
In un precedente articolo avevamo introdotto Weka, un workbench open source per l'apprendimento automatico che consente anche ai neofiti di avvicinarsi fin da subito al mondo del machine learning senza la necessità di conoscenze estese nel campo della programmazione. In quel primo articolo avevamo descritto, utilizzando un esempio pratico, le varie funzioni e opzioni dell'ambiente Explorer, una delle tre GUI messe a disposizione da Weka. In questa seconda parte andremo a descrivere, sempre con la stessa metodologia, la piattaforma Experiment, un utile strumento per impostare, lanciare ed analizzare gli esperimenti di classificazione sui dati.
Introduzione
Weka Experiment Environment consente all'utente di creare, eseguire, modificare e analizzare gli esperimenti in modo più pratico di quanto sia possibile quando si elaborano gli schemi singolarmente. Ad esempio, l'utente può creare un esperimento che esegue diversi algoritmi rispetto a una serie di set di dati e quindi analizzare i risultati per determinare se uno degli algoritmi è (statisticamente) migliore degli altri. L'interfaccia di Experiment è disponibile in due versioni, una semplice (Simple) che fornisce la maggior parte delle funzionalità necessarie per gli esperimenti e una avanzata (Advanced) con accesso completo alle funzionalità. È possibile scegliere tra le due modalità utilizzando il pulsante "Experiment Configuration Mode". Entrambe le configurazioni consentono di impostare gli esperimenti standard, eseguiti localmente su una singola macchina o esperimenti remoti, che vengono distribuiti tra diversi host. La distribuzione degli esperimenti riduce il tempo necessario al loro completamento, ma d'altra parte l'installazione richiede più tempo. Nelle sezioni successive verranno trattati il setup e il lancio di esperimenti standard in configurazione semplice ed infine l'analisi dei risultati.
Setup dell'esperimento
La scheda Setup (figura 1) consente di configurare l'esperimento. Nel seguito vengono descritte le varie funzioni presenti nella scheda.
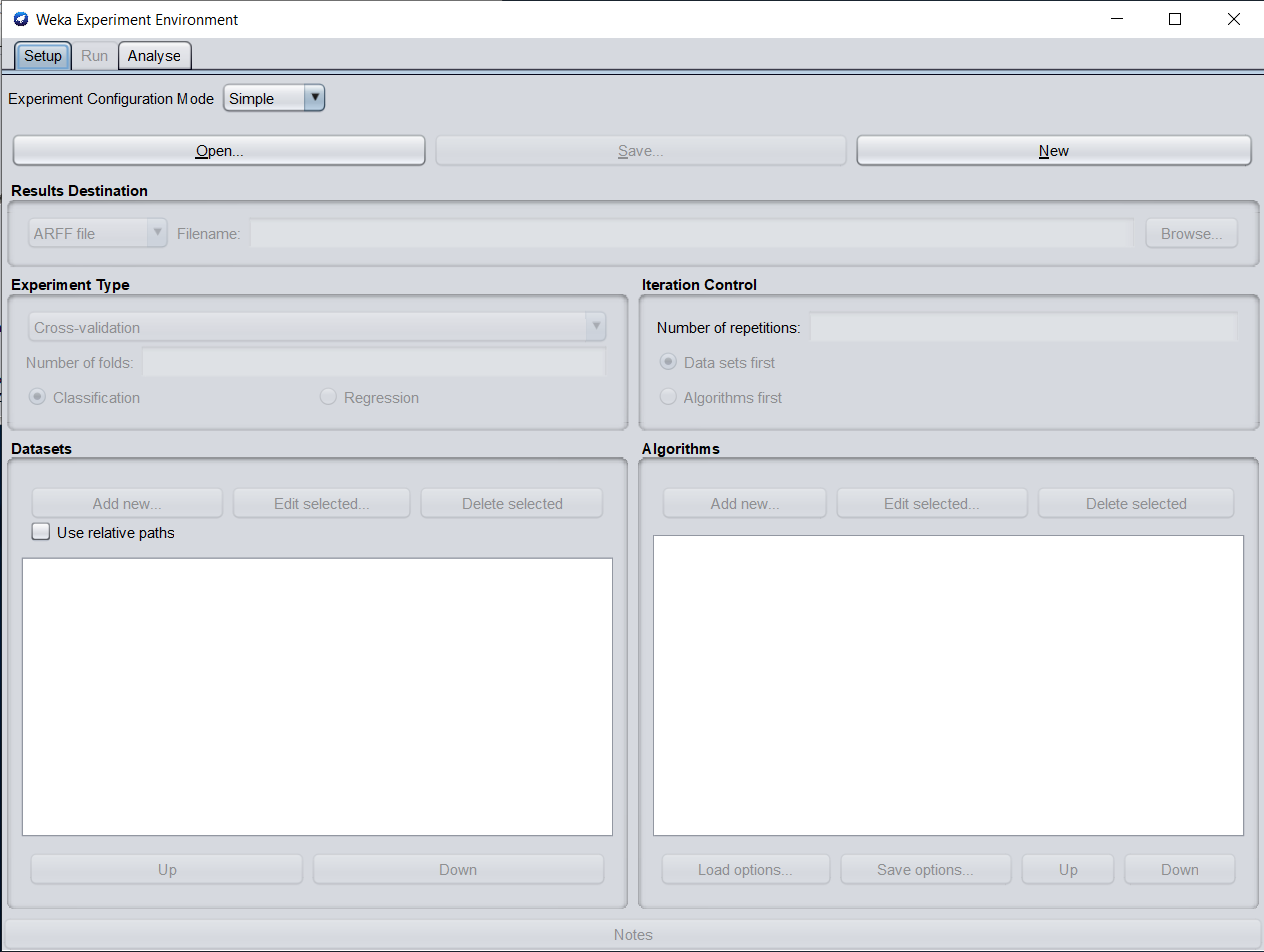
Figura 1. Schermata di configurazione esperimento dell'ambiente Experiment di Weka
Nuovo esperimento - Dopo aver fatto clic su "New", i parametri predefiniti per un esperimento vengono istanziati.
Results Destination - Per impostazione predefinita, un file ARFF è la destinazione per l'output dei risultati. Ma è possibile selezionare tra file ARFF, file CSV o database JDBC. Se il nome del file viene lasciato vuoto, verrà creato un file temporaneo nella directory TEMP del sistema. Se si desidera specificare un file di risultati esplicito, fare clic su "Browse" e digitare un nome, ad es. Experiment1.arff. Facendo clic su "Save", il nome verrà visualizzato nel campo di modifica accanto al file ARFF.
Experiment Type - Si può scegliere tra i seguenti tre diversi tipi:
- Cross-validation (predefinita) esegue una convalida incrociata stratificata con il numero di fold specificato.
- Train/Test Percentage Split (data randomized) divide un set di dati, in base alla percentuale inserita, in un file di addestramento (train) e in un file di test (non è possibile specificare i file di addestramento e di test esplicitamente), dopo che l'ordine dei dati è stato randomizzato e stratificato
- Train/Test Percentage Split (order preserved) poichè è impossibile specificare una coppia di file di train/test espliciti, si può aggirare tale limite dividendo nei suoi file originali, un file nato dalla precedente unione tra train/test (occorre solo trovare la percentuale corretta)
Inoltre, si può scegliere tra "Classification" o "Regression", in base ai set di dati e ai classificatori che si utilizzano.
La Cross-validation è una tecnica di
validazione del modello. In un problema di previsione, ad un modello viene solitamente assegnato un set di dati noti su cui viene eseguito l'addestramento (set di dati di addestramento) e un set di dati sconosciuti (o dati di test) rispetto ai quali viene testato il modello. L'obiettivo della validazione incrociata (cross-validation) è testare la capacità del modello di prevedere nuovi dati che non sono stati utilizzati per stimarlo, al fine di segnalare problemi come overfitting o bias e per dare un'idea di come il modello sarà generalizzato rispetto ad un dataset indipendente (cioè un insieme di dati sconosciuto, ad esempio da un problema reale).
La procedura generale su cui è basata la tecnica prevede in primis la scelta di un valore intero N (solitamente 10) per poi proseguire come descritto:
- Mischiare casualmente il set di dati
- Dividere il set di dati in N gruppi
- Per ogni gruppo unico:
- Portare il gruppo in attesa (per utilizzarlo dopo come test)
- Prendere i restanti N-1 gruppi come set di dati di allenamento
- Costruire un modello sul set di allenamento e valutarlo sul set di test
- Conservare il punteggio di valutazione e scartare il modello
- Riassumere l'abilità del modello usando il campione dei punteggi di valutazione del modello ottenuti.
Datasets - Si possono aggiungere file di set di dati con un percorso assoluto o con uno relativo, quest'ultimo rende spesso più facile eseguire esperimenti su macchine diverse. Cliccando su "Add" si aprirà la directory data e si potrà scegliere il file desiderato. Dopo aver cliccato su "OK", il file verrà visualizzato nell'elenco dei set di dati. Se si seleziona una directory e si preme "Open", tutti i file ARFF verranno aggiunti in modo ricorsivo. I file possono essere eliminati dall'elenco selezionandoli e quindi facendo clic su "Delete selected". Per impostazione predefinita, si presuppone che l'attributo di classe sia l'ultimo attributo del dataset.
Iteration Control - Per ottenere risultati statisticamente significativi, il predefinito "number of repetitions" è 10. Nel caso di più set di dati e algoritmi, può essere utile passare da "Data sets first" ad "Algorithms first". In tal caso si ottengono prima i risultati per tutti i set di dati per il primo algoritmo, poi tutti quelli per il secondo e cosi via.
Algorithms - Nuovi algoritmi possono essere aggiunti tramite il pulsante "Add new". Di default viene presentato ZeroR, o quello selezionato per ultimo. Con il tasto "Choose" si può scegliere un altro classificatore. Il pulsante "Filter" consente di evidenziare i classificatori che possono gestire certi attributi e tipi di classi. Con il pulsante "Remove", tutte le funzionalità selezionate verranno cancellate e l'evidenziazione rimossa. Dopo aver impostato i parametri del classificatore, cliccando su "OK" è possibile aggiungerlo all'elenco degli algoritmi. Con "Load options" e "Save options" è possibile caricare e salvare il setup di un classificatore selezionato da e verso XML. Ciò è particolarmente utile per classificatori altamente configurati, in cui il setup manuale richiederebbe un po' di tempo o che vengono utilizzati spesso. È inoltre possibile incollare le impostazioni del classificatore facendo clic con il pulsante destro del mouse (o Alt-Maiusc-clic-sinistro) e selezionando il punto appropriato dal menu di pop up, si potrà cosi aggiungere un nuovo classificatore o sostituire quello selezionato con una nuova configurazione. Questo è utile per il trasferimento di una configurazione di classificatore da Weka Explorer ad Experiment senza dover impostare da zero il classificatore. Per il riutilizzo futuro, è possibile salvare la configurazione corrente dell'esperimento in un file cliccando su "Save" nella parte superiore della finestra. Gli esperimenti salvati precedentemente possono essere caricati nuovamente tramite il pulsante "Open".
Lanciare l'esperimento
Per eseguire l'esperimento corrente, fare clic sulla scheda "Run" nella parte superiore della finestra di Experiment Environment. Quindi premere il tasto "Start" per lanciare l'esperimento. Se l'esperimento è stato definito correttamente, i 3 messaggi mostrati in figura 2 verranno visualizzati nel pannello di Log.
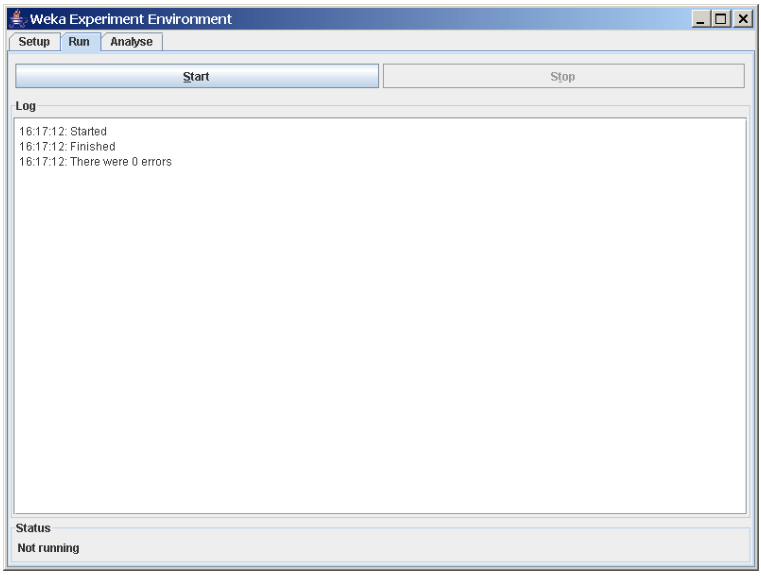
Figura 2. Messaggi di convalida dell'esperimento lanciato nel Log di Experiment
Analisi dei risultati
Weka include un analizzatore [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2240 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
Progetto di un dispositivo di controllo di un accesso di sicurezza con RFID e Arduino – Parte 1
Un sistema di diagnostica a bordo basato su Raspberry Pi
Servomotori e Arduino: come usarli con la scheda a micro-controllore

Monitoraggio predittivo con AI su dispositivi edge

Automazione e robotica per la pulizia degli oceani

WEKA è davvero un ottimo strumento, soprattutto considerando che permette di sfruttare la potenza di Java per essere esteso, data la sua natura open source.
L’ho usato nel 2007 per la tesi della laurea specialistica, nell’ambito del Data Mining.
Ovviamente all’epoca lo strumento conteneva meno funzionalità della versione attuale ma era comunque molto usato per estrapolare informazioni da dataset anche molto estesi.
Nel mio caso dovevo rilevare la presenza di determinati pattern genetici, relativi a un paio di malattie associate a questi dataset, attraverso la ricerca e la valutazione dell’efficacia di diverse metriche. Un argomento, quello del Data Mining, all’epoca agli albori, ma che oggi ha trovato applicazione in molteplici situazioni.