
Un chatbot o chatterbot è un programma informatico che simula le conversazioni fatte da esseri umani attraverso chat vocali o di testo. È più comunemente usato nelle applicazioni di messaggistica. Come tutti sappiamo, Alexa e altri assistenti vocali sono alcuni dei chatbot basati sull'Intelligenza Artificiale e sull'elaborazione del linguaggio naturale (NLP). In questo articolo vedremo come creare un semplice chatbot usando il linguaggio di programmazione Python. Questo assistente virtuale digitale sarà in grado di accettare come input dei comandi vocali o scritti, e di dialogare con l'utente attraverso una voce sintetizzata. Inoltre, risponderà ai comandi eseguendo alcune applicazioni di sistema presenti sul dispositivo.
Introduzione
L'ascesa dell'automazione, insieme a una maggiore potenza di calcolo, nuovi algoritmi statistici e una migliore accessibilità ai dati, hanno portato alla nascita del mercato degli assistenti digitali personali, popolarmente rappresentati da Siri di Apple, Cortana di Microsoft, Google Assistant di Google e Amazon Alexa. Sebbene ogni assistente possa specializzarsi in compiti leggermente diversi, tutti cercano di semplificare la vita dell'utente attraverso interazioni verbali. Questo articolo guiderà il lettore nella creazione di un chatbot con il linguaggio di programmazione Python in grado di svolgere il ruolo di assistente virtuale digitale. Tale assistente sarà in grado di comprendere alcuni comandi vocali e di rispondere alle richieste. Esso può essere personalizzato per eseguire tutte le attività di cui si ha più bisogno.
Funzionamento
Lo script in linguaggio di programmazione Python, che andremo a descrivere in questo articolo, una volta avviato eseguirà le seguenti operazioni:
- La voce sintetizzata ci darà il benvenuto e ci chiederà se vogliamo utilizzare i comandi vocali o i comandi scritti
- Potremo fare la scelta inserendo nel terminale la lettera v (vocali) o s (scritti) e premendo Invio
- Fatta la scelta apparirà una lista dei comandi possibili e la voce sintetica ci chiederà di immettere un comando. Ce ne sono solo tre per questo esempio, ma la lista può essere ampliata a piacimento. I comandi sono: disegno per aprire il programma Paint, blocco note per aprire Notepad, uscita per chiudere l'applicazione
- A seconda della scelta fatta nel punto 2 si dovrà quindi immettere un comando scritto o vocale
- Nel caso si fosse scelta l'immissione di comandi scritti, basterà digitare il comando, premere invio e verrà eseguita la scelta fatta. Nel caso, invece, di immissione di comandi vocali prima di pronunciare il comando occorrerà aspettare che sul terminale compaia la scritta Sto registrando. A quel punto si potrà pronunciare il comando e attendere la risposta della voce sintetica
- Se il riconoscimento vocale ha avuto successo si aprirà l'applicazione scelta, altrimenti la voce sintetica ci dirà di non aver capito e di riprovare
- Alla chiusura dell'applicazione selezionata, il programma Python continuerà a chiederci di immettere un comando a meno che non si proceda alla chiusura dello stesso
L'interazione mediante comandi vocali è sicuramente più complicata da creare rispetto a quella con comandi scritti. La Figura 1 descrive graficamente una generica interazione con l'assistente virtuale mediante comandi vocali. Su ogni blocco è presente il relativo modulo Python che fornisce gli strumenti per realizzare quella funzione. L'anello debole della catena è rappresentato dal blocco di riconoscimento vocale il quale introduce un ineludibile ritardo dovuto alla trasmissione e ricezione dei dati sulla rete. Inoltre, il riconoscimento non sempre è un successo, ed occorre stare attenti a scandire bene i comandi e in maniera non troppo rapida.
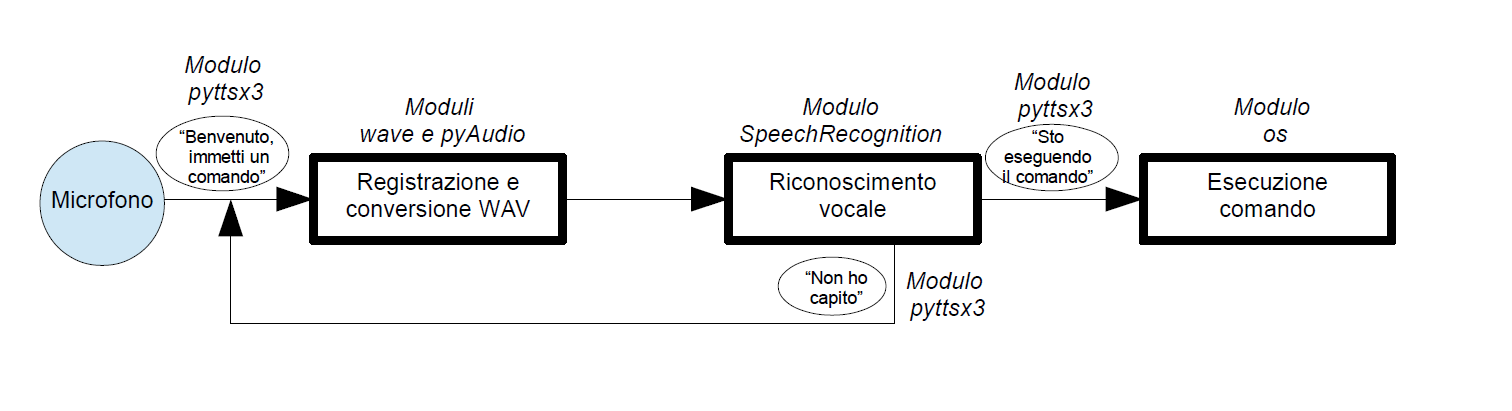
Figura 1: Esempio di interazione mediante comandi vocali. Il comando vocale, intercettato dal microfono del computer, viene registrato grazie al modulo pyAudio e convertito in formato WAV grazie al modulo wave. Il file audio viene quindi passato al riconoscitore vocale grazie al modulo SpeechRecognition. Se il riconoscimento ha successo allora viene eseguito il comando, altrimenti l'assistente chiederà di immettere nuovamente il comando
Software necessario
Inutile dire che per poter utilizzare sul proprio computer questo script, occorre aver installato una distribuzione Python sul proprio dispositivo. Inoltre, occorre scaricare i moduli che verranno poi richiesti all'interno della routine. I moduli da scaricare sono:
- pyttsx3 - per convertire un testo in un discorso attraverso una voce sintetizzata
- pyAudio - per registrare il comando vocale
- wave - per convertire il comando vocale registrato in formato WAV
- SpeechRecognition - per riconoscere il comando vocale
Per chi non avesse mai usato Python prima d'ora, può cliccare sul link ad un precedente articolo dove sono presenti le istruzioni su come installare una distribuzione Python e i moduli necessari. Descriviamo quindi i moduli più importanti presenti nello script.
pyttsx3
pyttsx3 è una libreria di conversione da testo a voce in Python. A differenza delle librerie alternative, funziona offline ed è compatibile con Python 2 e 3. Il modulo pyttsx3 supporta due voci, la prima è femminile e la seconda è maschile. Permette di controllare la velocità e il volume della voce sintetizzata. Include tre motori TTS (Text To Speech):
- sapi5 - SAPI5 su Windows
- nsss - NSSpeechSynthesizer su Mac OS X
- espeak - eSpeak su tutte le altre piattaforme
pyAudio
pyAudio è la libreria che permette di registrare i comandi vocali. Formalmente pyAudio è un ponte tra Python e PortAudio, una libreria C++ multipiattaforma che si interfaccia con i driver audio dei dispositivi. PortAudio è una libreria open source per la riproduzione e la registrazione dei file audio su computer. È una libreria multipiattaforma, quindi consente di scrivere semplici programmi audio in C o C++ che verranno compilati ed eseguiti su molte piattaforme o diversi sistemi operativi per computer, inclusi Windows, Mac OS X e Linux. PortAudio fa parte del progetto PortMedia, che mira a fornire un insieme di librerie indipendenti dalla piattaforma per il software musicale. Mentre tutte le altre librerie sono facilmente installabili su proprio computer grazie a pip, pyAudio potrebbe dare alcuni problemi. Se dovessero presentarsi difficoltà di installazione, le seguenti istruzioni dovrebbero risolvere il problema:
- nel Prompt dei comandi digitare il comando py per visualizzare la versione di Python installata (la mia è la 3.7.2)
- all'interno della stessa schermata, è possibile trovare se si ha la versione da 64 o 32 bit, come mostrato in Figura 2
- trovare quindi l'appropriato file .whl dal seguente link e scaricarlo (il mio ad esempio è PyAudio‑0.2.11‑cp37‑cp37m‑win_amd64.whl)
- andare nella cartella dove è stato scaricato il file, ad esempio C:\Users\Andrea\Download
- installare il file .whl mediante pip, digitando ad esempio pip install PyAudio-0.2.11-cp37-cp37m-win_amd64.whl

Figura 2: Digitando py nel Prompt dei comandi è possibile vedere la versione della distribuzione Python installata sul proprio dispositivo ed altre informazioni
SpeechRecognition
Il riconoscimento vocale è la capacità software di un computer di identificare parole e frasi nella lingua parlata e convertirle in testo leggibile dall'uomo. Il riconoscimento del parlato richiede un input audio e SpeechRecognition rende il recupero di questo input davvero semplice. La libreria SpeechRecognition funge da wrapper per diverse API di riconoscimento vocale molto popolari ed è quindi estremamente flessibile. Tra queste vi sono:
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2331 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
Scopriamo la Spresense Extension Board della SONY
TinkerCAD Circuit: come creare circuiti con Arduino e simularli direttamente da browser
Una panoramica sulla modellazione matematica dei veicoli elettrici

Il sensore rilevatore di persone di Useful Sensors

VoltSchemer: gli attacchi ai caricabatterie wireless

Buongiorno. questo chatbot funzionerebbe offline?
Sì.
Occorre però selezionare l’unica API di riconoscimento vocale, tra le sette disponibli, in grado di operare offline: CMU Sphinx.
Basta sostituire la seguente riga:
– text = r.recognize_google(audio_data, language = “it-IT”)
con
– text = r.recognize_sphinx(audio_data, language = “it-IT”)