
Perché dovremmo preoccuparci di questo tema in un sistema embedded? La problematica della sicurezza e, di riflesso, quella dei puntatori a funzioni rientra sicuramente nella fattispecie dell’affidabilità del codice e per un sistema embedded questa necessità diventa prioritaria per via delle implicazioni che ne conseguono.
Il tema di questo articolo è davvero molto vasto. L’affidabilità di un sistema software passa attraverso l’uso di strumenti di verifica e di definizione dei requisiti; ogni campo di applicazione ha poi precise normative di riferimento. Così, in campo ferroviario si adotta un insieme di rigide norme che hanno l’obiettivo, o come riferimento, la certificazione dei prodotti e della sicurezza dei sistemi elettronici per il segnalamento ferroviario. A questo proposito, la tabella 1 mostra le differenti normative di riferimento nelle applicazioni ferroviarie, tranviarie, filotranviarie e metropolitane.
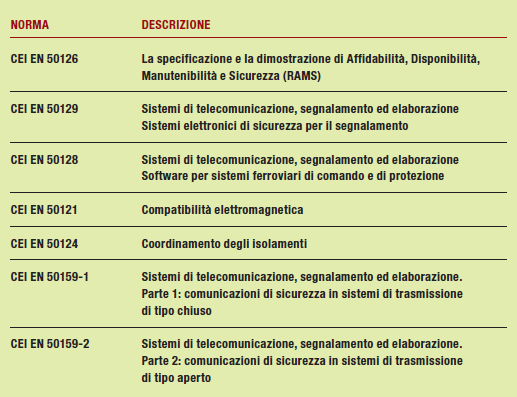
Tabella 1 - applicazioni ferroviarie, tranviarie, filotranviarie e metropolitane
Un sistema embedded non può autoescludersi da questo scottante argomento. Nella società di oggi, le applicazioni di questo tipo coinvolgono ormai tutti gli aspetti quotidiani. Per questa ragione, anche un sistema embedded è sottoposto alle normative, siano queste linee guida o precisi standard, che tendono a garantire l’affidabilità del prodotto. Il settore automotive, per esempio, che per sua natura ha stringenti requisiti di sicurezza, ha risposto con l’introduzione delle linee guida basate su MISRA, ma non solo, anche il settore aeronautico e spaziale (e di recente anche quello militare) propone le linee guida RTCA/DO-178B. Sicuramente il settore che oggi, per via delle recenti cronache, sente maggiormente questa esigenza di affidabilità è quello dei sistemi elettronici per il segnalamento ferroviario. In sostanza, quando si parla di sicurezza, si vuole garantire la necessità che il sistema possa, in qualche modo, essere ricondotto in uno stato sicuro in seguito a un malfunzionamento e che il progetto stesso possa essere accurato per minimizzare il tasso di verifica di guasti pericolosi. Nessuno è immune a questo tema. Quando parliamo di software, in realtà l’argomento è inteso in senso ampio e coinvolge tutti gli aspetti della progettazione: dal codice scritto in un linguaggio come il C a quello VHDL che, magari, si trova in una FPGA. Il linguaggio VHDL è nato nei primi anni ’80 con lo scopo di fornire una descrizione non ambigua di un sistema digitale.
Oggi, il VHDL, accanto ad altri linguaggi HDL, si è affermato nella sintesi dei sistemi digitali. In alcune realizzazioni, per soddisfare l’esigenza della validazione della descrizione hardware del modello, si è preso come riferimento la norma CEI EN 50129, mentre per la parte di linguaggio di programmazione il riferimento è stato la norma CEI EN 50128. Accanto alle normative si è sentito anche l’esigenza di definire un coding style per il VHDL con lo scopo di minimizzare la presenza di errori sistematici nel design. L’obiettivo di ogni lavoro che tuteli la sicurezza poggia su due pilastri: la probabilità e l’esenzione da malfunzionamenti inaccettabili. Vale a dire che il sistema deve avere una probabilità inferiore a un limite tollerabile, definito dal contesto, di provocare un incidente grave. Inoltre, attraverso un’opportuna analisi e sperimentazione, si deve garantire che il prodotto sia esente da malfunzionamenti inaccettabili anche a fronte di guasti. In un’analisi del rischio possiamo dire che questo dipende essenzialmente dalla frequenza di verifica di situazioni pericolose e dalle conseguenze derivanti da queste situazioni. Questi due fattori sono utilizzati per classificare il rischio. Secondo CENELEC 50126, esistono sei differenti livelli per la classificazione della frequenza di accadimento: dal più frequente (A) a quello meno frequente (F); mentre ci sono quattro classi per il livello di gravità. La tabella 2 pone in evidenza le definizioni comunemente utilizzate in contesti in cui esista un livello di rischio di esposizione di persone, ambiente e beni materiali a situazioni pericolose con possibilità di incidenti dovuti a malfunzionamenti causati da errori e/o guasti.
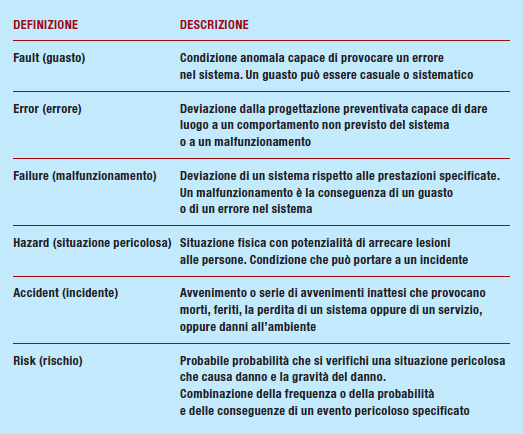
Tabella 2 - definizioni CEI EN 50126 – 50129
In questo articolo quando parliamo di software sicuro intendiamo che debba essere in grado di funzionare anche in presenza di errori subdoli, non necessariamente introdotti da un aggressore intelligente e con la chiara intenzione di compromettere la sicurezza del sistema, ma dovuti a errori di implementazione o malfunzionamenti hardware. Il fine di questo articolo non è quello di approfondire gli aspetti della certificazione e della sicurezza, ma semmai quello di mettere in evidenza alcuni accorgimenti che un progettista software può utilizzare per rendere il proprio lavoro più affidabile.
Programmazione difensiva
Quando si parla di programmazione difensiva, o secure programming, si devono considerare gli aspetti della qualità del software e del design dell’applicazione. Così, la programmazione difensiva è l’insieme delle attività che tendono a un design delle applicazioni inteso a garantire il funzionamento a dispetto di un uso scorretto delle stesse, con l’obiettivo di migliorare il codice delle applicazioni per mezzo di un aumento della qualità. Secondo questa metodologia, nulla è dato per scontato e tutti gli errori devono essere opportunamente gestiti tentando di evitare i potenziali problemi, come mostrato nel listato 1.
Listato 1 – possibile problema
int mio_programma (char * input)
{
char stringa[256];
strcpy (str,input);
...
...
}
| Listato 1 |
In questo caso se si manifesta un’anomalia (errore), non è generato nessun errore; infatti, se sono introdotti più di 256 caratteri come input (anche se una circostanza del genere non dovrebbe esistere), non esiste nessuna azione di recovery, ma si avrà sicuramente un buffer overflow exploit. Secondo la programmazione difensiva, una possibilità del genere non deve esistere. Una tecnica del genere giustifica l’inserimento di codice supplementare in grado di tracciare e rilevare flussi anomali di dati e controllo. In questo caso può essere utile, in riferimento al listato 1, inserire dei controlli dell’intervallo dei valori delle variabili e dei parametri dei sottoprogrammi. Utilizzando linguaggi evoluti, come Ada e Modula-2, sicuramente questo lavoro è insito nel compilatore, ma utilizzando un linguaggio come il C è necessario riprodurre “a mano” i controlli altrimenti inseriti in maniera trasparente in Ada o in Modula-2. Per questa ragione, utilizzare una tecnica di questo tipo vuol dire approntare una serie di azioni:
» ridurre la complessità del codice poiché un codice complesso è più difficile da gestire e potenzialmente introduce minori errori;
» fase di test: è necessario verificare i risultati intermedi della progettazione e sviluppo, introdurre sequenze di test esaustive per coprire i requisiti applicabili, pensare a realizzare test esaustivi del software per tentare di eliminare errori di implementazione;
» controllo dei puntatori rispetto ai limiti fisici delle memorie. In alcune applicazioni si sconsiglia di utilizzare strutture dinamiche, ma solo statiche;
» controllo del numero di iterazioni di un ciclo;
» limitare l’uso di strutture dati “sensibili”, magari permettendo il loro accesso attraverso un array con un indice, piuttosto che ricorrere a un puntatore;
» revisione del codice sorgente. Attraverso opportune attività di audit sul codice è possibile stanare potenziali bug;
» utilizzare meccanismi di CRC e checksum per tutelare la comunicazione tra moduli, soprattutto quando è necessario scambiare dati sensibili tra due sistemi, magari per questioni di ridondanza. Non solo, con lo stesso meccanismo può essere opportuno proteggere strutture dati utilizzate all’interno di un’applicazione, per esempio la tabella di schedulazione di un microkernel. Ogni tabella, o struttura dati, può essere dotata di una firma rigenerata dopo gli accessi in scrittura e verificata prima di ogni accesso;
» l’uso dei puntatori deve essere ponderato. Per esempio, in caso di un’anomalia un puntatore potrebbe uscire dallo spazio del programma causando, di conseguenza, comportamenti anomali;
» considerare l’uso, quando è molto giustificato, della sicurezza reattiva e composita del software.
Sicurezza e funzioni
Come spiegato in precedenza, in un sistema dove è prioritaria la sicurezza diventa necessario introdurre strumenti di controllo. Fortunatamente esistono diversi strumenti automatici che permettono di svolgere delle verifiche sul codice statico, le quali, se condotte correttamente, possono dare delle indicazioni utili per calibrare il lavoro di progettazione del software. Il riquadro dei riferimenti mette in evidenza alcuni di questi strumenti. Per garantire la necessaria integrità di dati sensibili può succedere di utilizzare tecniche definite come integrity checker. Sistemi di questo tipo si occupano di controllare porzioni di memoria, siano esse strutturate o meno. Per fare questo lavoro, queste tecniche “congelano”, come una fotografia, le componenti sensibili desiderate. La prima volta, quando siamo in uno stato corretto e conosciuto, associano a queste strutture un’informazione univoca in grado di assicurar nell’integrità, per esempio un CRC. Questa informazione è messa in una zona protetta ed è costantemente, o a richiesta, utilizzata per controllare se sono state apportate delle modifiche, magari dovute a malfunzionamenti della memoria o, in sistemi suscettibili a modifiche “maliziose” alle componenti tenute sotto controllo. Questi integrity checker si dividono in due grandi categorie: file integrity checker e memory integrity checker. Nei sistemi a dimensioni ridotte di solito si utilizza il memory integrity checker. Per spiegare l’importanza dei memory integrity checkers ci serviamo di un classico esempio. Linux, e la maggioranza dei sistemi operativi, gestisce le sue chiamate di sistema (o syscall) attraverso un vettore, syscall table[ ], i cui elementi sono puntatori a funzioni; le funzioni puntate sono le syscall che il kernel mette a disposizione ed è definito una sorta di mappa, in un apposito header, fra l’indice del vettore e il nome mnemonico della syscall a esso associata. Ora, sapendo che all’indice 1, al quale è associato l’identificativo della chiamata a sistema per la terminazione di un processo, è possibile invocare la funzione di terminazione direttamente con l’istruzione (syscall table[ NR exit])(0). A questo punto ci sono due strade per inficiare il contenuto dell’array: o provocare un attacco deliberato o la memoria, in un determinato momento, ha dei malfunzionamenti. In tutti i casi, la lettura del puntatore alla funzione richiesta non darà l’esito previsto, ma in realtà nel program counter sarà presente un indirizzo fuori dello spazio di indirizzamento previsto. In tutti i moderni kernel è possibile caricare un codice run-time, ciò risulta molto utile specialmente per i driver di supporto a periferiche hardware; tale porzione di codice on-demand in Linux viene chiamata modulo. Un possibile attacco potrebbe essere di questo tipo: all’interno del modulo malevolo vi sono delle istruzioni che vanno a sostituire uno o più indirizzi della tavola delle syscall, in questo modo successive chiamate a tali syscall non eseguono più il codice originale della syscall ma del codice tutto nuovo, scritto deliberatamente per ottenere determinati comportamenti. Questo è sicuramente un attacco deliberato al nostro apparato ed è usato per ottenere effetti di offuscamento all’interno del sistema vittima. Infatti, modificando le syscall giuste è possibile rendere invisibili connessioni, processi in esecuzione, file presenti nel filesystem, parti di file, moduli caricati in memoria o altro. Lo scopo di un memory integrity checker è quello di controllare che non siano state eseguite manipolazioni sulle parti critiche del kernel residente in memoria.
Le funzione e lo stack
Un altro aspetto da non sottovalutare è la manipolazione dello stack delle funzioni. Ogni funzione dispone di uno stack (program stack) per tracciare il flusso delle esecuzioni, per tenere memorizzato il punto di ritorno, la lista degli argomenti e le variabili locali. Lo stack supporta il nesting delle chiamate, vale a dire è creato uno stack frame per ogni sottoprogramma chiamato ed è successivamente distrutto al termine della funzione stessa. In un’architettura IA-32, l’indirizzo del frame corrente si trova in un registro di sistema (EBP) e per referenziare le informazioni è utilizzato un frame pointer. Lo stack di ciascuna funzione viene modificato per diverse ragioni: durante la chiamata, per inizializzare la funzione e per inserire il ritorno della funzioni. Le figure 1, 2 e 3 mostrano le modifiche della memoria stack nei diversi momenti di una funzione.

Figura 1: Return to calling function.
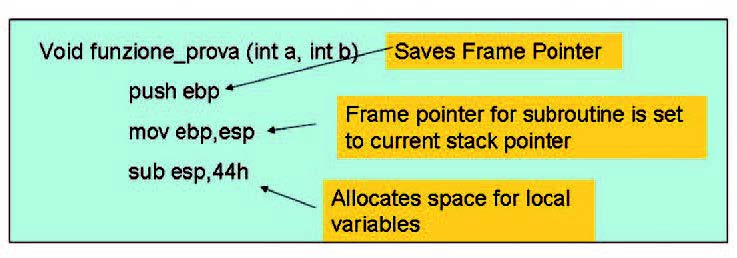
Figura 2: Function Initialization.
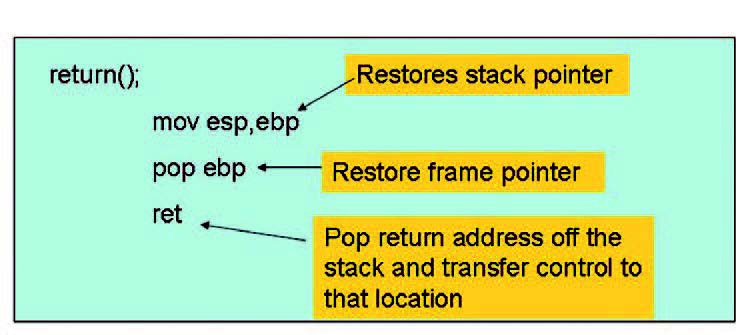
Figura 3: function return.
Lo stack di una funzione può essere corrotto senza grossi problemi. Così, in riferimento al listato 4, se inseriamo in ingresso alla funzione una stringa superiore a 11 caratteri, per esempio, 20, allora si ottiene una violazione dell’integrità dello stack.
Listato 4 – gestione password
bool PasswordOK() {
char Password[12]; // Memory storage for pwd
gets(Password); // Get input from keyboard
if (!strcmp(Password,”MiaPass”)) return(true); // Password OK
else return(false); // Password KO
}
int main()
{
bool PwStatus; // Password Status
puts(“Enter Password:”); // Print
PwStatus=PasswordOK(); // Get & Check Password
if (!PwStatus) {
puts(“Access denied”); // Print
exit(-1); // Terminate Program
}
else puts(“Access granted”);// Print
}
| Listato 4 |
Infatti, con la definizione di Password[12] si vuole indicare di riservare una zona di memoria di 11 caratteri più il carattere speciale NULL. Per questa ragione con 20 caratteri in ingresso, nove byte di memoria presenti sulla memoria stack vanno a modificare le strutture dati messe correttamente dal processore per la gestione dei vari puntatori e dell’indirizzo di ritorno (figura 4).
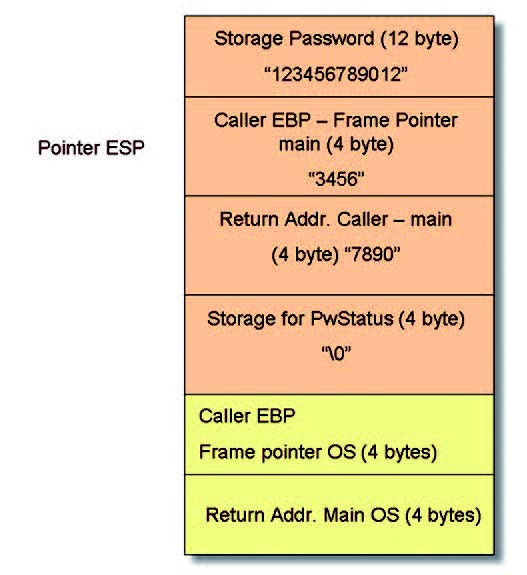
Figura 4: corruzione dello stack.
Questa è una delle ragioni per convincersi della validità della programmazione difensiva nel codice sorgente.
Puntatori a funzioni
Infine, l’ultimo pericolo che andremo ad analizzare sono le jump tables, vale a dire l’uso di array di puntatori a funzioni. Normalmente implementazioni di questo tipo sono frequenti nel codice assembler perché garantiscono efficienza e velocità, oltre alla facilità di realizzazione utilizzando direttamente le istruzioni del processore che sfruttano l’indirizzamento indiretto. Al contrario, tabelle di questo tipo non hanno fortuna nei linguaggi quali il C, perché non è consigliabile un loro uso esteso. Implementazioni di questo tipo, infatti, sono facilmente sostituite con l’istruzione di switch. Il listato 2 mostra un possibile problema.
Listato 2 – esempio critico di funzione
void (*puntatore_funzione[])(void) = {fna, fnb, fnc, …, fnz};
void prova(const INT jump_index)
{
/* Call the function specified by jump_index */
Puntatore_funzione[jump_index]();
}
| Listato 2 |
Un’implementazione di questo tipo è sicuramente pericolosa perché la funzione in esame è accessibile da chiunque e non si cura di controllare i limiti sulla chiamata. Il listato 3, invece, mostra una realizzazione più giudiziosa.
Listato 3 – azione correttive adottate
void prova(uint8_t const jump_index)
{
static void (*puntatore_funzione[])(void) = {fna, fnb, fnc, …,
fnz};
if (jump_index < sizeof(puntatore_funzione) /
sizeof(*puntatore_funzione))
{
/* Call the function specified by jump_index */
Puntatore_funzione[jump_index]();
}
}
| Listato 3 |
Infatti, utilizzando una dichiarazione di tipo static all’interno della funzione, si impedisce la possibilità di accedere alla tabella delle funzioni, mentre utilizzando un uint8_t, vale a dire un unsigned su 8 bit, si introduce una protezione; infine, inserendo un controllo nell’istruzione condizionale possiamo senz’altro essere sicuri della validità della chiamata. Per motivi di prestazioni è possibile sostituire l’istruzione if con assert. Introducendo questi accorgimenti è possibile garantire discreti livelli di sicurezza al pari dell’istruzione switch. L’uso dello switch presenta tuttavia delle limitazioni. Per esempio, il listato 5 presenta un’istruzione switch con sei case. A volte può succedere di utilizzare un numero di case più alto, anche di diverse centinaia, e anche non contigui.
Listato 5 – switch con sei case
void test(uint8_t j const jump_index)
{
switch (jump_index)
{
case 0:
funzione_1();
break;
case 1:
funzione_2();
break;
…
case 6:
funzione_6();
break;
default:
break;
}
| Listato 5 |
Tutto questo provoca uno spreco di memoria e di flessibilità, fatto non tollerabile in un sistema dedicato. Per questa ragione un approccio come messo in evidenza nel listato 3 presenta senz’altro indubbi benefici. La programmazione difensiva è l’elemento che, sapientemente utilizzato, permette di sopperire alle esigenze di sicurezza nei sistemi embedded.
Conclusione
Questo articolo è solo un’introduzione alla problematica sui sistemi di sicurezza software. L’argomento infatti è di per sé troppo vasto per esaurirlo in un articolo. Prossimamente si approfondiranno tutti gli altri aspetti che hanno un ruolo determinate nel definire sicuro un sistema. Gli aspetti che approfondiremo sono quelli legati al ciclo di vita della sicurezza (safety life cycle), il piano della sicurezza (safety plan), il processo di sicurezza (safety process), la gestione della sicurezza (safety management), il dossier di sicurezza (safety case), l’integrità della sicurezza (safety integrity) e il livello di integrità della sicurezza (safety integrity level). Altro argomento che non occorre sottovalutare è la specifica dei requisiti di sicurezza (SRS), vale a dire una serie di attività che hanno l’obiettivo di identificare e documentare la sicurezza di un sistema.


