
Con l'evoluzione delle reti neurali convoluzionali, è diventato semplice costruire programmi in grado di vedere. Le CNN filtrano i complessi input mappandoli in modelli e forme noti. La precisa combinazione di questi pezzi ci dice quali entità sono presenti in un'immagine digitale. In questo articolo andremo a descrivere un esempio di applicazione delle CNN nell'ambito della visione artificiale. La nostra applicazione utilizzerà la camera di un ESP32-CAM per rilevare la presenza o meno di una persona nel suo raggio visivo, e terrà il conto delle persone avvistate visualizzando il numero su un Display LCD.
Introduzione
Fino a poco tempo fa, il senso della vista non era disponibile alle macchine. La maggior parte dei robot testavano il mondo circostante grazie a sensori di prossimità e tattili, ottenendo informazioni sulla forma delle strutture dalle collisioni. La vista permette di ottenere informazioni come forma e utilità di un oggetto senza la necessità di interagire con esso. Purtroppo, un robot non aveva questa fortuna, poiché le informazioni visive erano troppo disordinate, non strutturate e difficili da interpretare. Oggi, grazie ai modelli di visione artificiale basati su CNN, il senso della vista è disponibile anche alle macchine, ed il numero di applicazioni è in costante crescita nei settori più diversi, come nei veicoli autonomi per evitare gli ostacoli, nei robot industriali per rilevare i difetti dei prodotti e nelle immagini medicali per la diagnosi di malattie. I modelli di visione artificiale basati su CNN possono anche essere distribuiti su dispositivi a microcontrollore che presentano vincoli stringenti in termini di risorse, come memoria e consumo di potenza. Questi dispositivi possono essere alimentati con piccole batterie per mesi o addirittura anni, rendendoli perfetti per applicazioni embedded che non necessitano di una connessione ad Internet. Ad esempio, si potrebbero piazzare nella giungla o in una barriera corallina, per tenere il conto degli animali in via di estinzione.
Descrizione dell'applicazione
In questo articolo andremo a descrivere un'applicazione embedded che utilizza un modello ML per classificare immagini catturate da una camera. Il modello è addestrato per riconoscere quando una persona è presente nell'input della camera. Questo significa che la nostra applicazione sarà in grado di rilevare la presenza o l'assenza di una persona e produrre un output in accordo. Ad esempio, il nostro codice potrebbe accendere una luce LED quando una persona viene rilevata o controllare altri oggetti. Nel nostro caso abbiamo deciso di tenere il conto delle persone rilevate e di aggiornare questo numero visualizzandolo su un display LCD.
Per realizzare l'applicazione abbiamo utilizzato i seguenti componenti:
- un modulo ESP32-CAM, nel nostro caso particolare si è trattato della scheda AI-Thinker dotata di videocamera OV2640. Inoltre, la presenza di un convertitore seriale UART-USB può facilitare la vita durante il caricamento del firmware;
- un classico Display LCD 16x2 con retroilluminazione blu e dotato di interfaccia I2C;
- alcuni cavetti jumper;
- una breadboard.
Collegamento dei componenti
In Figura 1 vengono riportati i collegamenti da realizzare tra i vari componenti per l'applicazione in esame.
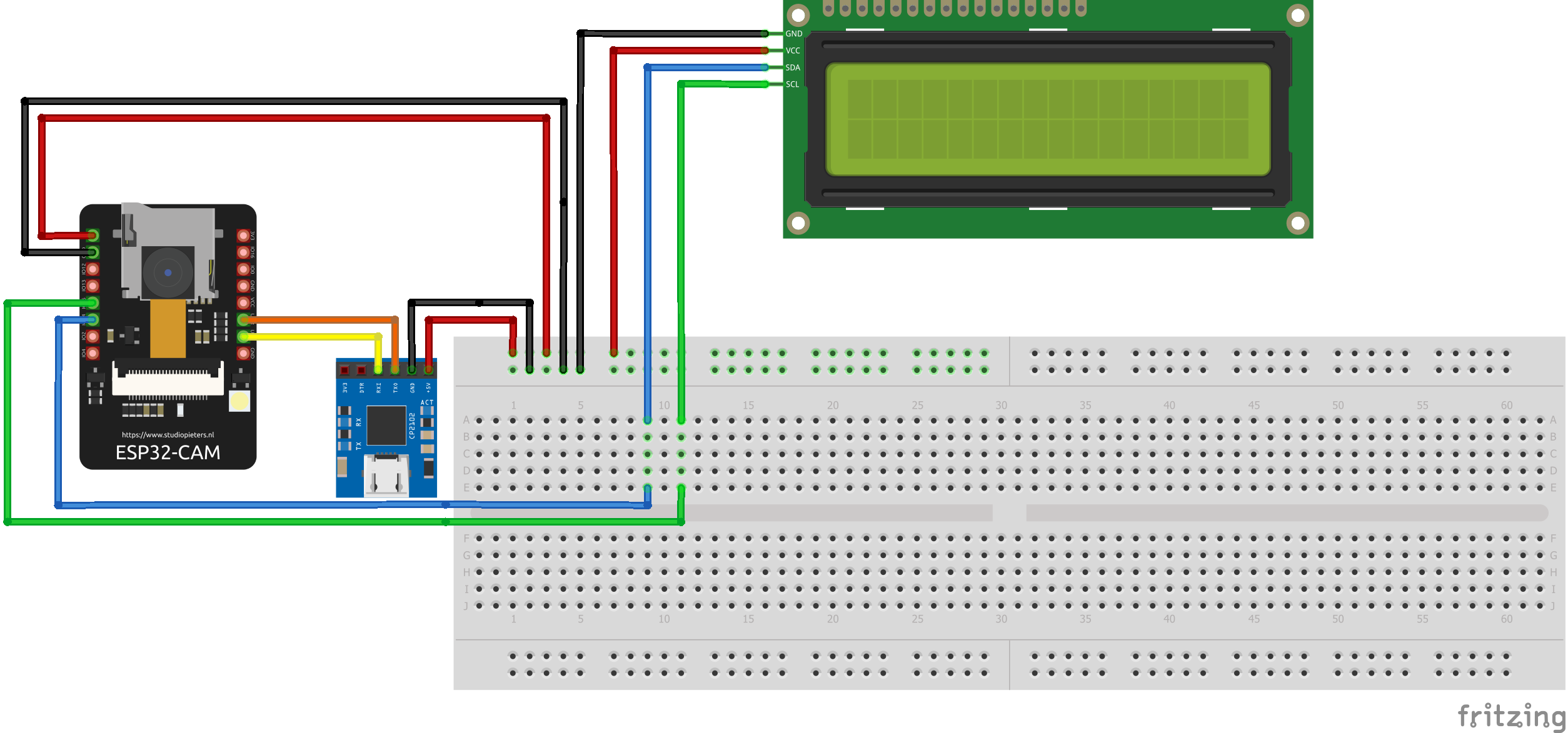
Figura 1: Schema dei collegamenti tra i vari dispositivi coinvolti nell'applicazione
Il modulo ESP32-CAM AI-Thinker è una scheda di sviluppo ESP32 con una fotocamera OV2640 e diversi GPIO per collegare le periferiche. Tuttavia, non ha un programmatore integrato. Si rende necessario un programmatore FTDI per collegarlo al computer e caricare il codice. Molti programmatori FTDI hanno un ponticello che consente di selezionare 3.3V o 5V. Meglio assicurarsi che il ponticello sia nella posizione giusta per selezionare 5V. Nella Tabella 1 vengono descritti nel dettaglio i collegamenti tra i pin dei diversi dispositivi e il colore del cavo associato.
| ESP32-CAM | Programmatore FTDI | Display LCD | Colore cavo |
| GND | GND | GND | nero |
| 5V | VCC (5V) | VCC | rosso |
| U0R | TX | arancione | |
| U0T | RX | giallo | |
| GPIO14 | SDA | blu | |
| GPIO15 | SCL | verde |
Inoltre, occorre tener presente che in fase di caricamento del firmware, il GPIO0 dell'ESP32-CAM deve essere collegato a GND. Questo GPIO è collegato internamente a un resistore di pull-up da 10 kΩ. Quando GPIO0 è collegato a GND, l'ESP32 entra in modalità flash ed è possibile caricare il codice sulla scheda. Per far funzionare l'ESP32 "normalmente", basta disconnettere il GPIO0 da GND e premere il tasto di reset sulla scheda.
Setup dell'IDE Arduino
Prima di cominciare con la descrizione dell'applicazione occorre configurare l'IDE Arduino per operare con il modulo ESP32. In un articolo precedente vengono descritte tutte le operazioni per poter usare l'ESP32-CAM all'interno dell'IDE. Invitiamo quindi il lettore a fare click sul link seguente: https://it.emcelettronica.com/riconoscimento-facciale-per-la-domotica-con-lesp32-cam-parte-1 e seguire i passi descritti nell'articolo al paragrafo "PROGRAMMAZIONE DELLA SCHEDA DI SVILUPPO ESP32-CAM", prima di procedere oltre. A questo punto, all'interno dell'IDE Arduino, occorre scaricare la libreria TensorFlowLite_ESP32. Tale libreria permette l'esecuzione di modelli di Machine Learning sui dispositivi basati sull'ESP32. Con l'installazione della libreria vengono forniti alcuni esempi pronti per l'uso, ed infatti andremo ad utilizzare, modificandolo leggermente, uno di essi per la nostra applicazione. Una volta installata la libreria, andiamo ad aprire l'esempio denominato "person_detection_ESP32-Camera". Quindi salviamolo nella cartella degli sketch, in modo da poterlo modificare. Prima di modificarlo, però, conviene dare uno sguardo al suo funzionamento.
Struttura dell'applicazione
Andiamo a descrivere l'applicazione embedded che usa un modello ML per classificare immagini catturate da una camera. La nostra applicazione di embedded Machine Learning eseguirà le seguenti operazioni in loop:
- ottenere un'immagine dalla camera
- pre-elaborare l'immagine per estrarre le features da dare in pasto al modello ML
- eseguire l'inferenza
- post-elaborare l'uscita del modello per dargli senso
- usare il risultato per far succedere qualcosa
Le immagini fornite dalle camere embedded sono comunemente rappresentate come array di valori di pixel. Il nostro modello ML accetterà in ingresso immagini proprio in tale formato dati. Per questo, l'operazione di pre-elaborazione non presenterà un'elevata complessità.
La Figura 2 illustra la struttura della nostra applicazione. [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2215 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:

Architettura edge AI per lo smart monitoring. Quali i vantaggi rispetto al cloud?

Panoramica della progettazione di schede a microcontrollore
Otto resistori in cerca di un DAC
Revolution Pi: un PC industriale completamente Open Source

Progetti open source di edge AI
