
Questo articolo introduce la problematica dello studio dei sistemi real-time in situazioni di sovraccarico, ovvero in quelle situazioni in cui la capacità di calcolo richiesta al sistema eccede il tempo a disposizione. L'articolo illustra il comportamento dei sistemi real-time in queste condizioni limite, consigliando una serie di possibili azioni correttive.
Gli effetti indesiderati legati ad una condizione di sovraccarico sono legati all’esecuzione di task critici oltre i limiti temporali richiesti dall’applicazione. La figura 1 mostra un sistema composto da 3 task. Nel caso a), il sistema funziona correttamente.
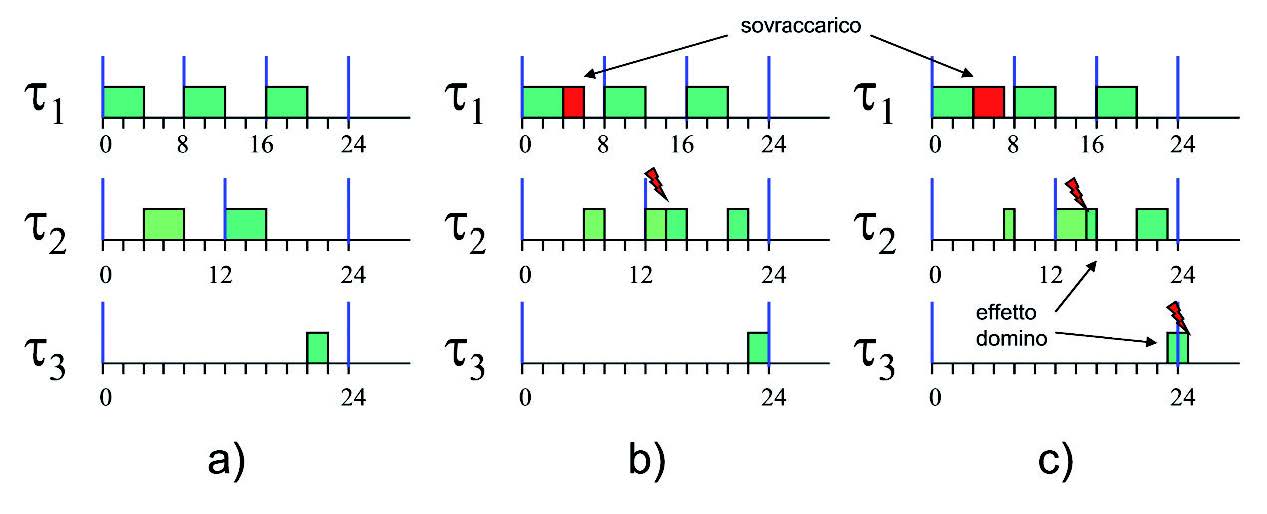
Figura 1: esempio di sovraccarico.
Una situazione di sovraccarico sul primo task (caso b) può provocare il mancato rispetto dei vincoli temporali da parte del task t2 (notare come non è vero che in caso di sovraccarico sono sempre i task a più bassa priorità ad essere penalizzati: il task t 3 infatti continua a rispettare i propri vincoli temporali). Tale situazione può potenzialmente compromettere il funzionamento del sistema, provocando potenzialmente un effetto domino, in cui si verifica un malfunzionamento a cascata (caso c). Consideriamo adesso un esempio applicativo legato al controllo di velocità di un motore. Supponiamo che l’applicativo di controllo sia composto da tre task, uno ad alta priorità attivato dalla rotazione dell’albero motore tramite un interrupt generato un encoder, uno di gestione del sistema a priorità intermedia, ed uno a bassa priorità. Il task a bassa priorità si occupa di leggere tramite una periferica A/D un potenziometro che regola la velocità del motore. All’aumentare della velocità del motore, il carico computazionale del sistema aumenterà (aumentano il numero degli interrupt dell’encoder, e quindi le attivazioni del task ad alta priorità), fino potenzialmente a sovraccaricare il sistema. Quale è il comportamento del sistema in questo caso? In un algoritmo di schedulazione a priorità fissa, come Rate Monotonic, possiamo notare come, in caso di sovraccarico, i task a più bassa priorità vengono penalizzati e possono non eseguire. Consideriamo la figura 2 in alto.
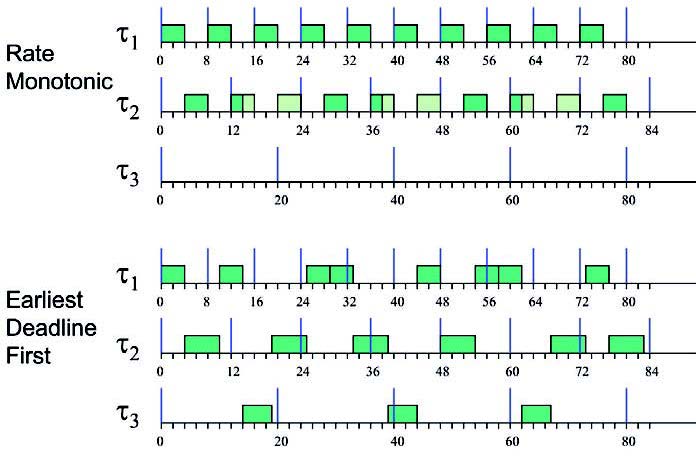
Figura 2: comportamento di RM ed EDF in condizioni di sovraccarico.
La figura, in particolare, mostra un esempio di schedulazione di un sistema composto da tre task, τp = (Ci,Ti) con le seguenti caratteristiche: τi = (4,8), τ2 = (6,12), τ3 = (5,20).
Il sistema ricalca la situazione di sovraccarico dell’esempio del motore fatto in precedenza. Notare come il sistema non è schedulabile, in quanto il fattore di utilizzazione del processore è pari a U = 1,25: tale fatto può essere notato in figura, in quanto il task τ3 a bassa priorità (ha il periodo più grande, che corrisponde nell’algoritmo rate Monotonic ad una priorità bassa) non esegue mai. A livello applicativo, l’effetto pratico è che la periferica A/D che campiona il potenziometro, a partire da una certa velocità del motore, non viene più letta. Ovvero, una volta raggiunta tale velocità critica il motore non potrà più essere fermato, in quanto il microcontrollore non leggerà più i valori di riferimento! Occorre notare come il comportamento appena descritto dipenda dall’algoritmo di scheduling utilizzato. Se consideriamo un algoritmo di scheduling a priorità dinamiche come EDF, il comportamento è decisamente diverso. In questo caso, ad esempio, tutti i task continuano ad eseguire ma con un periodo più basso, e non si verifica mai la situazione in cui un task non esegua a causa di un sovraccarico. In particolare, è stato dimostrato che in caso di sovraccarico (U>1) l’algoritmo di scheduling EDF esegue i task con un periodo medio Ti = TiU, ovvero di fatto i periodi dei task vengono “scalati” in proporzione.
Possibili soluzioni per risolvere problemi di sovraccarico
Alcune tipologie di problemi legati al sovraccarico possono essere risolte semplicemente aumentando la potenza computazionale del sistema in modo tale da garantire il rispetto dei vincoli temporali (questo corrisponde a riportare il fattore di utilizzazione del processore entro i limiti delle condizioni di schedulabilità). Non tutti i problemi di sovraccarico possono essere risolti in questo modo. Oltre alle ovvie considerazioni economiche causate dall’utilizzo di processori più potenti, nel caso del controllo motore descritto sopra aumentare la potenza di calcolo del sistema semplicemente incrementa la velocità critica a cui si verifica la perdita di esecuzione del task a bassa priorità. Esistono altre tecniche utilizzabili per mitigare gli effetti indesiderati dei sovraccarichi, che presentiamo di seguito.
Ottimizzazione delle performance applicative
La prima ovvia soluzione ai problemi di sovraccarico è quella di cercare di effettuare una ottimizzazione selettiva delle parti applicative che contribuiscono di più al carico del sistema. Di fronte ai primi problemi di sovraccarico, infatti, spesso si scopre che buona parte del tempo è spesa solo su di una piccola percentuale del codice applicativo (ad esempio, nel Mission Computer dell’aereo da caccia Hawk è stato possibile ridurre del in 23% il tempo di esecuzione del sistema solo ottimizzando l’1,2% del codice applicativo). Tali tipologie di ottimizzazione possono in generale essere guidate da strumenti specifici, tra i quali citiamo RapiTime ed AiT, che permettono di effettuare stime dei tempi di esecuzione del codice per guidare il processo di ottimizzazione.
Assegnamenti di priorità ad hoc
Un’altra strada che può essere percorsa per parzialmente evitare i problemi di sovraccarico è quella di selezionare un sottoinsieme delle attività a bassa priorità che sono ritenute fondamentali, e spostarle in un task separato con priorità più alta di quanto specificato dall’algoritmo Rate Monotonic. In generale tale azione riduce la schedulabilità del sistema in quanto non viene più utilizzato un assegnamento di priorità ottimo.
Admission control e degradazione delle performance
Un modo per evitare i sovraccarichi è quello di mantenere a livello applicativo una stima del carico utilizzato dall’applicazione. Tali stime possono essere utilizzate in vari modi. Un primo modo prevede l’utilizzo di un test di ammissione per decidere se poter accettare, posticipare o rifiutare richieste di esecuzione di particolari attività. Tale metodo non è sempre applicabile, in quanto le condizioni di sovraccarico si presentano spesso in situazioni di emergenza in cui alcune attività non possono essere posticipate.
Un altro modo per limitare il carico computazionale è quello di gestire in modo controllato la mancata esecuzione di alcuni task. Da un punto di vista pratico, infatti, molte implementazioni di algoritmi di controllo utilizzano frequenze di campionamento ben più elevate di quelle necessarie per garantire la stabilità del sistema, ed in alcuni casi la non esecuzione di istanze del sistema provoca un degradamento limitato delle prestazioni. Da questo punto di vista, sono stati studiati diversi metodi in letteratura che permettono di analizzare queste situazioni. Ne citiamo uno, denominato “Job skipping” che prevede l’esistenza di task che possono eseguire solo n istanze ogni m, con n<m (figura 3).

Figura 3: esecuzione di task con skip.
In questo caso, è possibile studiare il sistema per riuscire a garantire un numero di task maggiore sfruttando il tempo guadagnato dalla mancata esecuzione (“skip”) di uno o più task (per maggiori informazioni, il lettore interessato può fare riferimento a [5]). Un ultimo modo per gestire problemi di sovraccarico con degradazione delle performance è quello di implementare diverse versioni di un algoritmo, alcune più complesse e precise da utilizzare in momenti di esecuzione normale, altre più veloci ma meno accurate da utilizzare in situazioni di sovraccarico. A livello applicativo dovranno essere utilizzate opportune stime che permettano di scegliere l’algoritmo da utilizzare. Tali stime potranno essere effettuate online, stimando a runtime i tempi di esecuzione ed agendo con delle euristiche per limitare il carico del sistema, oppure offline, ponendo dei vincoli fissi dipendenti dal contesto che permettano di scegliere quale algoritmo utilizzare in ogni zona di lavoro. Esempi applicativi che riguardano le stime di carico online sono ad alcuni player DVD e televisioni digitali, che adottano diversi algoritmi di decompressione a seconda della qualità del filmato e delle attività in corso nel sistema (ad esempio, la qualità può essere ridotta in caso di attivazione di filtraggi particolari, Picture-In-Picture, ecc…). Da un punto di vista ingegneristico, questo ha senso in quanto permette, mantenendo una qualità finale accettabile, di utilizzare processori meno potenti che hanno minore dissipazione termica e quindi non necessitano di ventole. Un esempio di stima di calcolo offline è dato dagli algoritmi di controllo motore. Come abbiamo visto nell’esempio citato all’inizio dell’articolo, con l’aumentare della velocità aumenta il carico del sistema a causa del numero elevato di interrupt (viene generato un interrupt ad ogni rotazione dell’albero motore). Il sistema si trova per fortuna in una condizione favorevole, in quanto ad alto numero di giri il sistema diventa molto più semplice da controllare, per cui è possibile utilizzare algoritmi di controllo meno sofisticati che richiedono minor tempo di esecuzione. La soluzione tipicamente adottata in questi casi è quella di variare gli algoritmi utilizzati al raggiungimento di particolari velocità del motore, creando dei veri e propri “modi” operativi.
Resource Reservation
Le tecniche di Resource Reservation sono tecniche di scheduling innovative che possono essere utilizzate con successo per gestire problematiche di sovraccarico. Tali tecniche, che verranno descritte nei prossimi articoli della rivista, implementano due concetti innovativi: l’isolamento temporale, ovvero la possibilità di specificare quanto tempo un task possa eseguire, bloccando o penalizzando un task che esegue per troppo tempo, ed il concetto di reservation, ovvero la possibilità di garantire un tempo di esecuzione ad un insieme di task. Queste due caratteristiche permettono di gestire i casi di sovraccarico in quanto l’esecuzione di eventuali task che cercano di eseguire per troppo tempo viene confinata senza compromettere l’esecuzione delle altre parti del sistema.

