
L'undicesima lezione del corso avanzato sul linguaggio C per Raspberry Pi esplora gli ambiti di utilizzo delle variabili. Queste si possono creare per essere utilizzate solo in una funzione o, al contrario, possono avere una visibilità molto più ampia. Esploriamo le varie tecniche descrivendo, anche, alcuni metodi per la rapida conversione di tipo.
Introduzione
Negli esempi proposti nelle precedenti puntate abbiamo utilizzato molte variabili, di diversi tipi, ma non abbiamo mai focalizzato sul loro ciclo di vita. Allo scopo occorre distinguere i due seguenti concetti:
- life time: è, appunto, il tempo di vita di ogni variabile nel quale essa rimane in memoria durante l'esecuzione del programma;
- scope: chiamata anche visibilità della variabile, è la parte del programma in cui essa risulta visibile e utilizzabile. Le variabili possono essere locali e globali.
Le variabili locali
Probabilmente le più utilizzate, le variabili locali sono quelle dichiarate all'interno di una funzione o di un blocco. Esse, dunque, possono essere accessibili, ossia utilizzabili, solo dentro l'ambito di definizione. Quando la funzione termina, le variabili in esse dichiarate sono distrutte.
Iniziamo con un semplice esempio.
#include "stdio.h"
int main() {
int n; /* Questa e' una variabile locale nella funzione main */
n = 55;
printf("Siamo nella funzione main() e la variabile 'n' vale %d\n",n);
miafunzione();
return 0;
}
int miafunzione() {
int k; /* Questa e' una variabile locale nella funzione miafunzione */
k = 2018;
printf("Siamo nella funzione miafunzione() e la variabile 'k' vale %d\n",k);
return 0;
}
Nel programma di cui sopra esiste la funzione main() e la funzione miafunzione(). In ognuna di esse sono dichiarate, inizializzate e visualizzate, rispettivamente, le variabili "n" e "k". Esse sono totalmente indipendenti tra loro e non si interferiscono reciprocamente in alcun modo. Abitano, praticamente, in due stanze diverse di una casa, come ben evidenziato in figura 1.

Figura 1: due variabili locali non si disturbano a vicenda
L'output del programma è il seguente:
#include "stdio.h"
int main() {
int n; /* Questa e' una variabile locale nella funzione main */
n = 55;
printf("Siamo nella funzione main() e la variabile 'n' vale %d\n",n);
miafunzione();
mianuovafunzione();
return 0;
}
int miafunzione() {
int n; /* Questa e' una variabile locale nella funzione miafunzione */
n = 2018;
printf("Siamo nella funzione miafunzione() e la variabile 'n' vale %d\n",n);
return 0;
}
int mianuovafunzione() {
int n; /* Questa e' una variabile locale nella funzione mianuovafunzione */
n = 23456;
printf("Siamo nella funzione mianuovafunzione() e la variabile 'n' vale %d\n",n);
return 0;
}
L'output del programma è il seguente:
L'esempio che segue chiarirà ancora meglio il concetto, circa l'allocazione e la deallocazione delle variabili in memoria. Il listato esegue, sequenzialmente, alcuni passaggi:
- nella funzione main():
- dichiara la variabile "n";
- le assegna il valore 23;
- stampa il suo indirizzo e il suo contenuto: 0xbe9b3f94 e 23;
- invoca la funzione funzione1();
- dichiara la variabile "n";
- le assegna il valore 1967;
- stampa il suo indirizzo e il suo contenuto: 0xbe9b3f84 e 1967;
- invoca la funzione funzione2();
- dichiara la variabile "n";
- le assegna il valore 12345;
- stampa il suo indirizzo e il suo contenuto: 0xbe9b3f84 e 12345;
- invoca la funzione funzione3();
- dichiara la variabile "n";
- le assegna il valore 69;
- stampa il suo indirizzo e il suo contenuto: 0xbe9b3f84 e 69.
#include "stdio.h"
int funzionel();
int funzione2();
int funzione3();
int main() {
int n;
n=23;
printf("Indirizzo: %p %d\n",&n,n);
funzione1();
funzione2();
funzione3();
return 0;
}
int funzione1() {
int n;
n=1967;
printf("Indirizzo: %p %d\n",&n,n);
return 0;
}
int funzione2() {
int n;
n=12345;
printf("Indirizzo: %p %d\n",&n,n);
return 0;
}
int funzione3() {
int n;
n=69;
printf("Indirizzo: %p %d\n",&n,n);
return 0;
}
Come è possibile che le variabili "n" della seconda, terza e quarta funzione sono sempre memorizzate allo stesso indirizzo? Per via del riutilizzo della memoria. Nella funzione main(), infatti, è riservato dello spazio per la variabile "n", all'indirizzo 0xbe9b3f94. Quindi, nella funzione funzione1() è riservato un ulteriore spazio per un'altra variabile "n", all'indirizzo 0xbe9b3f84, dal momento che la prima variabile "è ancora in vita". Quando la funzione1() ha termine, la variabile all'indirizzo 0xbe9b3f84 viene "distrutta" e il relativo indirizzo è reso disponibile per gli usi successivi. Questo è il motivo per cui la variabile "n" della funzione2() e della funzione3() sono allocate sempre nel medesimo posto (vedi figura 2).
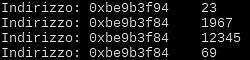
Figura 2: le variabili possono essere distrutte e lo spazio in memoria è reso nuovamente disponibile
Non è possibile, in modo normale, accedere e gestire una variabile locale, da una funzione all'altra. Il successivo esempio, illustrato chiaramente in figura 3, mostra come un tentativo di accesso "fuori stanza" causi un errore di compilazione.

Figura 3: non è possibile accedere alle variabili locali di altri blocchi o funzioni
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2282 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:

Alla scoperta dell’ESP32
Ambiente di sviluppo Keil μVision 5 – Descrizione e Approfondimenti

Progettazione e simulazione di veicoli virtuali nel cloud: ottimizzare i flussi di lavoro con MATLAB e Simulink

Indipendentemente dal linguaggio di programmazione utilizzato, la visibilità delle variabili è un punto dolente su cui il programmatore dovrebbe porre la massima attenzione. Molti errori di programmazione dipendono proprio da questo fattore.
Quella della dichiarazione delle variabili all’interno delle funzioni è una delle fasi più importanti di un linguaggio di programmazione e richiede la massima conoscenza e attenzione da parte del programmatore. Per ciò che riguarda il linguaggio C, uno degli aspetti che lo rende facilmente implementabile è la semplicità nella lettura delle linee di codice.
Anche le operazioni di casting sono molto utili. Nel linguaggio “D” (non “C”), tale aspetto è stato ulteriormente migliorato.
Ciao Giovanni, leggo sempre i tuoi articoli con molto interesse perché li trovo ricchi di spunti, oltre ad essere chiari e soprattutto dall’alto contenuto pratico. Anche quando i concetti esposti sono noti, articoli concisi e diretti come i tuoi possono servire da vademecum per rinfrescare nel tempo i contenuti degli stessi. Complimenti per la chiarezza.
Venendo all’articolo, trattare con le variabili sta alla base delle competenze di un programmatore, qualunque sia il linguaggio di programmazione al quale ci si affida. In particolare, quando il listato inizia a diventare complicato e strutturato per procedure, metodi e funzioni, operare con le variabili globali è spesso sconsigliato, perché si rischia di incorrere in errori di esecuzione difficili da debuggare a causa di flussi dati “globali” scritti e sovrascritti dalle varie funzioni.
Attualmente, sia per esigenze di progetto con la Raspberry PI ma anche per imparare un nuovo linguaggio di programmazione, mi sto approcciando al Python. Quest’ultimo, a differenza ad esempio del C, ha una dichiarazione delle variabili, lasciami passare il termine, “implicita”, dove il tipo è dettato letteralmente dal formato del valore attribuito alla variabile stessa. Anche il casting tra formati numerici avviene spesso in maniera trasparente, semplicemente curando la formattazione del dato stesso. Ma tolto l’aspetto della dichiarazione delle variabili, specifico del linguaggio, a rimarcare quanto possa essere sensibile ad errori un listato basato sulla modifica delle variabili globali, per accedere con operazioni di modifica a tali variabili tramite funzioni, in Python è necessario anteporre al codice delle funzioni la parola chiave “global” seguita dal nome della variabile globale su cui intendiamo operare. Questo modo di fare costringe il programmatore a prendere consapevolezza che ad una funzione in ambito locale si sta dando accesso ad un ambito globale con tutti i rischi associati a questo modo di programmare. Una sorta di disclamer in cui il linguaggio si solleva da ogni responsabilità su eventuali malfunzionamenti del codice dettati da un’architettura dello stesso tutto sommato non così curata. Io la vedo così! 😉
Grazie per questo articolo molto interessante. Oltre alla visibilità delle variabili, un problema che spesso mi pongo riguarda il numero di caratteri per nominare una data variabile. Vedo che molti programmatori preferiscono usare nomi corti, fino ad un solo carattere (es. k=8 o n= 10), mentre altri programmatori usano nomi di variabili molto lunghi. Da un punto di vista della occupazione di memoria non penso vi siano differenze, mentre da un punto di vista della leggibilità del codice penso vi possano essere delle considerazioni da fare in fase di scelta. Personalmente, cerco sempre di impiegare nomi lunghi e autoesplicativi per le variabili. Fra l’altro scegliere dei nomi lunghi mi dà la possibilità di cambiare rapidamente il nome con un semplice find & replace, cosa che invece risulta meno immediata se il nome della variabile è composto da uno o due caratteri. Ovviamente cerco di non eccedere nel senso opposto (es. per un semplice contatore evito di dichiarare variabili del tipo contatore_iterazioni = 1!). Mi chiedo se esistano delle regole in merito. Grazie ancora.
Se posso contribuire alla risposta, esistono delle Style Guide di programmazione che danno delle dritte proprio sullo stile di stesura del codice, fornendo in alcuni casi delle vere e proprie regole di buona programmazione. Tali regole in alcuni casi semplificano la lettura del codice, in altri migliorano l’ottimizzazione del codice stesso, quindi impattando anche su velocità di esecuzione delle istruzioni (utilizzare il for loop potrebbe essere più ottimizzato del do-while ecc…). Ti riporto il link alla Style Guide per la programmazione di Arduino (purtroppo in inglese)
https://www.arduino.cc/en/Reference/StyleGuide
Nella suddetta guida troverai alcune regole anche per la dichiarazione di costanti e variabili.
Grazie mille per la risposta e per il link!