
Negli ultimi anni, i modelli generativi basati sul Deep Learning hanno guadagnato sempre più interesse, grazie alla loro incredibile capacità di produrre contenuti altamente realistici. Per addestrare un modello generativo, basta raccogliere prima una grande quantità di dati in un determinato dominio (ad esempio, pensiamo a milioni di immagini, frasi o suoni, ecc.) e poi addestrare il modello per generare dati simili. In questo articolo, focalizzeremo l'attenzione su uno di questi modelli, ovvero, gli Autoencoder Variazionali (VAE) e illustreremo una promettente applicazione di essi nel campo della creazione di arte digitale, il software DALL-E.
Introduzione
Diversamente dagli usi standard delle reti neurali per applicazioni di classificazione, gli autoencoder variazionali (VAE) sono potenti modelli generativi. I modelli generativi sono in grado di generare contenuti artificiali, come ad esempio l'immagine di un volto umano che non esiste nella realtà. I modelli generativi sono piuttosto noti al grande pubblico grazie alla Deepfake, una tecnica di sintesi di contenuti artificiali usata per creare falsi video ritraenti celebrità, sia per scopi di satira che per la creazione di fake news. Comunque, tra le applicazioni dell’Intelligenza Artificiale generativa spicca anche l'impiego nel mondo dell’arte, come la creazione di nuove opere digitali. In questo articolo, descriveremo come una tipologia di modello generativo chiamata autoencoder variazionali (VAE), venga sapientemente usata per creare opere artistiche originali grazie all'applicazione DALL-E sviluppata da OpenAI. Procederemo per passi, parlando prima di cosa sono gli autoencoder, quindi dei VAE fino ad arrivare a DALL-E.
Autoencoder
Gli autoencoder sono un tipo specifico di rete neurale in cui l'input e l'output sono dello stesso tipo. Gli autoencoder comprimono l'input in un codice ad inferiore dimensionalità e quindi lo ricostruiscono in uscita partendo da questa rappresentazione. Il codice è una compressione dell'input e viene chiamato rappresentazione nello spazio latente. Un autoencoder (Figura 1) è composto da 3 componenti principali: encoder, codice e decoder. L'encoder comprime l'input e produce il codice, il decoder ricostruisce l'input solo utilizzando questo codice.

Figura 1: Schema a blocchi dell'architettura di un autoencoder
Gli autoencoder sono principalmente un algoritmo di riduzione (o compressione) della dimensionalità con un paio di proprietà importanti:
- Specifico per tipo di dati: gli autoencoder sono in grado di comprimere in modo significativo solo dati simili a quelli su cui sono stati addestrati. Quindi non possiamo aspettarci che un autoencoder addestrato su cifre scritte a mano comprima le foto di paesaggi.
- Lossy: l'output dell'autoencoder non sarà esattamente lo stesso dell'input, ma sarà una rappresentazione degradata.
- Non supervisionati: per addestrare un autoencoder basta alimentarlo con i dati di input grezzi. Gli autoencoder sono considerati una tecnica di apprendimento non supervisionato poiché non necessitano di etichette esplicite su cui esercitarsi.
Sia l'encoder che il decoder sono reti neurali feed forward completamente connesse. Il codice è un singolo livello di una ANN con dimensionalità a scelta. Il numero di nodi nel livello di codice (dimensione del codice) è un iper-parametro che viene impostato prima di addestrare l'autoencoder. L'intera rete è solitamente addestrata nel suo insieme attraverso backpropagation. La funzione di perdita è solitamente l'errore quadratico medio tra l'output e l'input, noto come perdita di ricostruzione, che penalizza la rete per la creazione di output diversi dall'input. Poiché il codice ha dimensionalità ridotte rispetto all'input, il codificatore deve scegliere quali informazioni scartare. Il codificatore impara a preservare quante più informazioni rilevanti possibili nella codifica e a scartare in modo intelligente le parti irrilevanti. Il decoder impara a prendere la codifica e ricostruirla correttamente in un'immagine completa. Insieme, formano un autoencoder. Gli autoencoder imparano a generare rappresentazioni compatte dei loro input affinché possano essere ben ricostruiti. Ma un modello generativo, non può limitarsi a replicare la stessa immagine in ingresso.
Autoencoder Variazionali
Gli autoencoder non sono validi per la generazione di nuovi dati poiché lo spazio latente in cui convertono i loro input, e dove si trovano i vettori codice, non è continuo. Creare nuovi dati si traduce in campionare casualmente dallo spazio latente o generare variazioni su un'immagine di input, da uno spazio latente continuo. Se lo spazio presenta discontinuità (ad es. spazi tra i cluster) e si campiona/genera una variazione da lì, il decodificatore non ha idea di come gestire quella regione dello spazio latente. Durante l'addestramento, non ha mai visto vettori codificati provenienti da quella regione di spazio latente. Gli autoencoder variazionali (VAE) hanno una proprietà fondamentalmente unica che li separa dagli autoencoder standard, ed è questa proprietà che li rende così utili per la modellazione generativa: i loro spazi latenti sono continui, consentendo un facile campionamento casuale e la possibilità di interpolazione tra cluster. Il trucco risiede nel fare in modo che l'encoder non emetta un vettore di codifica di dimensione N, piuttosto, emetta due vettori di dimensione N: un vettore di medie, μ, e un vettore di deviazioni standard, σ. In Figura 2 viene illustrato lo schema a blocchi dell'architettura di un autoencoder variazionale.
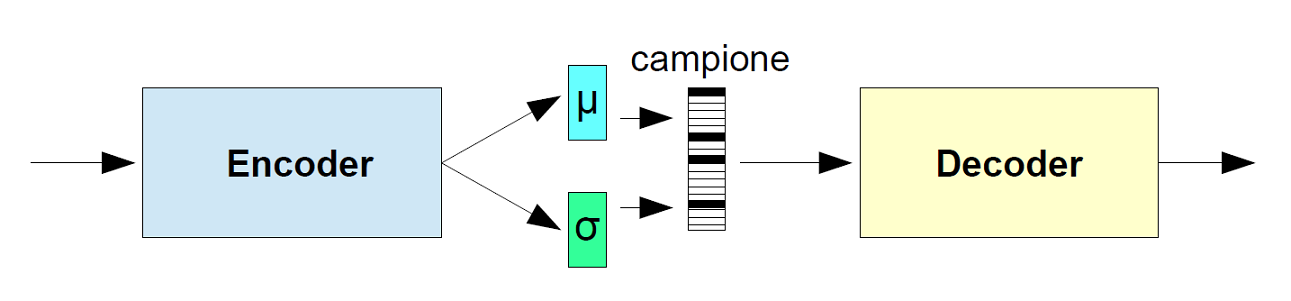
Figura 2: Schema a blocchi dell'architettura di un autoencoder variazionale
Si viene così a creare un vettore X di variabili casuali di lunghezza N, dove l'i-esimo elemento dei vettori μ e σ sono rispettivamente la media e la deviazione standard dell'i-esima variabile casuale Xi. Da ognuna delle Xi, costituenti il vettore X, viene quindi campionato un valore generando così il codice da passare al decoder. Questa generazione stocastica implica che anche per lo stesso input, mentre la media e la deviazione standard rimangono le stesse, la codifica effettiva varierà leggermente ad ogni singolo passaggio semplicemente a causa del campionamento. Il decoder è esposto ad una serie di variazioni della codifica dello stesso ingresso durante l'addestramento. In questo modo, apprende che non solo un singolo punto nello spazio latente si riferisce a un campione di quella classe, ma anche che tutti i punti vicini si riferiscono alla stessa classe. Il decoder allora non si limiterà a decodificare specifici singoli codici dello spazio latente, ma anche quei codici che differiscono leggermente da essi.
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2010 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.



