Descriviamo in questo articolo l'architettura ARM, ampiamente diffusa tra i sistemi embedded grazie, appunto, alle sue caratteristiche. Architettura RISC a basso consumo elettrico, le cui istruzioni Assembly vengono eseguite con pochi cicli di clock, spesso con un solo ciclo. Anche se nella stragrande maggioranza dei casi questi dispositivi vengono programmati con linguaggi di alto livello, è sempre utile conoscere il linguaggio Assembly che in certi casi risulta un ottimo strumento di programmazione. Per esempio, nella creazione di funzioni di startup, di verifica funzionamento hardware interno al micro, e quando si richiedono massime prestazioni a livello software.
ARM Cortex core
La storia dei processori ARM inizia nel lontano 1983 nella sezione ricerca e sviluppo della Acorn Computers Ltd, dove fu realizzato un primo prototipo dell'ARM1, anche se a livello commerciale il primo processore ad essere distribuito sul mercato fu l'ARM2, nel 1986. Da lì in poi sono stati sviluppati e prodotti diversi modelli anche se la svolta avvenne nel 1991 con la distribuzione dell'ARM6 che fu sviluppato in collaborazione con la Apple che, infatti, integrò sui suoi personal computer l'ARM 610. Note storiche a parte, torniamo appunto a parlare degli ARM Cortex che, come accennato nell'introduzione di questo articolo, sono attualmente impiegati nella maggior parte dei dispositivi embedded. Questa famiglia venne alla luce nel 2005, ed è basata sul set di istruzioni ARM7v, disponibili in configurazione a singolo core o a più core.
Tipologie di Core
La famiglia dei processori ARM Cortex si divide in 4 tipologie differenti:
- serie A (Application): famiglia destinata ad applicazioni di elevata complessità, su cui è possibile installare un sistema operativo, in genere multi-utente articolato e complesso tipo Linux. In questo articolo non parlo di questi microprocessori, ma rimando comunque ad un altro link per chi volesse approfondimenti sulle loro potenzialità;
- serie R (Real-time): molto simile alla serie A, quindi destinato ad applicazioni ad alta velocità, ma con caratteristiche più orientate ad applicazioni hard real-time;
- serie M: questa serie di processori è destinata alla creazione di core per microcontrollori. Quindi, per applicazioni embedded, garantiscono una elevata efficienza energetica e basso costo; questi core sono in genere prodotti in milioni e distribuiti su milioni di dispositivi. Si dividono in diverse tipologie di core: Cortex-M0, Cortex-M0+, Cortex-M1, Cortex-M3, Cortex-M4, Cortex-M7, Cortex-M23, Cortex-M33, Cortex-M35P, Cortex-M55, dove i core Cortex-M4, Cortex-M7, Cortex-M33, Cortex-M35P ed infine il Cortex-M55, sono dotati dell'FPU (Floating Point Unit); parleremo quindi di Cortex-MxF;
- serie SecureCore: questa serie è basata sulla serie M, ma destinata ad applicazioni di sicurezza.
Di seguito si riporta una piccola tabella con tutti i core Cortex-M e relative caratteristiche fondamentali:
| Core Cortex ARM | Architettura | Numero stadi pipeline | Instruction set |
| ARM Cortex-M0 | ARMv6-M | 3 stadi | Thumb-1 (non tutte)
Thumb-2 (non tutte) |
| ARM Cortex-M0+ | ARMv6-M | 2 stadi | Thumb-1 (non tutte)
Thumb2(non tutte) |
| ARM Cortex-M1 | ARMv6-M | 3 stadi con branch prediction | Thumb-1
Thumb-2 |
| ARM Cortex-M3 | ARMv7-M | 3 stadi con branch speculation | Thumb-1
thumb-2 |
| ARM Cortex-M4 | ARMv7E-M | 3 stadi con branch speculation | Thumb-1
Thum-2 DSP |
| ARM Cortex-M7 | ARMv7E-M | 6 stadi con branch speculation | Thumb-1
Thum-2 DSP |
| ARM Cortex-M23 | ARMv8-M | 2 stadi | TrustZone
|
| ARM Cortex-M33 | ARMv8-M | 3 stadi | TrustZone
DSP |
| ARM Cortex-M55 | ARMv8.1-M | 4 stadi | diverse
DSP |
I core ARM Cortex-M55 ancora non hanno una grande diffusione, mentre i core ARM Cortex-M35P sono essenzialmente molto simili ai core ARM Cortex-M33. Il più noto Instruction Set ARM a 32 bit nel Cortex-M non viene mai impiegato.
Vediamo ora di descrivere brevemente le varie tipologie di istruzioni, anche in riferimento al loro utilizzo all'interno dei vari core Cortex:
- Thumb-1: set di istruzioni a 16-bit, essenzialmente caratterizzato da un basso numero di istruzioni. Infatti, solo i salti possono essere condizionati mentre tutte le altre istruzioni no. Ottimo compromesso in tutti quei sistemi in cui non si dispone di una grande larghezza di banda. I core Cortex-M0 ed M0+ non dispongono di tutte le istruzioni. Mancano, infatti, delle istruzioni CBZ, CBZN ed IT.
- Thumb-2: set di istruzioni più ampio del precedente, in questo caso le istruzioni possono essere sia a 16-bit che a 32-bit. Tutte le istruzioni possono essere condizionate. Ottimo compromesso tra performance e larghezza di banda, dovuto all'utilizzo delle istruzioni a 32 bit solo per le operazioni che richiedono maggiore complessità. Esistono anche diverse istruzioni che permettono operazioni bit a bit. Potremmo riassumere che le istruzioni Thumb-2 permettono di avere una densità di codice simile alle Thumb-1, mantenendo comunque una potenzialità di calcolo molto simile a un set istruzioni a 32-bit. I core Cortex-M0 ed M0+ non sono dotati del set completo di istruzioni, hanno infatti unicamente BL, DMB, DSB, ISB, MRS, MSR.
- DSP: come già accennato in precedenza, molti core ARM Cortex-M sono dotati di alcune istruzioni DSP per migliorare le performance nelle applicazioni digital signal processing. Questi core sono dotati, inoltre, molto spesso di unità floating point (FPU). Ricordo brevemente i core dotati di questa caratteristica: ARM Cortex-M4, ARM Cortex-M7, ARM Cortex-M33, ARM Cortex-M35P e ARM Cortex-M55. Da notare l'importanza della coesistenza di istruzioni DSP con le usuali istruzioni della CPU. Nel link viene presentata una tematica analoga anche se in questo caso non si parla di ARM.
- TrustZone: questo set di istruzioni già presente nei core ARM Cortex-A viene integrato anche negli ultimi core Cortex-M, vengono impiegate a partire dall'architettura ARMv8. Sono estremamente utili in tutte quelle applicazioni di sicurezza, infatti, riducono il potenziale di attacco andando ad isolare quella parte di firmware che a livello di sicurezza risulta critica, come il boot, l'update del firmware e le chiavi di sicurezza. Questa parte in questo articolo non verrà trattata.
Prima di proseguire parlando di ortogonalità delle istruzioni, è opportuno spiegare velocemente il Branch Prediction e Branch Speculation:
- Branch Prediction: in informatica, la predizione delle diramazioni (branch prediction), compito delegato alla BPU (Branch Prediction Unit), una componente della CPU che cerca di prevedere l'esito di un'operazione su cui si basa l'accettazione di una istruzione di salto condizionato, evitando rallentamenti che possono essere molto evidenti in una architettura con pipeline.
- Branch Speculation: l'esecuzione speculativa (in inglese: speculative execution) è una tecnica di ottimizzazione che consiste nel fare eseguire al computer operazioni che potrebbero essere necessarie solo in un secondo tempo. Elaborando i dati prima di sapere se è davvero necessario farlo, può ridurre i ritardi che si avrebbero facendo il lavoro solo dopo aver saputo se è davvero necessario o meno. Se ad un certo momento del flusso di esecuzione il lavoro svolto anticipatamente si dimostra inutile, allora i risultati ottenuti verranno semplicemente ignorati.
Ortogonalità
Una cosa che viene fatta quasi sempre quando si parla di architetture RISC è quella di confrontarle con le architetture CISC. Ovviamente, questo esula leggermente dallo scopo di questo articolo. Ma, comunque, è impossibile parlare di ortogonalità senza entrare in merito alle differenze tra le due architetture. Intanto, andiamo a definire cosa si intende per ortogonalità, caratteristica tipica dei core ARM Cortex. Un'architettura è ortogonale quando tutte le istruzioni hanno la stessa lunghezza, questa proprietà garantisce una maggiore regolarità, permettendo l'allineamento in memoria, consentendo così di aumentare la velocità di esecuzione. L'OPCODE delle istruzioni sarà sempre strutturato nello stesso modo, quindi la lunghezza dei relativi campi sarà sempre la stessa. Come accennato, questa è una caratteristica in genere delle architetture RISC, mentre le architetture CISC sono caratterizzate dall'avere centinaia di istruzioni tutte di diversa dimensione.
Architettura dei processori ARM Cortex
Tipi di Dati
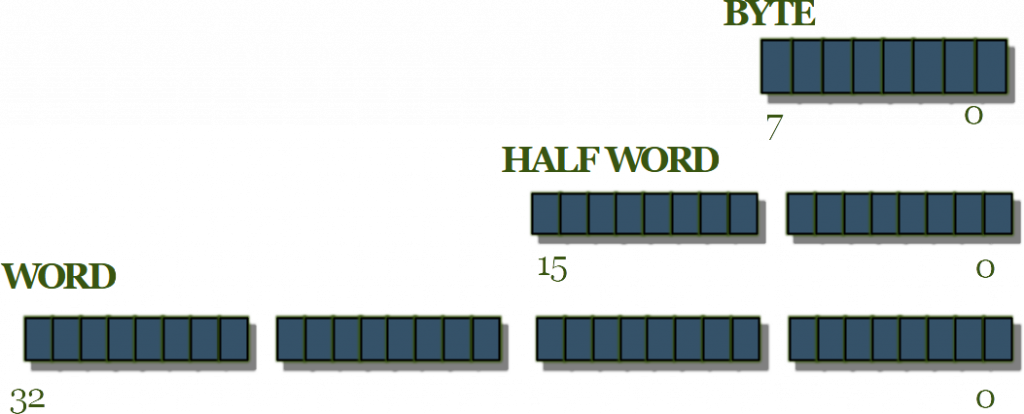
Figura 1. I dati possono essere scritti sui registri sia come byte, come half-word e come word
Similmente ai linguaggi di alto livello, come il linguaggio C, anche per l'Assembly i dati sono caratterizzati dal tipo. Essenzialmente, per quanto riguarda gli ARM Cortex i tipi possono essere byte, half-word o word, in tutti questi casi i dati possono essere signed o unsigned (con segno o senza segno). Ovviamente, la prima distinzione dipende dal numero di byte utilizzato per rappresentare il dato, avremmo rispettivamente 1 byte, 2 byte o 4 byte. Essenzialmente, bus degli indirizzi così come quello dei dati è a 32 bit (4 byte), da ciò consegue che le operazioni di load e store sulla memoria potranno arrivare anche a scrivere una word con un'unica istruzione. Se vogliamo scrivere un byte in memoria dovremmo utilizzare il suffisso b alle istruzioni load e store, ottenendo ldrb e strb; se invece volessimo scrivere una half-word utilizzeremo il suffisso h ottenendo così le istruzioni ldrh e strh. Invece le word non richiedono nessun suffisso. Per indicare un dato con segno, sarà necessario utilizzare il suffisso s. Di seguito un breve riassunto delle possibili istruzioni di load e store.
| ldr | Load word |
| ldrh | Load halfword |
| ldrsh | Load signed halfword |
| ldrb | Load byte |
| ldrsb | Load signed byte |
| str | Store word |
| strh | Store halfword |
| strsh | Store signed halfword |
| strb | Store byte |
| strsb | Store signed byte |
Vediamo ora alcuni esempi per capire meglio le funzionalità di queste istruzioni:
LDRB R2, =0x0B @ viene inserito il byte 0x0B nel registro R2
LDRH R2, [R1, #5] @ viene caricato dall'indirizzo contenuto di R1 sommato a 5
@ il contenuto del registro R2
STRSB R1, [R2] @ viene caricato nel registro R1 un byte presente all'indirizzo
@ di memoria contenuto in R2
Prima di terminare la parte inerente ai dati, è opportuno parlare della Endianess dei core Cortex. In pratica questa caratteristica del microprocessore ci dice in che ordine vengono memorizzati i dati in memoria. Esistono diverse tipologie di Endianess, ma essenzialmente le 2 principali tipologie sono:
- Little Endian: utilizzato in genere nelle famiglie x86, CISC. Il byte meno significativo viene memorizzato all'indirizzo più basso in memoria.
- Big Endian: in questo caso invece è il byte più significativo ad essere memorizzato all'indirizzo meno significativo.
Come accennato, i processori x86 sono Little Endian, gli ARM invece erano di questo tipo fino alla versione ARMv3, da lì in poi sono diventati Big Endian, anche se gli ARMv6 utilizzano entrambe le tipologie, a seconda del campo M del registro di stato.
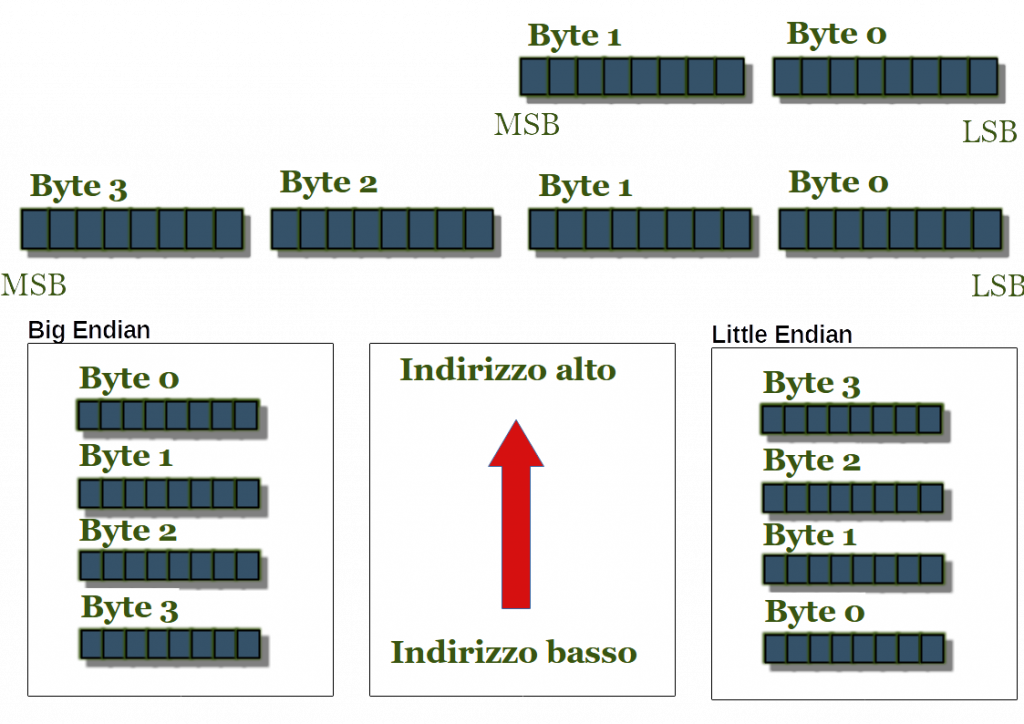
Figura 2. Modalità Big Endian e Little Endian
Registri
Essenzialmente il numero dei registri dipende dal core ARM in esame, anche se in via generica i core ARM sono caratterizzati dall'avere 30 registri General Purpose, eccetto che per i core ARMv6 e ARMv7. Per tutte le versioni i primi 16 registri vengono utilizzati nella modalità utente (User), mentre gli altri nella modalità privilegiata (eccetto ovviamente ARMv6 e AMRv7). Prima ho parlato di registri General Purpose, senza però andare a specificare di cosa si tratta. Questi registri sono, in pratica, registri utilizzati un pò per tutte le istruzioni, quindi potremmo anche definirli ad uso generico. Al contrario, esisteranno dei registri per istruzioni specifiche, detti anche Special Purpose Register.

Figura 3. Registri architettura ARM
In questo articolo, comunque, andremo ad analizzare tutti i registri che non vengono eseguiti in modalità privilegiata. Di seguito, viene riportato un breve specchietto dei registri principali: [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 3307 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:

Dalla scatola al prodotto finito: come integrare le enclosure Takachi nel progetto di un dispositivo elettronico

Bluetooth NLC: il nuovo standard per l’illuminazione smart
Droni e normativa: chi può pilotare un drone, cosa si può e cosa non si può fare
Dai LED wearables al mantello dell’invisibilità

L’architettura dei sistemi IoT
