I modelli di reti neurali profonde (Deep Neural Network) possono richiedere giorni o addirittura settimane per l'addestramento su un set di dati di grandi dimensioni. Per non parlare delle difficoltà nell'avere un set di dati etichettati e di grandi dimensioni. Un modo per abbreviare questo processo consiste nel riutilizzare i pesi di un modello pre-addestrato. I modelli più performanti possono essere scaricati e utilizzati direttamente o integrati in un nuovo modello per cercare di risolvere i propri problemi di classificazione. Tale approccio prende il nome di Transfer Learning è sarà l'oggetto di discussione di questo articolo. Dopo un'introduzione generale all'argomento, affronteremo un esempio pratico nell'ambito dello sviluppo di reti neurali per applicazioni di visione artificiale.
Introduzione
Transfer Learning è un concetto che si può tradurre come apprendere un determinato compito partendo da una conoscenza pregressa. Questa conoscenza precedente viene trasferita dall'attività di origine alla nuova. Avviene cioè un riuso di ciò che è stato appreso in un contesto per migliorare la generalizzazione in un altro contesto. Il Transfer Learning ha il vantaggio di ridurre il tempo di addestramento per un modello di rete neurale e può comportare un minore errore di generalizzazione (overfitting).
Benefici del Transfer Learning
Problemi molto specifici richiedono un volume elevato di dati per essere affrontati con successo. Trovare i dati per l'addestramento non è facile. Inoltre, anche avendo dei dati in numero elevato non è così semplice né rapido mettere a punto un modello performante. La Figura 1 descrive un tipico sistema di apprendimento automatico. Per una particolare attività in un determinato dominio, il modello di apprendimento automatico è in grado di imparare e generalizzare bene. Tuttavia, se c'è una nuova attività, deve costruire un modello completamente nuovo, per poter generalizzare per quell'attività.
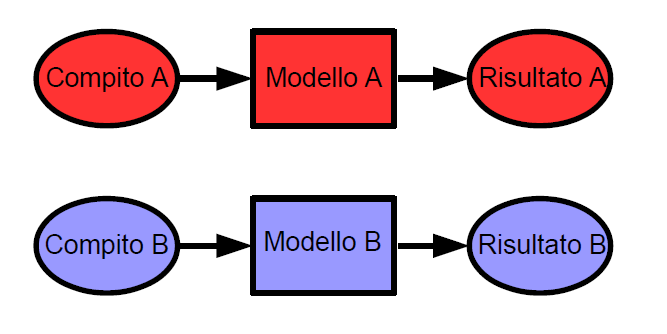
Figura 1: Con un approccio Machine Learning per risolvere i compiti A e B è necessario sviluppare due modelli partendo da zero
Fortunatamente, la community di Intelligenza Artificiale è così grande e ci sono così tanti lavori messi a disposizione al pubblico, tra set di dati e modelli pre-addestrati, che rende non conveniente costruire tutto da zero. Detto questo, i due motivi principali per cui dovremmo usare il Transfer Learning sono:
- L'addestramento di alcuni modelli di apprendimento automatico, in particolare le reti neurali artificiali che funzionano con immagini o testo, può richiedere molto tempo ed essere molto costoso dal punto di vista computazionale. Il Transfer Learning può alleggerire questo carico dandoci una rete già addestrata e che necessita solo di una fine regolazione.
- I set di dati per determinate attività sono molto costosi da ottenere. Il Transfer Learning ci consente di ottenere ottimi risultati in queste attività particolari con un set di dati molto più piccolo rispetto a quello di cui avremmo bisogno se affrontassimo il problema senza di esso.
Il Transfer Learning è in sostanza una scorciatoia per risparmiare tempo sull'addestramento, e risolvere un problema non risolvibile con i pochi dati a disposizione o semplicemente per cercare di ottenere prestazioni migliori. La Figura 2 illustra un esempio di Transfer Learning.

Figura 2: Nel Transfer Learning la conoscenza "generale" acquisita dall'attività A viene applicata all'attività B simile, risparmiando tempi e costi nello sviluppo e addestramento del modello
Quando usare il Transfer Learning
Prima di tutto, per utilizzare il Transfer Learning, le features dei dati devono essere generali, nel senso che devono essere adatte sia all'attività di origine che a quella di destinazione. Se le caratteristiche non sono comuni a entrambi i problemi, il trasferimento diventa, se possibile, molto più complesso. In secondo luogo, il Transfer Learning ha senso solo quando abbiamo molti dati per l'attività di origine e pochissimi dati per l'attività di destinazione. Terzo ed ultimo, le features di basso livello dell'attività d'origine devono essere utili per l'apprendimento dell'attività di destinazione. Se si provasse ad imparare a classificare le immagini di animali utilizzando l'apprendimento tramite trasferimento da un set di dati di nuvole, i risultati potrebbero non essere eccezionali.
In breve, se si dispone di un'attività di origine A e di un'attività di destinazione B si può prendere in considerazione l'utilizzo del Transfer Learning quando:
- Le attività A e B hanno lo stesso input x
- I dati per l'attività A sono molti di più di quelli per l'attività B
- Le features di basso livello dell'attività A sono utili per l'apprendimento dell'attività B
Come usare il Transfer Learning
Ci sono molti modelli pre-addestrati disponibili online, quindi c'è un'alta probabilità che ce ne sia uno adatto al problema specifico che si vuole risolvere. Una volta trovato il modello adatto, sarà comunque necessaria una seconda fase di addestramento con i dati per il problema specifico in modo da adattare il modello di origine al particolare compito da eseguire. La successione delle operazioni per applicare il Transfer Learning nel contesto del Deep Learning si può riassumere con i seguenti passi:
- Prendere i livelli (layer) dal modello d'origine addestrato
- Congelare i livelli, in modo da evitare di distruggere le informazioni che contengono durante le future fasi di addestramento
- Aggiungere alcuni nuovi strati addestrabili sopra gli strati congelati
- Addestrare i nuovi strati con il set di dati per lo specifico problema
Un ultimo passaggio facoltativo è il fine tuning, che consiste nello sbloccare l'intero modello ottenuto (o parte di esso) e ri-addestrarlo sui nuovi dati con un tasso di apprendimento molto basso. Ciò può potenzialmente far ottenere miglioramenti significativi, adattando in modo incrementale le features pre-addestrate ai nuovi dati.
Esempio
Un'ampia gamma di modelli ad alte prestazioni è stata sviluppata negli anni per la classificazione delle immagini. Questi modelli possono essere utilizzati come base nelle applicazioni di visione artificiale. In particolare, i modelli sviluppati per la sfida annuale denominata ImageNet, risultano molto attraenti poiché:
- hanno imparato a rilevare caratteristiche generiche dalle immagini, essendo stati addestrati su più di 1.000.000 di immagini per 1.000 classi;
- presentano prestazioni all'avanguardia e facilità d'accesso, essendo i pesi dei modelli forniti come file scaricabili gratuitamente e molte librerie forniscono API convenienti per scaricare e utilizzare direttamente i modelli.
I pesi del modello d'origine possono essere scaricati e utilizzati nella stessa architettura del modello di destinazione utilizzando una gamma di diverse librerie per il Deep Learning, inclusa Keras. Un modello può essere scaricato e utilizzato così com'è o per altri scopi. Possiamo riassumere alcune delle modalità di utilizzo di un modello pre-addestrato:
- Classificatore - il modello pre-addestrato viene utilizzato direttamente per classificare nuove immagini;
- Estrattore di features autonomo - il modello pre-addestrato, o una parte di esso, viene utilizzato per pre-elaborare le immagini ed estrarre le features pertinenti;
- Estrattore di features integrato - il modello pre-addestrato, o una parte di esso, è integrato in un nuovo modello, ma i livelli del modello pre-addestrato vengono congelati durante l'addestramento;
- Inizializzazione dei pesi - il modello pre-addestrato, o una parte di esso, viene integrato in un nuovo modello e gli strati del modello pre-addestrato vengono addestrati insieme al nuovo modello.
Ogni approccio può essere efficace e far risparmiare tempo significativo nello sviluppo e nell'addestramento di un modello di rete neurale profonda. Potrebbe non essere chiaro quale utilizzo del modello pre-addestrato possa produrre i migliori risultati nella nuova attività di visione artificiale, pertanto potrebbero essere necessari alcuni esperimenti.
Modello
Keras è un'API di Deep Learning scritta in Python, in esecuzione sulla piattaforma di Machine Learning TensorFlow. È stata sviluppata con l'obiettivo di consentire una rapida sperimentazione. Keras fornisce l'accesso a una serie di modelli pre-addestrati ad alte prestazioni che sono stati sviluppati per attività di riconoscimento delle immagini. Tali modelli sono disponibili tramite l'API applications e includono funzioni per caricare un modello con o senza i pesi pre-addestrati e preparare i dati nel modo in cui un dato modello li accetta in input (ridimensionamento delle dimensioni e dei valori dei pixel). Per il nostro esempio andremo ad usare il modello Xception, pre-addestrato sul set di immagini ImageNet. Xception è una rete neurale convoluzionale profonda con 71 strati. La rete è stata addestrata su più di un milione di immagini dal database ImageNet. La rete pre-addestrata può classificare le immagini in 1000 categorie (classi) di oggetti, come tastiera, mouse, matita e molti animali. Di conseguenza, la rete ha appreso rappresentazioni ricche di features per un'ampia gamma di immagini. [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2409 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
Domus 1.0 – Sistema di controllo con gestione remota via Web

Protocollo a conoscenza zero: come migliorare la privacy nella blockchain

Sensori Spaziali

EOS-Book @2 il corso di microprogrammazione per tutti

Tema interessante e ben trattato che mi ha fatto pensare alla diffusione degli small data. Sono molti a sostenere che le aziende sposteranno la propria attenzione dai Big data agli Small data soprattutto perché questo significa attingere a fonti di dati molto più gestibili.