
I dispositivi IoT con risorse limitate, come i sensori e gli attuatori, sono diventati onnipresenti negli ultimi anni. Ciò ha portato alla generazione di grandi quantità di dati in tempo reale, un obiettivo interessante per i sistemi di Intelligenza Artificiale. Tuttavia, l'implementazione di modelli di apprendimento automatico su tali dispositivi finali è quasi impossibile. Una soluzione consiste nello scaricare i dati su sistemi informatici esterni (come i server cloud) per un'ulteriore elaborazione, ma questo peggiora la latenza, comporta un aumento dei costi di comunicazione e aumenta i problemi di privacy. Per risolvere questo problema, si è cercato di collocare ulteriori dispositivi di elaborazione ai margini della rete, cioè vicino ai dispositivi IoT in cui vengono generati i dati.
Introduzione
Grazie alla crescita esplosiva della tecnologia di comunicazione wireless, negli ultimi anni il numero di dispositivi dell'Internet delle Cose (IoT) è aumentato vertiginosamente. È stato stimato che entro il 2025 oltre 30 miliardi di dispositivi saranno connessi a Internet. I dispositivi IoT hanno in genere una potenza di calcolo limitata e memorie di piccole dimensioni. Esempi di dispositivi IoT con risorse limitate sono sensori, microfoni, frigoriferi intelligenti e luci intelligenti. I dispositivi e i sensori IoT generano continuamente grandi quantità di dati, che sono di importanza fondamentale per molte applicazioni tecnologiche moderne, come i veicoli autonomi. Uno dei modi migliori per estrarre informazioni e prendere decisioni da questi dati è alimentarli con un sistema di apprendimento automatico. Sfortunatamente, le limitazioni nelle capacità di calcolo dei dispositivi a risorse limitate inibiscono l'implementazione di algoritmi di Machine Learning (ML) su di essi. Pertanto, i dati vengono scaricati su un'infrastruttura di calcolo remota, in genere server cloud, dove vengono eseguiti i calcoli. Il trasferimento dei dati grezzi ai server cloud aumenta i costi di comunicazione, provoca ritardi nella risposta del sistema e rende i dati privati vulnerabili alla compromissione. Per risolvere questi problemi, è naturale pensare di elaborare i dati più vicino alle loro fonti e di trasmettere solo i dati necessari a server remoti per un'ulteriore elaborazione.
L'Edge Computing
L'edge computing si riferisce all'esecuzione di calcoli il più vicino possibile alle fonti di dati. Aggiungendo dispositivi di analisi vicino ai dispositivi a risorse limitate in cui vengono generati i dati, abbiamo proprio l'edge computing. La Figura 1 fornisce una panoramica dell'architettura dell'edge computing.
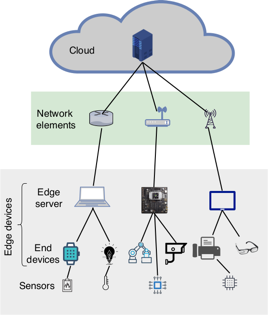
Figura 1: Panoramica dell'architettura dell'Edge Computing (Credit: Machine Learning at the Network Edge: A Survey, M.G. Sarwar Murshed, Christopher Murphy, Daquing Hou, Nazar Khan, Ganesh Ananthanarayanan, Faraz Hussain)
Quindi, i dispositivi edge possiedono sia capacità di calcolo che di comunicazione. Ad esempio, un dispositivo embedded come un braccio robotico potrebbe fungere da edge-device se prende i dati da una telecamera sul braccio ed esegue compiti di elaborazione dati che vengono utilizzati per determinare il movimento successivo. Poiché i dispositivi edge hanno una potenza di calcolo limitata, il consumo energetico è un fattore critico e i calcoli troppo pesanti per i dispositivi edge vengono inviati a server remoti più potenti. Il sistema edge-cloud è risultato essere il 36% meno costoso rispetto al sistema solo cloud. Inoltre, il volume di dati da trasferire è risultato inferiore del 96% rispetto al sistema basato solo sul cloud. Elaborando tutti i dati localmente, questo sistema non solo preserva la privacy dei dati, ma risparmia anche larghezza di banda. L'esecuzione di calcoli sul bordo della rete presenta quindi diversi vantaggi:
- Il volume di dati da trasferire a una postazione di calcolo centrale si riduce perché una parte di essi viene elaborata dai dispositivi edge.
- La vicinanza fisica dei dispositivi edge alle sorgenti di dati consente di raggiungere una minore latenza, migliorando le prestazioni di elaborazione dei dati in tempo reale.
- Nei casi in cui i dati devono essere elaborati in remoto, i dispositivi edge possono essere utilizzati per eliminare le informazioni di identificazione personale prima del trasferimento dei dati, migliorando così la privacy e la sicurezza degli utenti.
- La decentralizzazione può rendere i sistemi più resistenti agli attacchi esterni, fornendo servizi transitori durante un guasto alla rete o un attacco informatico.
Edge Computing e Machine Learning
Le moderne applicazioni del mondo reale, come le automobili autonome e i robot mobili, richiedono sempre più spesso capacità decisionali automatizzate rapide e accurate. I grandi dispositivi informatici possono fornire la potenza di calcolo necessaria in tempo reale, ma in molte situazioni è quasi impossibile implementarli senza incidere significativamente sulle prestazioni. I modelli di Machine Learning devono invece essere opportunamente modificati in modo da renderli adatti all'impiego su piccoli dispositivi edge che hanno una potenza di calcolo e una capacità di memorizzazione limitate. L'addestramento di modelli di apprendimento automatico, in particolare di modelli di Deep Learning (DL), richiede molta potenza di calcolo e un gran numero di esempi di addestramento. I dispositivi IoT a basso consumo, come le telecamere di bordo, sono fonti continue di dati, ma le loro limitate capacità di archiviazione e di calcolo li rendono inadatti per l'addestramento dei modelli Deep Learning. Nei sistemi con una gerarchia end-edge-cloud, l'addestramento centralizzato è un problema a causa della limitata larghezza di banda disponibile. Per risolvere tutti questi problemi, gli edge-server vengono sempre più spesso posizionati vicino ai dispositivi finali IoT e utilizzati per distribuire modelli Deep Learning che operano sui dati generati dall'IoT stesso. A causa della memoria e della potenza di calcolo limitate degli edge-devices, è importante modificare il modello in modo che possa adattarsi ed essere eseguito in modo efficiente su questi dispositivi. Pertanto, sono state sviluppate anche tecniche di compressione dei modelli ML per renderli più leggeri e veloci e per favorirne l'implementazione sull'edge. L'uso di modelli di ML in ambienti edge crea un'architettura di intelligenza distribuita. Per questo motivo, le grandi aziende tecnologiche, le industrie della difesa e la comunità open source sono state in prima linea negli investimenti nella tecnologia edge. Grazie all'interesse di questi settori è stato possibile sviluppare alcune soluzioni interessanti. È stata sviluppata, ad esempio, una nuova architettura chiamata Agile Condor che utilizza algoritmi di Machine Learning per eseguire compiti di Computer Vision (ad esempio video, elaborazione di immagini e riconoscimento di modelli) in tempo reale. Microsoft ha recentemente presentato HoloLens 21, un computer olografico integrato in una cuffia per un'esperienza di realtà aumentata; si tratta di un dispositivo versatile e potente che può funzionare offline e collegarsi al cloud. Microsoft intende progettare strumenti standard di calcolo, analisi dei dati, imaging medico e gioco all'avanguardia utilizzando l'HoloLens. La Linux Foundation, invece, ha recentemente lanciato il progetto LF Edge2 per facilitare le applicazioni all'avanguardia e stabilire un quadro comune open source indipendente dai sistemi operativi e dall'hardware. EdgeX Foundry3 è un altro progetto della Linux Foundation che prevede lo sviluppo di un framework per le applicazioni edge dell'IoT industriale.
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2192 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
L’Intelligenza Artificiale diventa quantistica

Implementare sistemi wireless su FPGA usando Matlab/Simulink
L’importanza dell’optoelettronica nella progettazione delle tecnologie per lo spazio

Misurazioni di test in real-time con Arduino e Raspberry Pi: sfide e soluzioni

Firmware 2.0 #49: Test & Measurements/Analog & Digital Signals
