
I ricercatori del MIT hanno ipotizzato che i soggetti affetti da COVID-19, in particolare gli asintomatici, potrebbero essere accuratamente discriminati per mezzo di un colpo di tosse forzato utilizzando una AI nel telefono cellulare. Da questa idea si potrebbe creare uno strumento di screening per gli asintomatici positivi al COVID-19, gratuito, non invasivo, su larga scala, in tempo reale, in grado di migliorare gli approcci attuali nel contenere la diffusione del virus. I casi d'uso pratici potrebbero essere lo screening quotidiano di studenti, lavoratori e la riapertura del trasporto pubblico o i test per trovare rapidamente i focolai. In questo articolo vedremo il modello di Intelligenza Artificiale progettato dal MIT, le fasi di addestramento e i risultati ottenuti.
Introduzione
Man mano che il virus si diffonde nei vari paesi che non possono permettersi test giornalieri a livello nazionale né confinamento, una preselezione su larga scala, a basso costo e accurata potrebbe essere uno strumento essenziale per dare la priorità ai test rapidi e prevenire localmente i focolai. Recentemente, sono stati diversi gli approcci AI proposti per supportare la gestione della pandemia. Un test per la tosse con Intelligenza Artificiale fornirebbe qualche vantaggio che potrebbe compensare parzialmente i problemi esistenti con i test biologici. I vantaggi dei test mediante AI includono: non invasività, risultati in tempo reale, zero costi variabili e accessibilità per tutti.
Come ogni approccio AI mediante Deep Learning, si rendono necessari dei dati di addestramento e una strategia di modellazione.
- Per la componente dati è stato avviato un crowdsourcing mondiale per raccogliere campioni audio della tosse forzata di persone affette da COVID-19, insieme a 10 domande a risposta multipla relative alla diagnosi della malattia ed ai sintomi rilevanti. Il MIT Open Voice COVID-19 Cough dataset rappresenta il più grande set di dati audio sulla salute con diverse centinaia di migliaia di registrazioni di colpi di tosse. Tra queste sono state selezionate 5.320 divise equamente tra positivi al COVID-19 e negativi.
- Per affrontare la strategia di modellazione, i ricercatori si sono ispirati alla loro precedente ricerca sull'Alzheimer. Tale scelta trova giustificazione dalla crescente evidenza dei sintomi riportati da pazienti affetti da COVID-19, che hanno subito menomazioni neurologiche come la perdita dell'olfatto durante e dopo l'infezione. Dopo aver provato senza successo alcuni modelli CNN di base, la connessione tra COVID-19 e cervello ha portato gli sforzi di modellazione verso il framework OVBM (Open Voice Brain Model), già applicato alla diagnosi dell'Alzheimer con una precisione del 93,8%. Il framework OVBM identifica i biomarcatori acustici utili per la diagnostica.
Dataset
Nell'aprile 2020 è stata avviata una raccolta di dati sulla tosse a livello mondiale attraverso il motore di registrazione del sito web (opensigma.mit.edu). L'obiettivo era quello di creare il dataset MIT Open Voice per la discriminazione dei positivi al COVID-19 attraverso la tosse.
Sono state raccolte per ogni soggetto le seguenti informazioni:
- registrazioni audio di colpi di tosse di lunghezza variabile (in media 3 per soggetto)
- 10 domande a risposta multipla relative alla diagnosi della malattia
- informazioni generali come età, sesso, paese, regione
- la data e il risultato della eventuale diagnosi medica fatta e se la fonte della diagnosi era un test ufficiale, una valutazione medica o una valutazione personale
- informazioni sui sintomi e numero di giorni dalla loro comparsa. I sintomi includevano febbre, stanchezza, mal di gola, difficoltà a respirare, dolore persistente o pressione al petto, diarrea e tosse
Il motore di registrazione è stato reso disponibile su vari browser e dispositivi, riducendo così ogni possibile bias specifico del dispositivo. I dati resi anonimi prima di essere raccolti su un server sicuro. I campioni sono stati salvati senza compressione in formato WAV (bit rate 16kbs, canale singolo, codec opus). Nessuna segmentazione è stata eseguita sulle registrazioni utilizzate per addestrare e testare. Sono stati utilizzati tutti i campioni relativi ai positivi al COVID-19 presenti nel set di dati e selezionati casualmente lo stesso numero di soggetti negativi al COVID-19 per una distribuzione equilibrata. Sono stati utilizzati solo campioni rispondenti a due condizioni:
- diagnosi eseguita negli ultimi 7 giorni
- insorgenza dei sintomi non più in là di 20 giorni con sintomi continuati fino alla cattura del campione
L'audio della tosse forzata del soggetto e i risultati diagnostici sono stati utilizzati per addestrare e convalidare il discriminatore COVID-19. Nello specifico, 4256 campioni (80%) sono stati utilizzati per la fase di addestramento e 1064 (20%) per la fase di validazione.
Architettura del modello
L'architettura utilizzata (Figura 1) riceve in ingresso una registrazione con uno o più colpi di tosse, eseguendo due fasi di pre-elaborazione su di essa e la inserisce in un modello basato su CNN per produrre in uscita una diagnostica di pre-screening.
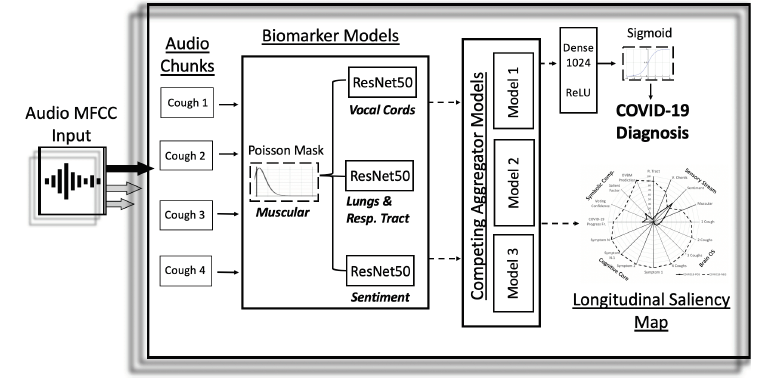
Figura 1: Panoramica dell'architettura del discriminatore COVID-19 attraverso le registrazioni della tosse come input e diagnosi di positività o negatività al virus come output
Come pre-elaborazione, ogni registrazione in ingresso è suddivisa in segmenti audio (audio chunks) da 6 secondi, elaborati con il blocco MFCC e successivamente passati al biomarcatore. L'output di questi passaggi diventa l'input per la rete CNN. L'architettura della CNN è composta da tre ResNet50 in parallelo. Lo strato di output del tensore di ciascun modello ResNet50 è concatenato in parallelo. Nei modelli di base, questi ResNet50 non sono pre-addestrati. Nel modello con le migliori prestazioni, sono pre-addestrati per l'acquisizione delle caratteristiche acustiche dei biomarcatori 2,3 e 4. L'output di questi tre tensori concatenati è allora raggruppato utilizzando uno strato 2D di Global Average Pooling, seguito da uno strato di rete neurale con 1024 neuroni profondamente connesso (denso) con attivazione ReLU e infine un strato binario denso con attivazione sigmoidea. I risultati presentati nella Tabella 1 si basano esclusivamente sull'uscita relativa al primo segmento audio.
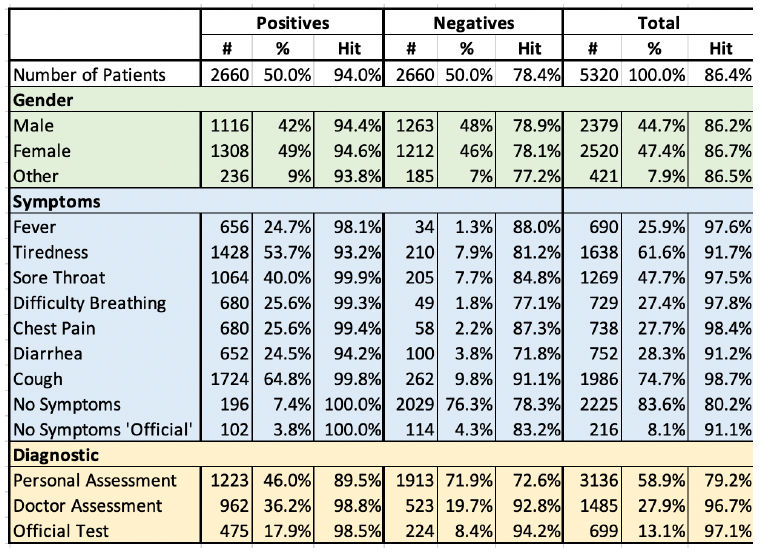
Tabella 1: La selezione dei soggetti COVID-19 non è equilibrata nei termini di nessuna statistica demografica specifica. I positivi risultano per il 41,8% essere uomini, per il 53,0% donne e per l'8,9% altro; questo perché tali sono le percentuali rispetto al totale dei partecipanti volontari. Pertanto, le percentuali riflettono il campione e quindi la migliore stima delle prestazioni complessive se uno screening fosse effettuato su base volontaria su larga scala. La colonna "Hit" mostra l'accuratezza del modello per ogni rispettivo sottogruppo. Le 3 categorie a fine tabella (valutazione personale, dottore e ufficiale) corrispondono alla fonte della diagnosi inserita da ciascun soggetto
Biomarcatori
L'architettura utilizza quattro biomarcatori precedentemente testati per il rilevamento dell'Alzheimer ed ispirati dalle scelte della comunità medica. Tali biomarcatori sono: il degrado muscolare, i cambiamenti nelle corde vocali, i cambiamenti nell'umore e quelli nei polmoni e nel tratto respiratorio.
Biomarcatore 1 (degrado muscolare)
Seguendo i modelli di decadimento della memoria, sono state introdotte le caratteristiche di affaticamento muscolare e degrado modificando i segnali di ingresso, per entrambi i set di addestramento e test, mediante Maschera di Poisson. Il decadimento di Poisson è una distribuzione comune in natura che è stata precedentemente utilizzata per modellare la degradazione muscolare. Rimuovendo questo biomarcatore il tasso di errore in previsioni ufficiali raddoppia. Per catturare l'influenza del degrado muscolare nelle previsioni individuali, è stata sviluppata una metrica di degradazione muscolare basata sul confronto dell'output con e senza la maschera di Poisson iniziale. Questa metrica è il rapporto normalizzato della previsione con e senza maschera.
La maschera di Poisson M applicata su un punto (Ix) MFCC della registrazione viene calcolata moltiplicando questo valore per un valore casuale della distribuzione di Poisson Poiss() di parametri Ix e λ, dove λ è la media di tutti i valori in MFCC.
M(Ix) = Poiss(λ) · Ix dove Poiss(X = k) = (λk e-k)/k!
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2022 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.




