
Dopo RISC e CISC è ora la volta dell’architettura VLIW. Quali sono le sue caratteristiche? Quali sono le differenze rispetto alle architetture precedenti? Quali sono le sue implicazioni?
L’architettura VLIW (Very Long Instruction Word) è una macchina di nuova concezione e si pone come una valida alternativa alle soluzioni basate su RISC e CISC. Principalmente, un’architettura VLIW ha le parole di istruzioni molto lunghe e consente di attivare più operazioni contemporaneamente, senza richiedere un riordino delle istruzione durante l’esecuzione.
Questo consente di lavorare su unità di controllo più semplici rispetto a una architettura di tipo superscalare, in cui il riordino delle istruzioni è affidata all’hardware. Inoltre, consente di realizzare unità di calcolo a basso consumo, in quanto l’esecuzione parallela permette di utilizzare frequenze di clock più basse, diminuendo così i consumi. L’evoluzione tecnologica verso questa nuova generazione di dispositivi ha recepito la continua richiesta di maggiore potenza da parte degli applicativi. Le innovazioni più importanti sono state le pipeline e lo sfruttamento del parallelismo a livello istruzione. I primi a sfruttare il parallelismo a livello istruzione sono stati i processori superscalari e più di recente sono nati i processori VLIW. Si può notare come la tendenza attuale, per entrambe le architetture, sia quella di utilizzare processori basati su RISC con pipelining. La differenza principale tra superscalari e VLIW è nel modo in cui il parallelismo a livello istruzione viene riconosciuto e utilizzato.
Nel caso dei processori superscalari ci troviamo di fronte ad uno scheduling dinamico, ovvero il parallelismo viene riconosciuto dinamicamente dall’hardware durante l’esecuzione stessa del codice. Invece nei processori VLIW lo scheduling delle operazione è di tipo statico e viene eseguito direttamente dal compilatore. Il continuo progresso tecnologico consente un elevato livello di integrazione dei transistor all’interno di un singolo chip. L’idea di sfruttare questo alto grado di integrazione ha portato, gradualmente, a concepire una nuova soluzione architetturale. In un approccio VLIW il codice è costituito da una sequenza di Very Long Instruction Word (chiamati anche bundle). Ogni bundle è costituito da un certo numero di slot, ognuno dei quali può contenere una operazione di un certo tipo. Ad ogni ciclo di clock viene avviata una Very Long Instruction, ossia un insieme di istruzioni che possono essere avviate simultaneamente. Una architettura di questo tipo, oltre ad avere implicazioni hardware, ha impatti sul compilatore.
CONSIDERAZIONI HARDWARE
Vediamo una struttura di una generica long instruction imponendo un massimo numero di operazioni all’interno del bundle. L’architettura VLIW utilizza istruzioni lunghe, ma di lunghezza fissa. L’esempio si basa su una sequenza di bundle con 5 slot. La seguente porzione di codice identifica il codice di riferimento per un processore RISC (32 bits):
lw r1, vett(r4) lw r2, vett(r5) add r3, r4, r5 divf f2, f4, f5 sub r6,r8,r9 sw vett(r7), r9 beqz r9, loop
In VLIW si compone di 160 bit e la tabella 1 ne mostra la sua articolazione. L’esecuzione di un’istruzione su una macchina VLIW è riportata in figura 1. Le differenze tra un microprocessore superscalare e un processore VLIW possono essere così riassunte:
- La selezione delle istruzioni da caricare in un ciclo di clock è fatta, per le macchine VLIW, durante la compilazione. Per le macchine superscalari invece avviene durante l’esecuzione del programma. La logica di decodifica per le VLIW risulta perciò più semplice rispetto alle superscalari.
- Quando il grado di ILP è inferiore a quello disponibile nell’architettura VLIW, la densità di codice è maggiore per una macchina superscalare. Questo perché il formato di istruzioni della VLIW è fisso e comprende dei bit anche per istruzioni inutili, che non verranno utilizzate, mentre nell’altro caso si hanno dei bit in memoria codice solo per istruzioni utilizzabili.
- Un processore superscalare è compatibile con un’ampia famiglia di processori più semplici, che non sfruttano estremamente il parallelismo del codice. Processori VLIW differenti invece, cioè con un differente grado di parallelismo, richiedono un differente insieme di istruzioni.

Tabella 1. Articolazione per VLIW in 5 bundle
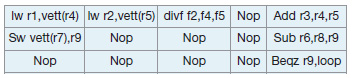
Figura 1. Esecuzione di istruzioni su una macchina VLIW
Con uno scheduling statico si ha il vantaggio di poter lavorare su porzioni di codice più ampie rispetto a quelle degli scheduler dinamici. Si aumenta, infatti, la probabilità di individuare del parallellismo all’interno del codice. Al contrario, il compilatore, rispetto ad uno scheduler dinamico, può fare solo predizioni (per esempio sull’indirizzo di un registro), diminuendo così l’efficacia dello scheduling potenzialmente ottenibile. A seconda dell’implementazione le parole sono composte da un numero massimo di operazioni che varia, di solito, da 4 a 8 (ovvero varia da 128 bit a 256 bit). Il codice che sarà posto in esecuzione dipende da questa granularità. Infatti, se non è possibile individuare un numero sufficiente di operazioni da eseguire in parallelo, è necessario terminare una parola inserendo esplicitamente delle NOP. In alcune architetture si è ovviato a questo inconveniente utilizzando delle tecniche per la compressione del codice. Nelle macchine VLIW, mancano delle unità dedicate per gestire il fuori ordine delle istruzioni e il renaming dei registri. Il motivo di questo è che risultano essere delle funzionalità svolte dal compilatore durante la fase di scheduling. Il ruolo del compilatore in queste architetture assume un ruolo importante: è necessario disporre di un efficiente compilatore. Un peso enorme in tutto questo è il ruolo dello scheduler del compilatore che determina il livello di sfruttamento delle risorse. Per ottenere questi livelli di efficienza sono state introdotte nuove tecniche quali il loop unrolling, il software pipelining e il trace scheduling. Il concetto di cluster rientra pure in quest’ottica. Infatti, per avere una maggiore scalabilità dell’architettura, si partiziona il sistema in cluster. È pensabile che per limitare la complessità del banco dei registri, al crescere del numero di unità funzionali, può essere utile raggruppare le unità in cluster e di associare un banco di registri ad ogni cluster. In questo modo le unità funzionali condividono solo il banco di registri che appartiene al proprio cluster; le altre unità (per esempio il branch unit) rimangono condivise tra i vari cluster. Per permettere ai vari cluster di comunicare tra di loro è necessario introdurre un bus aggiuntivo e delle istruzioni apposite, per effettuare la copia di dati tra i vari banchi di registri. Questa è una possibile soluzione, ma chiaramente con un approccio simile si limita la scalabilità dell’architettura.
RUOLO DEL COMPILATORE
La parte di ordinamento (scheduling) delle istruzioni è affidata esclusivamente al compilatore; questo consente l’uso di una control unit più semplice con annesso risparmio di area sull’hardware. Per sviluppare un compilatore per una architettura VLIW sono necessari diverse fasi con modifiche nei vari momenti del cross-compiling: dal compilatore all’assembler. Altri, invece, non propongono compilatori per sfruttare la nuova capacità, bensì soluzioni alternative: non si modifica il compilatore, ma si fornisce una libreria. Il progettista software del sistema è colui che deve identificare quel gruppo di istruzioni, bundle, che intende utilizzare. Nella fattispecie vengono fornite due interfacce per marcare l’inizio e la fine della porzione di codice. In ogni caso se si sceglie di modificare il compilatore occorre tenere presente che il compilatore deve conoscere l’hardware sottostante: il numero delle unità funzionali di ogni tipo (per esempio interi o reali) e le latenze delle unità funzionali. Il ruolo del compilatore è importante, infatti è questo stabilisce le istruzioni che possono stare nello stesso bundle. La sequenza di questo gruppo di istruzioni, il plan of execution, determina quali istruzioni e in quale slot temporale deve essere eseguito dall’hardware. La differenza con le architetture di tipo superscalare è abbastanza evidente: in un microprocessore superscalare il ILP (Istruction Level Parallelism) è ottenuto dinamicamente a run-time, mentre in VLIW il ILP è ottenuto staticamente già in fase di compilazione. Un approccio di questo tipo sposta la complessità dall’hardware al compilatore: lo schedulatore hardware non ha più un ruolo preponderante.
Un approccio di questo tipo porta degli indubbi vantaggi: modificare uno schedulatore software di un compilatore è relativamente più semplice che modificare lo schedulatore hardware, la complessità dell’hardware non cambia anche se aumentiamo la iussue-width. Per dovere di cronaca è necessario dire che esistono anche degli svantaggi, infatti possono esserci degli slot vuoti e in questo caso vengono riempiti con dei nop comportando un aumento del codice. Gli eseguibili, inoltre, possono non essere compatibili perché il codice binario dipende fortemente dalla tipologia delle unità funzionali e dalle loro latenze. Al fine di ottimizzare la schedulazione delle operazioni e minimizzare gli stalli, il compilatore deve essere a conoscenza delle latenze delle unità funzionali. I registri sono divisi in due classi:
- Physical Registers. È l’insieme dei registri presenti nell’hardware;
- Architectural Registers. Sono quei registri che sono visibili dall’utilizzatore dell’instruction set e dal compilatore.
Il numero dei registri effettivamente presenti è chiaramente maggiori dell’Architectural Register. Infatti, anche se ci sono 64 registri effettivamente presenti, il compilatore non può utilizzare una istruzione LW r35,vett(r4). Per permettere la schedulazione delle istruzioni, utilizzando tutti i registri presenti, si utilizza il meccanismo del cosiddetto register renaming. Il compilatore, nella determinazione della sequenza di long instruction che verranno eseguite, deve conoscere il numero di registri realmente disponibili. La parte hardware deve eseguire il plan of execution (POE), non schedula e non opera register renaming. Il numero di istruzioni che possono essere schedulate in parallelo, ossia il livello di ILP raggiugibile dipende da:
- Numero di unità funzionali disponibili;
- Parallelismo intrinseco dell’applicazione;
- Tecniche di compilazione.
Uno dei fattori che limita maggiormente il livello di ILP ottenibile è rappresentato dalla presenza di conditional branches. I branch frammentano le sequenza di istruzione in più basic block, i quali potrebbero essere troppo brevi per consentire una schedulazione. Un basic block è una sequenza di codice lineare avente un punto di ingresso e un punto di uscita. Non posso schedulare in parallelo istruzioni appartenenti a basic blocks diversi, poichè la loro esecuzione dipende dalle diramazioni prese durante l’esecuzione. Per superare la limitazione introdotta dai conditional branch, i compilatori VLIW possono usare delle istruzioni predicate per implementare la tecnica detta if-conversion. I predicate registers sono registri di dimensione di un bit che contengono valori booleani. Una predicated instruction, oltre ai soliti operandi, dispone di un campo aggiuntivo che specifica un predicate register, ad esempio: addi r2,r2,4,p7
La semantica delle istruzioni predicate può essere espressa in questo modo:
“se il predicate register è uguale a ‘1’, allora esegui normalmente altrimenti trattalo come NOP”.
Per questo motivo è uso comune indicare nella notazione di una istruzione predicata l’operando aggiuntivo preceduto da ‘if’: ADDI r2,r2,4 if p5.
Il valore dei registri predicate viene settato tramite speciali istruzioni dette compare to predicate. Queste verificano una certa condizione e settano un’opportuna coppia di predicate register con valori complementari. Ci sono svariate istruzioni, a seconda di qual è la condizione da verificare. Vediamo come si può eliminare il branch con if-conversion del listato 1.
branch con if-conversion
If (a<b) c = a;
else
c = b;
if (d<e) f = d;
else
f = e;
| Listato 1 |
Supponendo un bundle di 4 slot, la porzione di codice, come mostrato nella tabella 2, può essere schedulata in due sole long instruction.

Tabella 2. Articolazione per VLIW in 4 bundle per if-conversion
Tramite la if-conversion un branch condizionale viene dunque rimpiazzato da una istruzione che setta una coppia di predicate register con valori complementari. Le istruzioni che appartenevano ad ognuna delle due diramazioni possono tranquillamente essere schedulate in parallelo, poichè la loro effettiva esecuzione è vincolata al valore booleano contenuto in appositi predicate registers. Un qualsiasi compilatore esamina il codice sorgente scritto in un linguaggio più o meno evoluto, per esempio in C, e lo traduce, successivamente, in un pseudoassembler. Un compilatore concepito per una macchina VLIW deve allocare la memoria in maniera tale da consentire di parallelizzare il lavoro tra le unità operative. Il codice sorgente, deve dunque essere scritto in maniera efficiente così da evitare la produzione del codice binario troppo inefficiente e quindi poco ottimizzato. Inoltre, anche l’assembler deve essere realizzato per dividere le operazioni tra più unità. Può essere utile disporre di un programma che sia in grado di interpretare il codice assembler prodotto (pseudocodice) e fornire un file di report, utile per evidenziare parti di codice non efficiente e le eventuali informazioni utili per attivare la macchina VLIW. Questa utility diventa necessaria tanto più si ha a disposizione un assembler granulare che non consente di attivare direttamente le unità operative. In base agli esiti di questo report è possibile trarre le indicazioni su quando attivare le macroistruzioni.
CONCLUSIONE
Si conclude a questo punto questa breve carrellata sull’architettura VLIW. Senza dubbio questa proposta è una vera innovazione rispetto alla tecnologia precedente e, per sfruttarla al meglio, occorre disporre di cross-factory efficienti, anche se qualcuno non preferisce modificare il compilatore, ma proporre soluzioni basate su librerie esterne.

