Quanti di noi non hanno mai effettuato una ricerca sul proprio smartphone parlando al browser invece di digitarne l'argomento? Questo appena fatto, non è che un esempio dell'utilizzo quotidiano di una tecnologia oramai largamente diffusa che va sotto il nome di "speech recognition". Per chi si fosse chiesto quali artifici si nascondano dietro tale prodigio della tecnica, questo è l'articolo da leggere per scoprirlo. Nel prosieguo illustreremo al lettore i fondamenti della tecnologia conosciuta in italiano come "riconoscimento vocale", soffermandoci sugli aspetti maggiormente interessanti dal punto di vista scientifico.
Il Problema del riconoscimento vocale
Il riconoscimento vocale automatico, abbreviato con l'acronimo inglese ASR (Automatic Speech Recognition), rappresenta un'evoluzione nell'interfacciamento tra uomo e macchina. Esso permette all'utente di inviare dei messaggi ad un sistema informatico attraverso degli input vocali, che il sistema è in grado di trascrivere. Questo permette di eseguire molte attività quotidiane che richiederebbero l'uso delle mani per mezzo della sola voce, che è poi il sistema più semplice ed immediato con cui l'essere umano comunica. Occorre distinguere il riconoscimento vocale dal riconoscimento del parlatore. Il primo come abbiamo detto permette ad un sistema informatico di trascrivere il contenuto di un messaggio inviato per mezzo della voce, il secondo invece riconosce soltanto se la voce appartiene ad un determinato individuo.
Negli ultimi anni le tecniche di ASR si sono diffuse in maniera capillare, dai servizi di tipo informatico, ai navigatori satelliari per auto, ai call center automatici.
I sistemi per il riconoscimento vocale possono raggrupparsi sostanzialmente in due grandi insiemi:
- Riconoscitori indipendenti dal parlatore, sono quelli pensati per essere adoperati da più utenti e sono basati su un database predefinito e non modificabile.
- Riconoscitori dipendenti dal parlatore, con database definibile dall'utente.
Il riconoscimento vocale appartiene alla classe dei problemi definita come riconoscimento dei modelli (pattern recognition). Nel nostro caso l'input da analizzare è rappresentato da un segnale audio relativo al parlato umano opportunamente campionato e digitalizzato. L'uscita sarà la tascrizione delle parole emesse.
Il segnale audio viene quindi messo a "confronto" con dei modelli (patterns) predefiniti che rappresentano i vari suoni all'interno del linguaggio. Tali suoni possono essere intere parole oppure singoli fonemi. Purtroppo, il problema è molto più complicato di quel che possa sembrare, infatti anche quando una frase viene ripetuta per due volte dalla stessa persona vi possono essere differenze significative dovute a variabili incontrollabili, come ad esempio:
- la cadenza, il tono della voce o la velocità con cui si parla;
- accenti locali, dialetti, o parole straniere;
- rumori di sottofondo o ambientali.
Inoltre i modelli linguistici sono difficili da caratterizzare per 3 motivi fondamentali:
- una lingua con un ricco vocabolario richiede un maggior numero di pattern;
- il parlato è spesso un flusso continuo senza interruzioni, perciò risulta difficile isolare i singoli suoni;
- la presenza in una lingua di inevitabili ambiguità linguistiche.
Nel prossimo paragrafo andremo ad analizzare nello specifico un generico esempio di riconoscitore vocale automatico.
Componenti di un generico ASR
La figura 1 riporta lo schema a blocchi del generico riconoscitore vocale automatico.
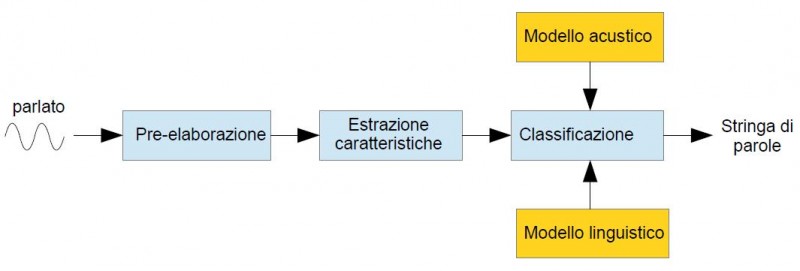
Figura 1: schema a blocchi del riconoscitore vocale automatico
Andiamo ad analizzare nel dettaglio [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2373 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:

Corso di Elettronica per ragazzi – Puntata 8
AVR-IoT: una scheda di sviluppo per collegare le applicazioni IoT a Google Cloud in pochi minuti
Un sistema di diagnostica a bordo basato su Raspberry Pi

ChatGPT come assistente alla scrittura del codice per progetti con Arduino
Un sistema Multisensoriale per la Smart Home – Parte 2

Nel settore automotive i “comandi vocali” aiutano il guidatore ad attivare/disattivare alcuni comandi multimediali a fronte di una maggior sicurezza nella guida. Entro il 2019 più del 60% delle auto saranno dotate di comandi vocali. Le auto del futuro impareranno sempre di più a parlare e ad ascoltare.
Argomento molto attuale, importantissimo nel prossimo futuro.
Durante la conferenza Buid 2016 abbiamo avuto assaggi davvero golosi di quel che possa fare un sistema ASR unito ad una forte intelligenza artificiale, magari supportata da informazioni provenienti dal cloud. Notevole.