano un vero cambio di paradigma per ciò che riguarda l’apprendimento automatico.
Il numero di framework di apprendimento profondo open source rivolto a sviluppatori e data scientist aumenta. Non a caso quella del data scientist è una delle professioni del futuro. Sarà interessante leggere ogni approfondimento.
Bellissimo articolo.
Anche nel mondo degli Scacchi il Deep Learning sta prendendo piede. Basti pensare che i nuovi studi basati anche sull’IA hanno permesso di surclassare il più potente chess engine del momento (Stockfish) ad opera di Alphazero,
Le applicazioni di deep learning stanno ottenendo risultati considerevoli anche nel campo della diagnosi medica. Oltre alla diagnostica per immagini (dove possono aiutare a formulare diagnosi precoci), le reti neurali opportunamente addestrate si stanno dimostrando valide anche come supporto nella formulazione di diagnosi di malattie comuni e rare.
In robotica il Deep Learning permette di creare robot più intelligenti in grado di percepire l’ambiente circostante e di reagire a particolari stimoli.