
Con questo articolo andremo a terminare la presentazione delle caratteristiche dell'SDK denominato Edge Impulse. Edge Impulse permette di realizzare modelli di apprendimento automatico e facilita la loro distribuzione su dispositivi embedded. Nella prima parte abbiamo preso in considerazione un tutorial per creare un modello di apprendimento automatico capace di riconoscere il suono di un rubinetto aperto immerso in rumore di fondo. Dopo la prima fase di impostazione eravamo giunti alla progettazione di un Impulso, da dove ripartiremo oggi.
Progettare un impulso
Con l'addestramento impostato, si può progettare un impulso. Un impulso prende i dati grezzi e li suddivide in finestre più piccole, quindi utilizza:
- blocchi di elaborazione del segnale per estrarre features
- un blocco di apprendimento per classificare i nuovi dati
I blocchi di elaborazione del segnale restituiscono sempre gli stessi valori per lo stesso input e vengono utilizzati per semplificare l'elaborazione dei dati grezzi, mentre i blocchi di apprendimento apprendono dalle esperienze passate. Per questo tutorial useremo il blocco di elaborazione del segnale "MFCC". MFCC è l'acronimo di Mel Frequency Cepstral Coefficients. Sembra spaventoso, ma fondamentalmente è solo un modo per trasformare l'audio non elaborato, che contiene una grande quantità di informazioni ridondanti, in una forma semplificata. Passeremo quindi questi dati audio semplificati in un blocco di rete neurale (blocco di apprendimento), che imparerà a distinguere tra le due classi di audio (rubinetto e rumore). Nella pratica basta andare alla scheda "Create impulse". La prima cosa che si vede aprendo questa sezione è un blocco dati Raw ("Raw Data").
Come accennato in precedenza, Edge Impulse suddivide i campioni grezzi in finestre che vengono inserite nel modello di apprendimento automatico durante l'addestramento. Il campo "Window size" controlla la lunghezza, in millisecondi, di ciascuna finestra di dati. Un campione audio di un secondo sarà sufficiente per determinare se un rubinetto è aperto o meno, quindi è necessario assicurarsi che la dimensione della finestra sia impostata su 1000 ms. Ogni campione Raw viene suddiviso in più finestre e il campo "Window increase" controlla l'offset di ciascuna finestra successiva dalla prima. Ad esempio, un valore di aumento della finestra di 1000 ms comporterebbe l'avvio di ogni finestra 1 secondo dopo l'inizio di quella precedente. Impostando un "Window increase" più piccolo della dimensione della finestra, possiamo creare finestre che si sovrappongono. Questa è in realtà un'ottima idea. Sebbene possano contenere dati simili, ogni finestra sovrapposta è ancora un esempio univoco di audio che rappresenta l'etichetta del campione. Utilizzando finestre sovrapposte, possiamo sfruttare al massimo i dati di addestramento. Ad esempio, con una dimensione della finestra di 1000 ms e un aumento della finestra di 100 ms, possiamo estrarre 10 finestre uniche da soli 2 secondi di dati. Per il nostro esempio useremo una finestra lunga 1000 ms e un campo di aumento della finestra impostato su 300 ms. Quindi, facendo clic su "Add a processing block" si può scegliere il blocco "MFCC". Mentre, cliccando "Add a learning block" si può selezionare il blocco "Neural Network (Keras)". Per finire basta cliccare su "Save impulse". L'impulso creato dovrebbe apparire come in Figura 1.
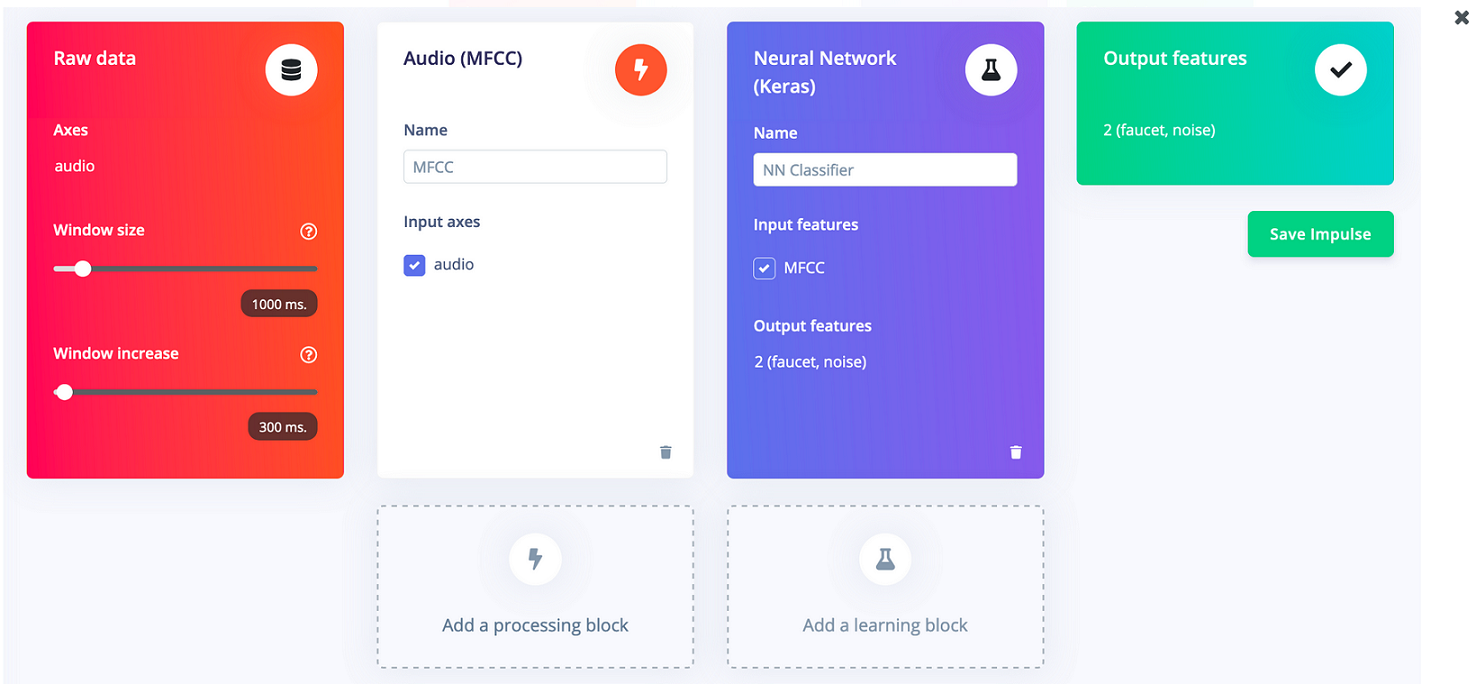
Figura 1: creazione dell'impulso
Configurazione del blocco MFCC
Ora che abbiamo assemblato i mattoni del nostro Impulso, possiamo configurare ogni singola parte. Facendo clic sulla scheda MFCC nel menu di navigazione a sinistra, si entrerà nella pagina di configurazione del blocco e che consente di vedere in anteprima come verranno trasformati i dati. La parte destra della pagina mostra una visualizzazione dell'output dell'MFCC per un brano audio, noto come spettrogramma. Il blocco MFCC trasforma una finestra audio in una tabella di dati in cui ogni riga rappresenta un intervallo di frequenze e ogni colonna rappresenta un arco di tempo. Il valore contenuto in ciascuna cella riflette l'ampiezza del suo intervallo di frequenze associato durante quell'arco di tempo. Lo spettrogramma mostra ogni cella come un blocco colorato, la variazione dell'intensità del colore dipende dall'ampiezza. In Figura 2 vengono comparati visivamente gli spettrogrammi del rumore (in alto) e del suono del rubinetto (in basso).

Figura 2: comparazione degli spettrogrammi del rumore (in alto) e del suono del rubinetto (in basso)
Le differenze non sono necessariamente facili da vedere per una persona, ma fortunatamente sono sufficienti per una rete neurale per imparare a classificare. Esistono molti modi diversi per configurare il blocco MFCC, come mostrato nella casella "Parameters". Edge Impulse fornisce impostazioni predefinite ragionevoli che funzioneranno bene per molti casi d'uso, quindi possiamo lasciare questi valori invariati. Gli spettrogrammi generati dal blocco MFCC verranno passati ad una rete neurale che è particolarmente brava ad imparare a riconoscere schemi in questo tipo di dati tabulari. Prima di addestrare la nostra rete neurale, dovremo generare blocchi MFCC per tutte le nostre finestre di audio. Per fare ciò, occorre cliccare sul pulsante "Generate feature" nella parte superiore della pagina, quindi cliccare sul pulsante verde "Generate feature". Con 10 minuti completi di dati di addestramento, il completamento del processo richiederà alcuni minuti. Una volta completato questo processo, "Features explorer" mostrerà una visualizzazione del set di dati. Qui la riduzione della dimensionalità viene utilizzata per mappare le funzioni su uno spazio 3D ed è possibile utilizzare "Features explorer" per vedere se le diverse classi si separano bene o trovare dati con etichetta errata (se visualizzati in un cluster diverso).
Configurazione della rete neurale
Le reti neurali sono algoritmi, modellati liberamente sul cervello umano, che possono imparare a riconoscere i modelli che compaiono nei loro dati di addestramento. La rete che stiamo addestrando prenderà l'MFCC come input e proverà a mapparlo su una delle due classi: rumore o rubinetto. Facendo clic su "NN Classifier" nel menu a sinistra si aprirà la finestra di configurazione del blocco. Una rete neurale è composta da strati (layers) di "neuroni" virtuali, rappresentati sul lato sinistro della pagina. Un input, nel nostro caso uno spettrogramma MFCC, viene immesso nel primo strato di neuroni, che lo filtra e lo trasforma in base allo stato interno unico di ciascun neurone. L'output del primo layer viene quindi immesso nel secondo layer e così via, trasformando gradualmente l'input originale in qualcosa di radicalmente diverso. In questo caso, l'ingresso dello spettrogramma viene trasformato su quattro strati intermedi in soli due numeri: la probabilità che l'ingresso rappresenti rumore e la probabilità che l'ingresso rappresenti un rubinetto in funzione.
Durante l'addestramento, lo stato interno dei neuroni viene gradualmente ottimizzato e perfezionato in modo che la rete trasformi il proprio input nel giusto modo da produrre l'output corretto. Questo viene fatto inserendo un campione di dati di addestramento, controllando la distanza tra l'output della rete e la risposta corretta (l'etichetta, la label) e regolando lo stato interno dei neuroni per rendere più probabile la produzione di una risposta corretta la prossima volta. Se fatto migliaia di volte, questo si traduce in una rete addestrata. Una particolare disposizione di layer viene definita architettura e diverse architetture sono utili per compiti diversi. L'architettura di rete neurale predefinita fornita da Edge Impulse funziona bene per il progetto attuale, ma è anche possibile definire le proprie architetture. Prima di iniziare l'addestramento, è necessario modificare alcuni valori nella configurazione. Innanzitutto, impostare il "Number of training cycles" su 300. Ciò significa che l'intero set di dati verrà eseguito 300 volte attraverso la rete neurale durante l'addestramento. [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2144 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
Rilevamento delle intrusioni su rete CAN-bus con TinyML

Progettiamo una Sensor Network per i parametri ambientali – Parte 2

Veicoli a guida autonoma: la sfida futura per la e-mobility

Intelligenza Artificiale per il rilevamento dei difetti nei PCB
