
Il trasferimento di stile è un metodo per fondere due immagini distinte e crearne una nuova. Non si tratta di una mera sovrapposizione o di un fotoritocco, ma della creazione di una nuova immagine che presenta il contenuto di una foto utilizzando però lo stile pittorico di un'altra immagine. Una rete neurale può essere addestrata per imparare uno o più stili pittorici ed in questo modo riuscire a riprodurre il contenuto di una foto utilizzando un particolare stile. In questo articolo vedremo come implementare una rete neurale pre-addestrata per il trasferimento dello stile in uno script in linguaggio Python.
Introduzione
Per introdurre il problema del trasferimento dello stile, iniziamo con un esempio. Supponiamo di fare una fotografia al nostro cane e di voler trasferire lo stile di Van Gogh su questa fotografia (Figura 1). Allora indicheremo la foto del nostro cane come l'immagine del contenuto, mentre indicheremo la foto di un qualsiasi dipinto di Van Gogh come l'immagine dello stile. L'uscita di un modello neurale per il trasferimento dello stile sarà un'immagine con gli oggetti presenti nell'immagine del contenuto ma resa in forma pittorica nello stile dell'immagine di stile. Questa immagine appena creata viene spesso definita immagine stilizzata.
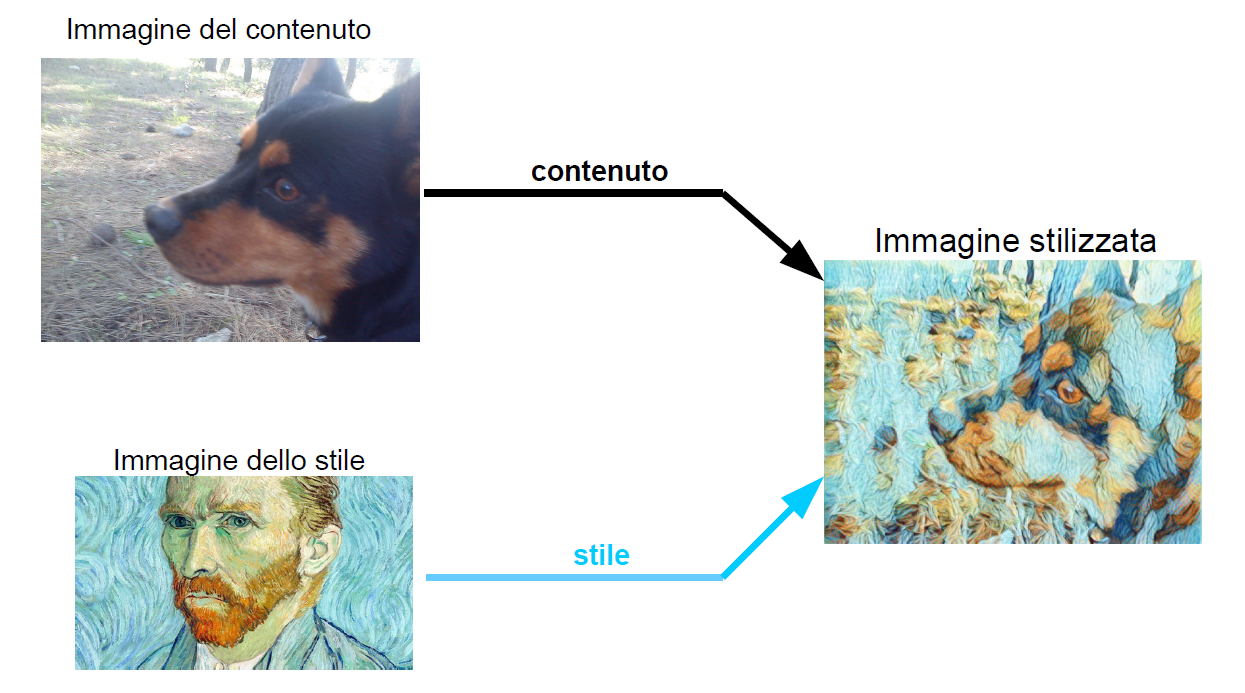
Figura 1: Esempio di trasferimento di stile
Per poter utilizzare questa tecnica non è necessario mettersi ad addestrare una rete neurale personalmente, poiché esistono modelli pre-addestrati messi a disposizione della community. Per questo articolo, trarremo vantaggio dai modelli forniti dal repository TensorFlow Hub. TensorFlow Hub è un repository di modelli di Machine Learning addestrati pronti per l'ottimizzazione e distribuibili ovunque. Svariati modelli pre-addestrati sono presenti nell'Hub per le più diverse applicazioni; quella che utilizzeremo noi è la rete di stilizzazione di immagini arbitrarie di Magenta. Magenta è un progetto di ricerca open source, supportato da Google, che mira a fornire soluzioni di Machine Learning nel campo artistico. Usando Magenta, si possono creare canzoni, dipinti, suoni e altro. Per questo articolo, useremo una rete per la stilizzazione arbitraria delle immagini.
Il modello
Il modello per la stilizzazione dell'immagine presente in TensorFlow Hub è un modulo in grado di eseguire il trasferimento rapido di stili artistici, che può funzionare su stili di pittura arbitrari. Questo modello è una versione ottimizzata per operare in tempo reale, del primo modello originale che è stato sviluppato per il trasferimento dello stile.
Separare stile e contenuto
Il modello originale venne presentato nel 2015 attraverso il paper "A Neural Algorithm of Artistic Style". Il modella utilizza rappresentazioni neurali per separare e ricombinare contenuto e stile di immagini arbitrarie, fornendo un algoritmo neurale per immagini artistiche. La classe di reti neurali profonde che è più potente nelle attività di elaborazione delle immagini è quella relativa alle reti neurali convoluzionali. Come base su cui sviluppare l'algoritmo venne usata la rete VGG, addestrata per il riconoscimento e la localizzazione di oggetti. Dell'originale rete VGG a 19 livelli fu usato lo spazio delle features fornito da una versione normalizzata di 16 strati convoluzionali e 5 di pooling. Generalmente, ogni strato nella rete definisce un banco di filtri non lineare la cui complessità aumenta con la posizione dello strato nella rete. Una data immagine di input è codificata in ogni strato della rete neurale convoluzionale dalle risposte dei filtri a quell'immagine. Per visualizzare le informazioni codificate nei diversi livelli della gerarchia si può eseguire la discesa del gradiente su un'immagine di rumore bianco fino a trovare un'altra immagine corrispondente il più possibile alle risposte delle features dell'immagine originale. Quando le reti neurali convoluzionali vengono addestrate per il riconoscimento oggetti, sviluppano una rappresentazione dell'immagine che rende le informazioni sugli oggetti sempre più esplicite nella gerarchia di elaborazione.
Pertanto, lungo i vari livelli della rete, l'immagine in ingresso viene trasformata in rappresentazioni sempre più sensibili al reale contenuto dell'immagine, ma che diventano relativamente invarianti rispetto al preciso aspetto. Quindi, i livelli più alti nella rete catturano il contenuto di alto livello in termini di oggetti e la loro disposizione nell'immagine di input ma non l'esatto valore dei pixel. La risposta delle features negli strati superiori della rete rappresenta quindi il contenuto dell'immagine. Per ottenere una rappresentazione dello stile di un'immagine di input, si può utilizzare uno spazio delle caratteristiche progettato in origine per acquisire informazioni sulla tessitura (texture). Questo spazio è costruito in cima alle risposte dei filtri di ogni layer. Esso consiste nelle correlazioni tra le diverse risposte dei filtri sull'estensione spaziale delle mappe delle caratteristiche. Includendo la correlazione delle features di più strati, otteniamo una rappresentazione stazionaria e multiscala dell'immagine di input, che acquisisce le informazioni sulla tessitura ma non la disposizione globale (Figura 2). Di nuovo, possiamo visualizzare le informazioni catturate da questi spazi di features sui diversi livelli della rete, costruendo un'immagine che corrisponda alla rappresentazione dello stile dell'immagine di input. Questo viene fatto utilizzando la discesa del gradiente su un'immagine di rumore bianco per ridurre al minimo la distanza quadratica media tra gli elementi delle matrici di Gram dell'immagine originale e le matrici di Gram dell'immagine da generare. [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2188 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:

La navigazione dei robot mobili basata sulla tecnologia LiDAR
