
L’architettura von Neumann prevede un unico bus per memoria dati e memoria programma per cui non è possibile leggere contemporaneamente un dato e una istruzione. Essa ha rappresentato la prima architettura per elaboratore. Si tratta di un modello di computer basato su di una singola struttura di memorizzazione sia per i dati che per le istruzioni. Ecco come l’architettura Harvard risolve questo problema.
DALL’ARCHITETTURA VON NEUMANN ALL’ARCHITETTURA HARVARD
Lo schema di principio è riportato in figura 1. Con questo termine si rappresenta un computer che implementa una macchina di Turing ed il modello referenziale di architettura sequenziale, in contrasto con quella parallela.
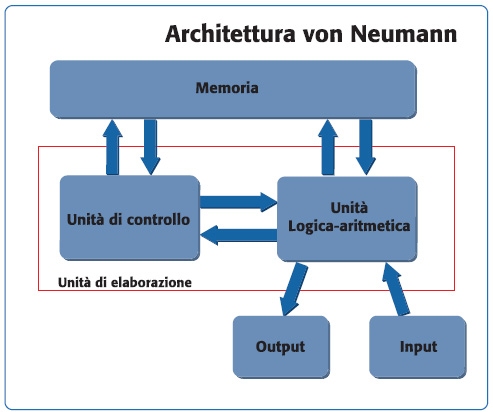
Figura 1. Architettura von Neumann
Nel modello di von Neumann è implicita la separazione della memoria dalla unità di elaborazione, definendo quello che viene chiamato stored-program computer. Inizialmente, infatti questi due blocchi erano unici ed avevano una memoria programma fissa. Ad esempio, un calcolatore desktop (in principio) si presentava come una macchina in grado di eseguire operazioni matematiche, ma sarebbe stato impossibile usare un word processor oppure eseguire dei video games. Tale macchina rappresentò una grande innovazione; la possibilità di trattare le istruzioni come fossero dati permise lo sviluppo di assembler e compilatori. Era così possibile “scrivere programmi che scrivono programmi”. Chiaramente, la possibilità di modificare programmi è anche uno svantaggio: se si sbaglia indirizzo di memoria si rischia di sovrascrivere il firmware e ciò può comportare anche il danneggiamento irreversibile della macchina. Un altro problema tipico di queste macchine è rappresentato dal buffer overflow. Per risolvere il problema si può pensare di implementare alcune forme di protezione della memoria. Il termine deriva dall’articolo scritto dal matematico John von Neumann nel giugno del 1945, che trattava per primo una macchina stored-program gereral purpouse (denominata EDVAC). La separazione della CPU dalla memoria ha però portato a quello che è oggi conosciuto come collo di bottiglia di von Neumann. Il throughput (cioè la velocità di trasferimento dei dati) tra unità di elaborazione e memoria è molto minore rispetto alla quantità di dati trasferiti. Inoltre, il throughput è molto minore rispetto alla frequenza operativa della CPU. Queste considerazioni determinano una seria limitazione nella velocità effettiva di esecuzione delle istruzioni. In presenza di operazioni di accesso alla memoria la CPU deve continuamente attendere che tali dati arrivino. Attualmente le frequenze operative e la dimensione della memoria aumenta ad un tasso esponenziale, mentre il throughput avanza molto lentamente, rendendo sempre più marcato questo collo di bottiglia. Per superare i limiti analizzati con il modello von Neumann è stata introdotta l’architettura Harvard, che presuppone la separazione della memoria programma da quella dati. Il termine deriva dalla macchina Harvard Mark I, di cui è mostrato un dettaglio in figura 2.

Figura 2. Dettaglio della macchina Harvard Mark I
Poiché nell’architettura von Neumann il blocco di memoria ed il relativo percorso sono unici, non è possibile leggere allo stesso tempo una istruzione ed un dato. In un computer con architettura Harvard questo è possibile. Uno schema principio è illustrato in figura 3.
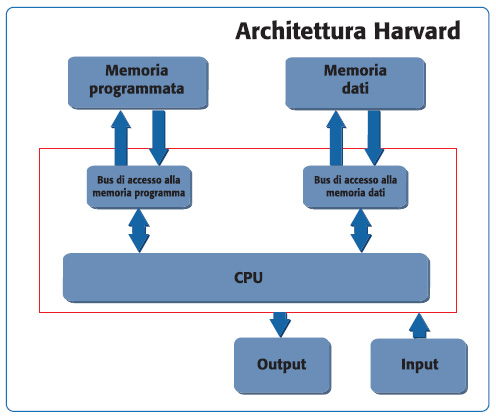
Figura 3. Architettura Harvard
Questo rappresentò una rivoluzione, perché permise di salire con le prestazioni e superare i limiti imposti dal collo di bottiglia dell’architettura von Neumann. Infatti, la CPU è in grado di effettuare il fetch dell’istruzione successiva contemporaneamente al completamento di quella corrente. Di qui allo sviluppo di sistemi basati su pipeline il passo è breve. Ovviamente, rispetto ad una macchina von Neumann, quella Harvard risulta più complessa dal punto di vista implementativo e circuitale. Questo si traduce in un costo superiore. In realtà le cose, come spesso succede, non sono così nette: ossia non si deve pensare che l’architettura von Neumann sia completamente scomparsa a favore di quella Harvard. Le moderne CPU fanno spesso uso di memorie più veloci (cache) ma con dimensioni ridotte, allo scopo di bufferizzare i dati dalla memoria principale (off-chip). L’architettura implementata in tali situazioni è una soluzione mista: per l’accesso della CPU alla cache è usata l’architettura Harvard, mentre si usa la von Neumann per gli eventuali accessi alla memoria off-chip. Un campo applicativo in cui è frequente l’uso della architettura Harvard è nei DSP (Digital Signal Processor) utilizzati per prodotti di elaborazione audio e video. Alcuni esempi di processori che adottano tale filosofia implementativa sono il Blackfin prodotto da Analog Devices ed il TMS320 prodotto da Texas Instruments, di cui si parlerà nel corso dell’articolo. Inoltre, la maggior parte dei microcontrollori general purpose impiega tale strategia. Tra gli altri si ricordano i microcontrollori PIC di Microchip e AVR di Atmel. Tali dispositivi sono caratterizzati da una piccola quantità di memoria programma e dati; essi traggono vantaggio dall’architettura Harvard e dal loro ridotto set di istruzioni (RISC) per assicurare la massima velocità di esecuzione dell’istruzione (idealmente questa dovrebbe essere pari ad un ciclo macchina). La separazione della memoria permette anche di avere bus dati e bus istruzioni di differente ampiezza.
PIPELINE ED ARCHITETTURA HARVARD
Si vedrà ora una tipica applicazione, la pipeline, in cui l’uso dell’architettura Harvard comporta un aumento del throughput della macchina rispetto all’uso di una memoria unica. Si supponga inizialmente di disporre di una macchina organizzata secondo l’architettura von Neumann (quindi un’unica memoria, con un unico bus di accesso, come riportato in figura 1). Un possibile modo per stimare le prestazioni di un sistema a processore è sicuramente il tempo di esecuzione della singola istruzione. Per ridurre tale tempo la prima soluzione che può essere attuata è l’aumento della frequenza di clock. Questo metodo, come è facile intuire, presenta dei limiti. Oltre certe frequenze anche piste di pochi centimetri diventano delle antenne e si creano problemi di interferenze elettromagnetiche che non è semplice prevedere e risolvere. In questo senso numerosi passi avanti sono stati fatti per migliorare le prestazioni dei package dei processori (i package BGA sono stati progettati proprio per venire incontro a tali problemi). Una possibile alternativa per aumentare il throughput sarebbe quella di far eseguire le istruzioni in parallelo, anziché in modo sequenziale, aumentando così il numero di istruzioni eseguite per unità di tempo; questa tecnica è conosciuta come pipeline. Per comprendere meglio come funziona, si farà riferimento alle tipiche fasi in cui si suddivide una istruzione eseguita dalla CPU (tabella 1).

Tabella 1. Fasi in cui si suddivide una istruzione
La fase di fetch si occupa di effettuare il prelievo dell’istruzione, tramite l’unità di accesso al bus. La decodifica effettua l’interpretazione dell’istruzione. La lettura accede alla memoria per leggere un dato. L’esecuzione esegue operazioni logiche-aritmetiche ed infine si ha l’eventuale operazione di scrittura in memoria. Mentre in una macchina sequenziale tutte queste microistruzioni vengono eseguite in sequenza, in un processore con pipeline si può pensare di sovrapporle, come mostrato in figura 4.
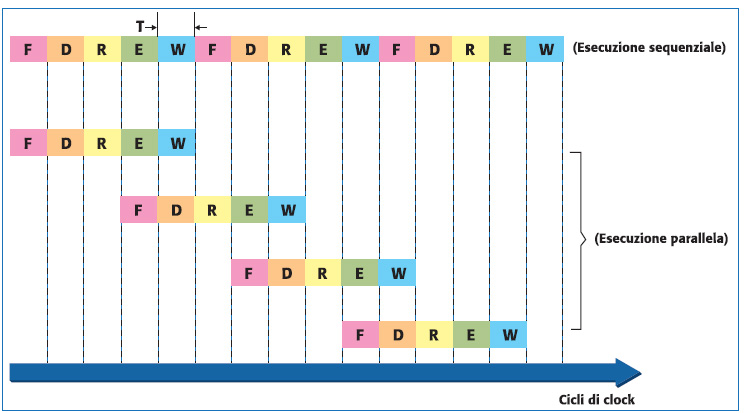
Figura 4. Confronto tra esecuzione sequenziale e parallela
Come si nota dalla schematizzazione di figura 4 il numero di istruzioni eseguite in modalità parallela è superiore a quello sequenziale. Se si definisce il throughput come l’inverso del tempo per eseguire una istruzione, allora si può dire che in assenza di pipeline si avrà 1/5T (dove T è il tempo per eseguire una microistruzione), mentre sovrapponendo due stadi si avrà 1/3T (ossia una istruzione eseguite ogni 3 cicli di clock). Si noti che la sovrapposizione delle diverse fasi è stata possibile poiché non ci sono conflitti tra le unità del processore. A questo punto si può pensare di aumentare ancora il throughput, per portarlo ad esempio a 1/2T. Questo comporterebbe la sovrapposizione evidenziata in figura 5 con tratteggio rosso.
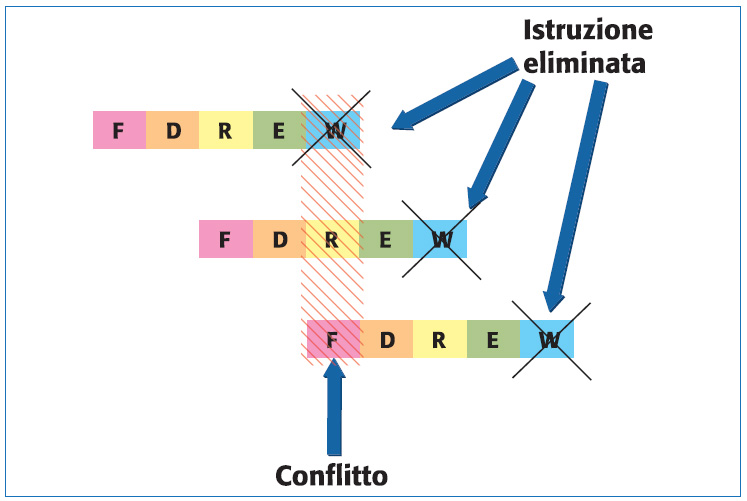
Figura 5. Pipeline con throughput 1/2T
Infatti, la fase di fetch richiede il prelievo dell’istruzione dalla memoria ed al contempo è necessario leggere un dato. Poiché stiamo ipotizzando una macchina con architettura von Neumann questo aumento di throughput è impossibile. Una possibile soluzione è utilizzare lo schema a memorie separate riportato in figura 3 (architettura Harvard). Questa soluzione si basa sul fatto che mentre la fase di fetch preleva un’istruzione, quella di read legge un operando. Si sarà però osservato che in questo modo non tutti i conflitti sono stati risolti: la fase di lettura si sovrappone a quella di scrittura. In queste condizioni si elimina la fase di write di un’istruzione, aumentando il numero di registri del processore nei quali possono essere immagazzinati operandi e risultati; inoltre, si realizzano delle istruzioni apposite per salvare in memoria il contenuto di tali registri. A questo punto la velocità del processore è stata portata a 1/2T, tranne quando vengono eseguite istruzioni per salvare il contenuto dei registri in memoria. In questi casi le prestazioni risultano inevitabilmente degradate.
PIC ED ARCHITETTURA HARVARD
A differenza di altri concorrenti, i microprocessori PIC di Microchip sono un esempio di architettura Harvard. Essi non condividono la stessa memoria per codice e dati. Ciò gli consente di accedere contemporaneamente a entrambi. La Figura 6 mostra lo schema a blocchi di un PIC della famiglia 18F: è facile individuare il bus a 8bit che fa riferimento alla memoria dati e quello a 16bit relativo all’area istruzioni.
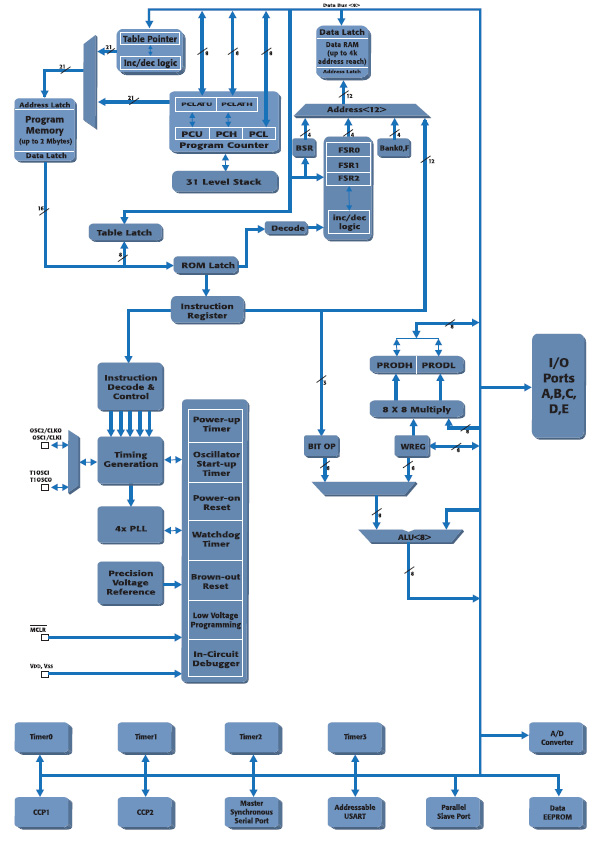
Figura 6. Diagramma a blocchi di un PIC18FXX2
In generale Microchip offre tre differenti categorie in base alle prestazioni richieste:
- architettura base (PIC10F/PIC12/PIC16), con un bus programma pari a 12bit;
- architettura mid-range (PIC12/PIC16), con un bus programma pari a 14bit;
- architettura per alte prestazioni (PIC18), con un bus programma pari a 16bit.
Tutti i PICmicro sono caratterizzati da una pipeline a due stadi (fase di fetch e di esecuzione) che consente di eseguire una istruzione ad ogni ciclo macchina (eccetto istruzioni di salto). Il bus dati è sempre costituito da 8 bit.
DSP ED ARCHITETTURA HARVARD
Un componente elettronico che fa largo uso dell’architettura Harvard è sicuramente il DSP (Digital Signal Processor). Si cercherà ora di comprendere come sia possibile ottimizzarne le prestazioni. Nell’ambito del signal processing, i DSP offrono il supporto ottimizzato a ben precisi algoritmi di riferimento; essi possono essere visti come componenti dedicati alla classe di algoritmi numerici per l’elaborazione di segnali digitali. Il DSP unisce velocità e potenza di calcolo per l’elaborazione dei dati in tempo reale. Esso risulta pertanto perfetto in tutte quelle applicazioni in cui non sono tollerati ritardi nella risposta del sistema. Rispetto ad un microprocessore che può essere considerato general purpose, il DSP è invece un componente application dependent.
La maggior parte degli algoritmi per l’elaborazione dei segnali richiede un’operazione di moltiplicazione e addizione, indicata in generare con il termine di MAC (Multiply and ACcumalate):
x=(y .z)+k
Tale operazione viene eseguita (mediante un’apposita architettura che sarà chiarita a breve) in un solo ciclo di clock. Anche se può sembrare poco utile, l’operazione di MAC è sfruttata in algoritmi per il calcolo di filtri digitali e per le trasformate di Fourier. Viene indicato con il termine datapath, la parte hardware di un DSP contenete l’unità di moltiplicazione ed accumulazione, con cui viene realizzato tale operazione fondamentale. Alcune applicazioni per cui i DSP sono stati pensati sono:
- Audio application
- Video application
- Wireless comunications
- Motor control
- Digital camera
- Voice over Internet
- Speech processing
- Telefoni cellulari
- TV digitale
- Strumentazione
Tra i principali produttori al mondo di DSP, ci sono Texas Instruments, Analog Devices, Freescale (ora NXP) ed ST Microelectronics. Come si sarà facilmente intuito da quanto specificato in precedenza, un DSP non potrà disporre di un’architettura von Neumann. In tal modo, infatti, si ridurrebbe eccessivamente il throughput e non si potrebbe realizzare un MAC in un solo ciclo di clock. Il ricorso all’architettura Harvard è quindi un imperativo. Attualmente la maggior parte dei DSP impiega un’architettura dual bus che permette di caricare contemporaneamente una istruzione ed un dato. Un ulteriore miglioramento delle prestazioni è stato possibile grazie alla cosiddetta architettura SHARC (Super Harvard ARChitecture). Si tratta, essenzialmente, di una modifica che prevede l’aggiunta di una cache on-board alla CPU per la memorizzazione delle istruzioni. Alcuni produttori (come ad esempio Analog Devices) si sono spinti anche oltre, inserendo un controller I/O connesso alla data memory, come riportato in figura 7.

Figura 7. Architettura SHARC dei DSP Analog Devices
L’uso dell’architettura Harvard base o modificata, introduce un problema nella progettazione basata su DSP: l’uso delle due memorie determina un incremento del numero di pin del processore. Si deve infatti indirizzare uno spazio di memoria maggiore. Una possibile soluzione al problema è quella di prevedere un memoria on-chip, mentre il collegamento con la memoria esterna è demandato ad un unico bus. È importante sottolineare che le architetture presentate fin qui non rappresentano il limite massimo al throughput. Per i DSP esistono soluzioni ancora più performanti come quelle rappresentate dall’architettura VLIW (Very Long Instruction Word). Un DSP VLIW ha un’architettura interna di tipo parallelo caratterizzata dalla presenza di più unità funzionali indipendenti. Questo elevato grado di prestazioni può essere raggiunto mediante un parallelismo a livello di istruzioni o di dati. L’Istruction Level Parallelism (ILP) permette di processare più operazioni in un singolo ciclo di clock. Con il Data Level Parallelism (DLP) un singola unità di esecuzione è separata in porzioni di dati più piccole (figura 8). Si cercherà ora di comprendere meglio i due concetti mediante altrettanti esempi. La velocità di elaborazione delle operazioni può essere incrementata se le operazioni di tipo RISC come load, store, moltiplicazioni e addizioni, vengono eseguite in parallelo su unità funzionali differenti (ILP). In questo caso ogni istruzione contiene un operation code per ciascuna unità funzionale (le Processing Unit - PU - di figura 8).

Figura 8. Schema di un’architettura VLIW, con ILP
Tale codice viene ricevuto simultaneamente da ogni unità. L’esempio riportato in tabella 2 riguarda l’esecuzione di una istruzione in cui si effettua il prodotto tra vettori (tipico per l’implementazione di filtri FIR).

Tabella 2. Confronto tra architettura Harvard e ILP VLIW
In un processore RISC l’istruzione fetch effettua semplicemente il prelievo di un dato dalla memoria. Disponendo di PU differenziate diventa possibile effettuare il prelievo contemporaneo di x1 e y1. In questa maniera utilizzando solo 5 cicli di clock (anziché gli 11 dell’altra architettura) si ottiene un aumento del throughput superiore al 50%. La velocità d’esecuzione dei programmi può essere incrementata anche partizionando le operazioni. Una singola unità aritmetica viene scomposta per poi eseguire la stessa operazione su parti più piccole di dato. L’esempio tipico per comprendere meglio questo concetto è la cosiddetta addizione partizionata (o partitioned Add). Se due array, per esempio di 64bit, devono essere sommati, allora ogni unità da 64bit viene scomposta in otto piccole unità da 8bit. In questo modo si possono eseguire 8 operazioni in parallelo. La figura 9 schematizza quanto sopra descritto. Il partitioned Add risulta molto utile in operazioni come la somma tra vettori.

Figura 9. Schema di un’architettura VLIW, con DLP
Nel caso in cui si voglia sommare i vettori X e Y, l’operazione da eseguire è:
X + Y = (x1 + y1 , x2 + y2 , … , xN + yN)
Dove xi e yi sono le componenti del vettore. Si supponga per semplicità che N = 128. La tabella 3 riporta il codice in linguaggio C che deve essere utilizzato per eseguire l’operazione, con entrambe le architetture.

Tabella 3. Confronto tra architettura Harvard e DLP VLIW
In questo caso le prestazioni sono state incrementate di un fattore 8 grazie all’uso del parallelismo dati. Inoltre, considerando che il numero di iterazioni del loop decresce anch’esso di un fattore 8, si ha un aumento complessivo del throughput pari a 64. In generale l’architettura DLP VLIW prevede un set di istruzioni appropriato:
- Partitioned (operazioni aritmetico/logiche)
- Istruzioni di somma:
Inner product
SAM (Sum Absolute Module)
SAD (Sum Absolute Difference)
- Partitioned_select:
Minimo
Massimo
Selezione condizionale
- Formatting (shuffle)
- Multimedia specific
Ad esempio, nei moduli per effettuare la Motion Compensation si sfrutta la seguente operazione:
![]()
Essa può essere effettuata molto velocemente mediante l’istruzione SAD. Criteri di valutazione delle prestazioni di un DSP Quando si vogliono confrontare le prestazioni di due o più DSP è utile impiegare alcuni parametri universalmente accettati:
- MIPS (Milioni di Istruzioni Per Secondo): conta il numero di istruzioni eseguite da un determinato programma di test. Il risultato viene successiva- mente diviso per il tempo di esecuzione. Tale parametro ha solo un valore indicativo, in quanto spesso non viene indicato il tipo di istruzioni eseguite. Inoltre, in generale viene fornito soltanto il valore di picco e non quello medio che può risultare molto inferiore.
- MFLOPS (Milioni di FLOating point Per Secondo): rappresenta il numero di operazioni floating point eseguite in un secondo. Si tratta di un’informazione interessante e fornisce una stima della potenza di elaborazione del sistema.
- MMACS (Milioni di MACS): si tratta del numero di operazioni MAC eseguite in un secondo.
- Application Cube: si tratta di un parametro visivo che fornisce un modo di valutare le performance di un DSP. Si costruisce un cubo come quello riportato in figura 10.
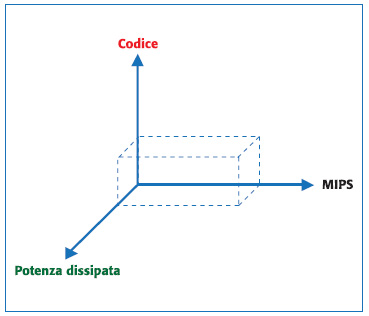
Figura 10. Application Cube
Su ciascuna dimensione del cubo può essere inserita una caratteristica da ottimizzare (es. MIPS, dimensione del codice e potenza dissipata). Benchmarking: si utilizzata un apposito programma che deve “girare” sul DSP al fine di valutarne le prestazioni. Tale codice deve ovviamente tener conto, quanto più possibile, dell’architettura del dispositivo. In generale con un benchmark vengono confrontare le caratteristiche di differenti famiglie di DSP piuttosto che modelli specifici di DSP.
Esempio di un DSP commerciale
Come ricordato sopra, uno dei principali produttori di chip è Texas Instruments. I DSP della famiglia TMS320 sono prodotti sia nella versione fixed point (C62) che in quella floating point (C67). Sono dotati di 8 istruzioni da 32bit per ciclo e raggiungono i 4800 MIPS di picco. Le frequenze di clock variano tra 150 e 250MHz. L’architettura che sfruttano è un particolare tipo di VLIW chiamato VelociTi Advanced, composta di otto Processing Unit:
- 4 ALU per operazioni sia in virgola fissa che mobile;
- 2 ALU per operazioni in virgola fissa;
- 2 moltiplicatori in virgola fissa e mobile.
Come si può notare dalla figura 11 il DSP è dotato di un 1Mbit di SRAM on-board, 512Kbit di cache interna per il codice, 512Kbit di memoria a doppio accesso per i dati.

Figura 11. Schema a blocchi del TMS320
