
Oggi esistono differenti algoritmi di programmazione, ogni casa costruttrice elabora un proprio modello. Le procedure di test di questi dispositivi sono spesso (non sempre) basati sul comportamento di questi algoritmi. Le case costruttrici, poi, si basano molto sulla loro efficienza anche per affinare i propri prodotti e le loro strategie: gli algoritmi sono spesso selezionati per ottenere la più alta resa delle EPROM. L’algoritmo di programmazione Rapid™ riduce il tempo richiesto per programmare le EPROM e garantisce, nel contempo, la reliability del sistema.
Introduzione
Il pregio di Rapid™ è di diminuire il tempo di programmazione già stabilita da un altro algoritmo, chiamato FAST quick-pulse, da circa 1ms a 100ms e di eliminare, nel contempo, gli impulsi di sovraprogrammazione. La tabella 1 riporta il confronto diretto tra Fast e Rapid™.

Tabella 1: confronto diretto tra Fast e RapidTM
In Rapid™ è implementato un particolare processo di verifica per controllare se la cella è stata correttamente programmata e che le celle stesse siano programmate con il relativo carico richiesto. Nell’algoritmo Quick-Pulse la verifica è fatta per ogni cella di memoria subito dopo la scrittura. Esiste però una leggera anomalia in quick-pulse: le locazioni di memoria che sono state precedentemente programmate possono essere parzialmente cancellate dal processo di programmazione delle successive locazioni per effetto dell’elevato voltaggio applicato sulle celle di memoria. Questo tipo di anomalia potrebbe anche non essere rilevata dal processo di verifica, perché questa è fatta con una tensione inferiore rispetto alla scrittura. L’algoritmo di programmazione Rapid™, invece, risolve questo problema. Infatti, in primo luogo ogni cella è programmata senza controllare se l’operazione sia andata a buon fine. Solo al termine del processo di scrittura, verifica il dato scritto in ogni cella. Se non si riscontrano errori viene attivato un altro processo di verifica a 5V. In questo modo Rapid™ è certamente un algoritmo migliore in grado di rilevare le marginalità riscontrate dagli altri.
L’ALGORITMO
In questa parte vediamo le differenze di programmazione tra quick-pulse e Rapid™. In figura 1 è mostrato, in maniera schematica, l’algoritmo quick-pulse.
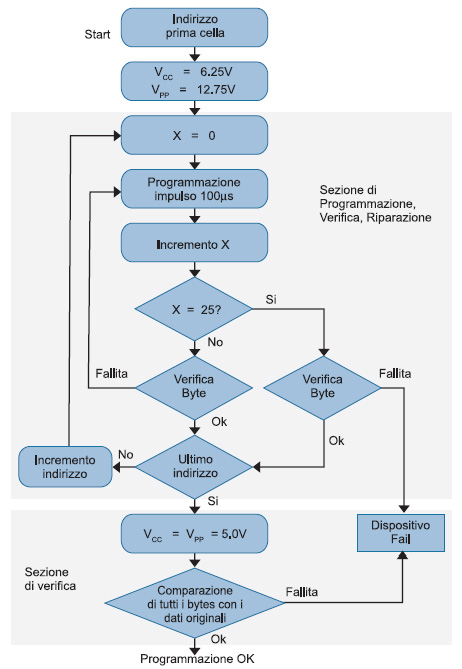
Figura 1: l’algoritmo Quick-Pulse
Dalla figura 1 notiamo che l’algoritmo è diviso in due macro funzioni: la parte principale è costituita dalla sezione di programmazione e verifica, la parte secondaria, ma non per questo meno importante, è la sezione di verifica finale. Il comportamento dell’algoritmo può essere così riassunto:
- La prima sezione inizia all’indirizzo zero. A questo indirizzo il byte 0 viene programmato e si verifica se la cella in questione contiene il dato corretto: questo processo di verifica viene effettuato a 6,25V.
- Se l’operazione si conclude con successo allora viene fatta una nuova operazione di scrittura all’indirizzo successivo.
- Se l’operazione di verifica intermedia non si conclude con successo, allora l’operazione viene ripetuta per 25 volte prima di dichiarare il fail del componente.
- Il processo di verifica finale si svolge con una tensione inferiore (5V) e consiste nel controllare se le locazioni associate a tutti gli indirizzi contengono i dati corretti leggendo tutte le locazioni. Come è possibile vedere dal diagramma di flusso, questa operazione viene svolta in una passata finale a 5V, altri programmatori, invece, dividono la funzione di verify finale in due passate: una a 4.75V e un’altra a 5.25.
Questa è in sostanza il ciclo che deve svolgere un quick-pulse generico. In figura 2, invece, è mostrato in che modo queste operazioni vengono svolte da Rapid™.
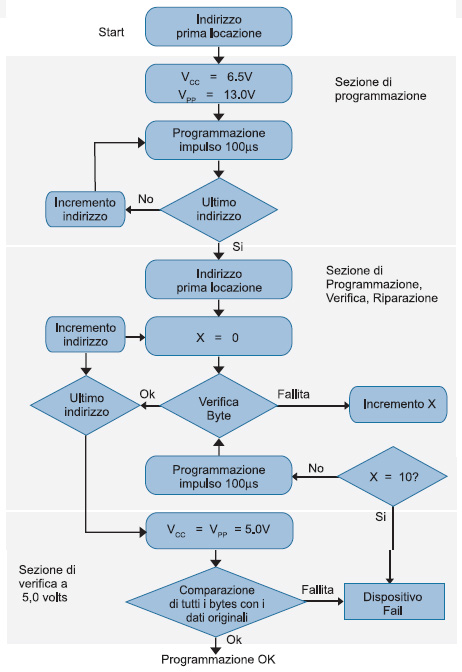
Figura 2: l’algoritmo RAPID™
Questo algoritmo si compone di tre sezioni. La prima è la sezione di programmazione: il programmatore si preoccupa di programmare ogni locazione di memoria della EPROM senza l’operazione di verifica. Successivamente, la sezione due, svolge il ruolo di verifica e di riparazione. In questo caso il programmatore inizia dalla prima locazione in memoria e verifica ogni locazione se contiene il dato corretto (a 6,5V). In questo modo, se una delle qualsiasi celle di memoria non passasse il processo di verifica, allora la cella verrebbe riprogrammata, in questo caso fino a 10 tentativi di riprogrammazione. Se l’operazione di riparazione non andasse a buon fine allora il componente è dichiarato in fail dal programmatore. L’ultima sezione utilizza una tensione di 5.0V e svolge un’operazione finale di verifica. La sezione di verifica finale è comune alla maggior parte dei programmatori e di solito viene fatto in due passate con due tensioni differenti: una a 4.75 e l’altra 5.25. Questi algoritmi vengono anche chiamati algoritmi a due passate perché l’array della memoria EPROM è acceduto due volte durante la programmazione.
Un particolare riguardo va dato al processo di erase. Per cancellare un dispositivo di questo tipo è necessario esporlo ad una radiazione di raggi ultravioletti di adeguata intensità e durata. Oltre a questo meccanismo esiste un altro modo per cancellare questi componenti, e chi ha provato ad utilizzare le memorie di tipo EEPROM lo sa benissimo. Ma perché per questi componenti esistono diversi algoritmi di programmazione? La tecnologia EPROM non è già sufficientemente stabile tale da non richiedere differenze di programmazione? La tecnologia in uso per queste memorie è in continua evoluzione. Ogni algoritmo recepisce le evoluzioni tecniche per sfruttarne ogni nuova caratteristica. Quando tentiamo di programmare di nuovo delle celle di memoria di una EPROM, si ha un aumento del campo elettrico in ogni cella già programmata: l’aumento di questo campo può alterare il contenuto stesso della cella fino a provocare marginalità che l’algoritmo di programmazione rileva e rende evidente, magari come anomalia, nella sua procedura. Questo comunque, non vuol dire che la cella di memoria provoca un problema che viene chiamato reliability, ma semmai questo è un problema che riguarda solo la programmabilità del componente. Inoltre, non viene pregiudicata la durata della ritenzione dei dati, perchè l’anomalia riguarda unicamente la perdita d’informazioni contenuta nella cella. Uno dei meriti più rilevanti dei moderni algoritmi di programmazione è quello di trovare queste marginalità e, in seguito, di tentare di predisporre delle azioni di recovery per permettere di ripristinare il funzionamento normale.
CASO PRATICO
Vediamo ora un caso pratico adoperando un AT21C010, un dispositivo Atmel di 1 Mb di tecnologia EPROM con i due algoritmi menzionati. Possiamo notare che tipi di impatto provoca in una cella di memoria con la marginalità introdotta dalla programmazione. La geometria interna del componente è di 1 Mb strutturati in 127 colonne con 1024 righe con 8 outputs: si deduce che una singola riga su una singola uscita ha 128 celle di memoria. Si suppone che la seconda cella di memoria su questa riga, (bit 1) abbia una asperità, cioè la presenza di un problema elettrico che indica un erasure mode: la presenza di un valore basso di tensione che potrebbe indicare la mancata programmazione della cella stessa. Nel nostro caso, però, questo è un falso problema perchè potrebbe essere risolto riprogrammando la cella stessa. I differenti algoritmi, utilizzando differenti marginalità, potrebbero manifestare diversi comportamenti. Se utilizziamo quick-pulse, l’algoritmo concluderebbe il proprio lavoro in maniera negativa. Utilizzando, invece, Rapid™ il lavoro potrebbe concludersi in maniera positiva, in risposta sia alla differente marginalità e sia al differente algoritmo.
Quick-pulse
Ecco il comportamento del quick-pulse.
- Il bit 0, dopo essere stato programmato, è sottoposto al processo di verifica (come si rende evidente in figura 1); il processo si conclude con esito positivo con la sua corretta marginalità.
- Dopo il bit 0 ora si passa la bit successivo: bit 1. Questo dopo essere stato programmato viene sottoposto al processo di verifica con esito positivo.
- Dopo la scrittura e verifica del bit 2 la tensione applicata al bit 1 si riduce di pochi milliVolts.
- Programmando e verificando il bit 3, il bit 1 ha ancora problemi di tensione che si abbassa ulteriormente.
- Il processo continua fino alla fine dell’array di memoria da programmare (fino al bit 127): chiaramente la tensione del bit 1 scenderà di conseguenza ad ogni passo.
Si deduce quindi che l’algoritmo risulta abbastanza inefficiente in quanto non ha modo di capire che cosa è successo al bit 1. In questo modo, al termine dell’algoritmo, con il processo di verifica finale con Vcc 5,25V, l’algoritmo può rilevare che il bit 1 non è correttamente programmato terminando la procedura con un errore.
Rapid™
Che cosa succederebbe con Rapid™? Con questo algoritmo la programmazione del bit e il suo processo di verifica sono localizzati in sezioni diverse della procedura: non sono fatte nello stesso ciclo (vedi figura 2). Ecco la procedura:
- Partiamo dal bit 0, la tensione impostata è di 6,5V;
- Il secondo bit, il bit 1, viene programmato;
- Dal bit 2 incominciamo a notare alcuni problemi. Infatti, dopo averlo programmato il bit 1 riduce leggermente la propria tensione;
- Il prossimo bit è il 3. Dopo averlo programmato, di nuovo il bit 1 riduce ancora la sua tensione;
- Continuando di questo passo arriviamo all’ultimo bit, il 127. A questo supponiamo che il valore del bit 1 sia al valore 6,492V.
A questo punto, secondo l’algoritmo in uso, dobbiamo verificare, dal bit 0, che ogni cella contiene il valore 6,5V. Quando si arriva al bit 1 l’algoritmo dovrebbe fallire, ma questo non succede. Riscriviamo il bit 1 con 6,5V e controlliamo tutti gli altri bits, dal secondo all’ultimo. Dal secondo bit ricaviamo che il valore della cella è ancora impostato a 6.5V: da ciò si vede che la verifica del bit 2 non inficia il bit 1, la de-programmazione del bit 1 si manifesta solo quando scriviamo i bit successivi al primo, ma non nel processo di verifica. Ed è questo l’elemento importante di Rapid™. Quindi, al termine della programmazione, basterebbe riscrivere il bit 1 con il suo valore corretto per risolvere il problema.
CONCLUSIONE
L’algoritmo Rapid™ garantisce la programmabilità del dispositivo, cosa che non viene fatto da quick-pulse. Certamente se la casisitica degli errori sulle celle di memoria fosse più complessa, l’algoritmo Rapid™ potrebbe anche non fornire una sufficiente garanzia di programmabilità.





C’è un vasto mercato che nel corso degli anni ha portato a soluzioni sempre più sofisticate ma nello stesso tempo facilmente gestibili. C’è qualcuno nella community che ha utilizzato questo algoritmo?