
L’algoritmo K-Nearest Neighbors (KNN) è uno dei metodi più semplici ed efficaci nel campo del Machine Learning supervisionato. Utilizzato principalmente per la classificazione e, in alcuni casi, per la regressione, KNN si basa sul confronto diretto tra osservazioni per prendere decisioni intelligenti. In questo articolo esploriamo come funziona KNN, quali sono i suoi vantaggi, le sue limitazioni e come può essere applicato in contesti reali come la diagnostica medica, la sicurezza informatica ed i sistemi di raccomandazione. Scoprirai anche le migliori pratiche per migliorare le prestazioni dell’algoritmo, come la normalizzazione dei dati, la scelta ottimale del parametro k e l’uso di metriche di distanza personalizzate. Che tu sia uno sviluppatore, un data scientist o uno studente, questo articolo ti fornirà una panoramica chiara sull’algoritmo K-Nearest Neighbors per aiutarti a sfruttarlo al meglio nei tuoi progetti di Intelligenza Artificiale.
Panoramica introduttiva
L’algoritmo K-Nearest Neighbors, comunemente abbreviato in KNN, rappresenta una delle tecniche fondamentali nell’ambito del Machine Learning supervisionato. Si distingue per la sua semplicità concettuale e per la capacità di produrre risultati accurati in molteplici contesti applicativi, senza la necessità di un modello predittivo addestrato in maniera esplicita. L'algoritmo K-Nearest Neighbors viene utilizzato sia per la classificazione che per la regressione, anche se è nella classificazione che mostra il suo maggiore potenziale. Il principio alla base del metodo è intuitivo: osservare gli esempi più simili ad un dato punto e usare queste informazioni per predire un’etichetta o un valore. La semplicità dell’approccio che lo contraddistingue, rende KNN una scelta popolare nei sistemi dove è importante avere un algoritmo interpretabile, facilmente adattabile e che non richiede lunghi tempi di addestramento. L’assenza di assunzioni forti sulla distribuzione dei dati offre, inoltre, una certa flessibilità in scenari reali, dove i dati sono spesso imperfetti o poco strutturati.

Figura 1
Principio di funzionamento
Il nucleo del funzionamento di KNN si basa sul concetto di vicinanza nello spazio delle caratteristiche. Quando si deve assegnare una classe o stimare un valore per un nuovo punto, l’algoritmo confronta tale punto con l’intero dataset di addestramento e seleziona i k esempi più vicini, cioè quelli che si trovano alla distanza minima secondo una metrica scelta. La distanza euclidea è la più utilizzata, soprattutto quando le caratteristiche sono numeriche e normalizzate, ma in altri casi possono essere impiegate metriche come la distanza di Manhattan o la distanza di Minkowski, a seconda della natura del problema e delle caratteristiche dei dati. Una volta trovati i k vicini, l’algoritmo procede in modo semplice: nella classificazione, assegna al nuovo punto la classe più frequente tra i vicini; nella regressione, calcola una media dei valori. Sebbene il meccanismo sembri semplice, l'efficacia del modello dipende da scelte strategiche, come il valore di k. Un valore troppo basso può introdurre variabilità e rumore, mentre un valore troppo alto tende ad attenuare le differenze tra le classi. La selezione ottimale di k viene solitamente effettuata tramite metodi di validazione incrociata, che permettono di valutare la performance del modello su diverse suddivisioni del dataset.
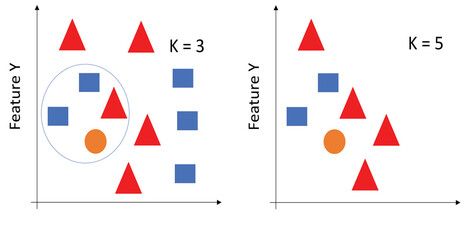
Figura 2: Clustering utilizzando l'algoritmo KNN con diversi valori di K (Fonte: Adobe Stock)
Pre-elaborazione dei dati e normalizzazione
Poiché l’algoritmo si basa su calcoli di distanza, è essenziale che tutte le caratteristiche abbiano lo stesso ordine di grandezza. Senza una normalizzazione, le variabili con scale numeriche maggiori dominerebbero il calcolo della distanza, alterando la reale somiglianza tra i punti. Un esempio comune è quello di un dataset in cui si confrontano altezza in centimetri e reddito in euro: la seconda variabile, per via dei valori più alti, potrebbe influenzare sproporzionatamente il risultato. Per evitare questo tipo di problemi, si ricorre alla normalizzazione dei dati. Le tecniche più comuni includono la standardizzazione, che trasforma ogni variabile in una distribuzione con media zero e deviazione standard uno, oppure la normalizzazione min-max, che scala i valori in un intervallo prestabilito, solitamente tra 0 e 1. Oltre alla normalizzazione, un'altra fase importante è la selezione delle caratteristiche. Includere troppe variabili non rilevanti o altamente correlate può portare a risultati poco affidabili, poiché l’algoritmo potrebbe “distrarsi” rispetto agli attributi realmente informativi. Tecniche di selezione automatica delle feature, come l’analisi della varianza o l’utilizzo di modelli wrapper, aiutano a costruire rappresentazioni dei dati più efficaci e significative.
Vantaggi dell’algoritmo KNN...
Tra i principali punti di forza del K-Nearest Neighbors spicca la semplicità di implementazione. Non richiede una fase di addestramento complessa, né presuppone conoscenze avanzate sulla struttura dei dati, rendendolo accessibile anche a chi si avvicina per la prima volta al Machine Learning. La facilità con cui può essere compreso e spiegato lo rende anche uno strumento utile in ambito didattico. Dal punto di vista pratico, KNN può essere rapidamente adattato a nuove osservazioni o a dataset in continua evoluzione, senza dover essere riaddestrato. In contesti dinamici, come quelli legati ai flussi di dati in tempo reale, questo rappresenta un vantaggio chiave. Si tratta di un algoritmo non parametrico, ovvero non assume una distribuzione dei dati sottostante, e per questo motivo si comporta bene in situazioni in cui le relazioni tra le variabili sono complesse o non lineari. La sua flessibilità consente l’applicazione in ambiti molto diversi, dal riconoscimento delle immagini alla previsione delle preferenze degli utenti, fino a casi di classificazione medica e rilevamento delle frodi.
...ma anche limitazioni
Nonostante i vantaggi, KNN presenta alcune debolezze importanti. L’assenza di una fase di apprendimento significa che l’algoritmo deve memorizzare tutto il dataset di addestramento e utilizzarlo ogni volta che deve effettuare una previsione. In presenza di grandi quantità di dati, questo approccio si traduce in elevati costi computazionali e lunghi tempi di risposta, rendendo il metodo inadatto a contesti dove la velocità di classificazione è fondamentale. Anche la memoria richiesta può diventare un problema, soprattutto su dispositivi a capacità limitata o in ambienti cloud dove l’efficienza ha un impatto diretto sui costi. Un altro limite è legato alla sensibilità ai dati rumorosi e agli outlier. Un solo dato anomalo, se particolarmente vicino al punto da classificare, può influenzare la decisione dell’algoritmo in modo significativo, inoltre, in spazi ad alta dimensionalità, il concetto di “distanza” tende a perdere di significato a causa del fenomeno della “maledizione della dimensionalità”, che riduce la discriminabilità tra i punti e abbassa l’accuratezza del modello.
Applicazioni pratiche del K-Nearest Neighbors
L’impiego dell’algoritmo KNN è molto variegato e copre numerosi ambiti operativi. Nella diagnostica medica, ad esempio, è utilizzato per classificare pazienti sulla base di sintomi, parametri clinici o esami strumentali per un supporto a decisioni critiche in contesti ospedalieri. Nell’ambito della sicurezza informatica, può servire per identificare comportamenti sospetti analizzando le caratteristiche delle attività di rete, confrontandole con attività precedentemente etichettate come lecite o fraudolente. Anche nei sistemi di raccomandazione, come quelli impiegati da piattaforme di streaming o e-commerce, KNN viene applicato per suggerire prodotti o contenuti sulla base delle preferenze di utenti simili. Ulteriori applicazioni si riscontrano nel riconoscimento vocale, nella classificazione di testi, nel clustering di dati e nell’analisi del sentiment, grazie alla sua capacità di trattare in modo efficiente anche rappresentazioni testuali o simboliche. Ogni implementazione, naturalmente, richiede un’attenta progettazione delle caratteristiche da utilizzare, affinché il concetto di “vicinanza” rispecchi effettivamente la similarità tra le entità osservate.
Ottimizzazione e varianti
Per superare i limiti computazionali e migliorare le prestazioni, sono state sviluppate numerose ottimizzazioni dell’algoritmo. Una delle più comuni consiste nell’utilizzo di strutture dati avanzate come KD-Tree, Ball Tree o LSH (Locality-Sensitive Hashing), che permettono una ricerca dei vicini più rapida anche in spazi complessi. Alcune versioni pesano i vicini in base alla distanza, attribuendo maggiore importanza ai punti più prossimi al campione da classificare. In questo modo, si riduce il rischio che elementi più lontani, ma appartenenti a classi maggioritarie, influenzino il risultato in modo scorretto. L’integrazione con tecniche di riduzione dimensionale, come PCA (Principal Component Analysis), consente inoltre di migliorare l’efficienza e la precisione, specialmente in dataset con molte variabili. Anche l’ibridazione con altri algoritmi, come i modelli basati su reti neurali o metodi ensemble, può offrire risultati superiori, mantenendo la trasparenza e l’adattabilità che caratterizzano KNN.
Considerazioni conclusive
L’algoritmo K-Nearest Neighbors continua a rappresentare una risorsa preziosa nel panorama degli strumenti di Machine Learning. La combinazione di semplicità, versatilità e interpretabilità lo rende ideale in molte situazioni, sia in fase esplorativa che in contesti produttivi. Sebbene non sia adatto ad ogni problema, un uso consapevole, accompagnato da tecniche di ottimizzazione e da una buona conoscenza del dominio, permette di sfruttarne appieno il potenziale. Con l’evoluzione delle tecnologie e la disponibilità di risorse computazionali sempre più potenti, KNN mantiene un ruolo centrale tra gli algoritmi più efficaci, in grado di offrire una solida base per affrontare problemi di classificazione e regressione anche complessi.
Sei interessato ad ulteriori approfondimenti?
Ecco un utilissimo link di supporto per approfondire la tematica: What is the k-nearest neighbors algorithm? | IBM



