
Le Restricted Boltzmann Machines (RBMs) costituiscono una classe di reti neurali per l'apprendimento non supervisionato con applicazioni che vanno dalla classificazione alla ricostruzione dello stato quantistico. Nonostante il loro potenziale potere, la diffusione delle RBM è piuttosto limitata poiché il loro processo di formazione si rivela difficile. L'avvento dei computer quantistici adiabatici commerciali (AQC) ha sollevato l'aspettativa che le implementazioni delle RBM su tali dispositivi possano aumentare la velocità di addestramento rispetto all'hardware convenzionale. In questo articolo cercheremo di capire la fattibilità di una RBM su computer quantistici adiabatici commerciali, grazie ad un embedding che associa i nodi delle reti neurali a qubit virtuali.
Introduzione
Esiste un modello di Intelligenza Artificiale chiamato Macchina di Boltzmann; la NASA aveva già sperimentato il trasferimento su un computer quantistico di questo tipo di AI, processo ispirato a quello adottato anche da Netflix per raccomandare i film. In quel caso i risultati erano limitati dall’aver impiegato un solo qubit per rappresentare ciascun neurone artificiale, dal momento che le connessioni da ogni qubit verso quelli limitrofi sul chip sono poche per motivi di spazio. Nel caso in oggetto, invece, si fa ricorso ad una tecnica chiamata embedding per raggruppare più qubit perché si comportino come un unico oggetto, il qubit virtuale. Il qubit virtuale eredita le connessioni di tutti i qubits che lo compongono, e quindi la connettività del nostro cervello quantistico è più elevata e si ha un apprendimento più rapido.
Macchine di Boltzmann e computer quantistici adiabatici commerciali
Gli algoritmi di apprendimento senza supervisione dovrebbero essere potenziati dall'avvento del calcolo quantistico pratico. Tuttavia, il raggiungimento di un vantaggio computazionale rispetto all'architettura informatica basata su logiche binarie classiche, per problemi di dimensioni utili è ancora in corso, principalmente perché l'hardware quantistico è in una fase iniziale di sviluppo. Per accelerare il processo, le tecniche di sintesi hardware devono essere costantemente aggiornate per sfruttare tutto il potenziale delle unità di elaborazione quantistica.
Le Macchine Boltzmann (BM) sono un importante esempio di algoritmo di apprendimento senza supervisione, introdotto nel 1985 da Ackley, Hinton e Sejnowski. È stato dimostrato che un BM addestrato può essere utilizzato come approssimatore universale delle distribuzioni di probabilità su variabili binarie. Tale proprietà rende le BM particolarmente adatte, se usate come modello generativo, per ricostruire dati parzialmente mancanti. Nonostante tale potere, uno dei passaggi dell'algoritmo di addestramento rende l'algoritmo di calcolo costoso, per addestrare BM di grandi dimensioni. Si tratta di un passaggio che richiede di estrarre campioni dalla distribuzione istantanea approssimata dal BM. Il costo per produrre ogni campione cresce rapidamente all'aumentare della dimensione del problema. Pertanto, i BM sono solitamente non applicabili a problemi di dimensioni interessanti. Per ottenere la loro piena potenza, sarebbe necessario un metodo di formazione che si adatti alle dimensioni e alla complessità di un aumento del BM.
Nel corso degli anni, i BM hanno trovato applicazione principalmente in una forma semplificata, chiamata Macchina Boltzmann Ristretta (RBM). Le RBM hanno un potere inferiore rispetto ai BM, ma sono più facili da addestrare e utilizzare. A causa della loro popolarità, gli RBM vengono solitamente scelti come benchmark per valutare i potenziali vantaggi degli algoritmi di apprendimento quantistico. Dal 2011, i ricercatori hanno esplorato la possibilità di utilizzare un AQC, computer quantistici adiabatici commerciali, per approssimare la distribuzione di probabilità necessaria durante l'addestramento di un RBM. I risultati sperimentali suggeriscono che un AQC può essere utilizzato per estrarre campioni dalla distribuzione associata a un RBM, al costo computazionale di una singola operazione quantistica. Pertanto, il campionamento da AQC sembra avere un costo che non dipende dalle dimensioni o dalla complessità dell'RBM.
L'AQC è considerato uno strumento hardware utile per addestrare gli RBM. Più specificamente, si ritiene che gli RBM addestrati sugli AQC abbiano un vantaggio computazionale quantistico. Gli AQC possono essere usati per produrre campioni di alta qualità, meglio del metodo MCMC (Monte Carlo Monte Carlo), abbassando l'errore di classificazione quando usati nella fase di sfruttamento di un RBM addestrato. Gli RBM addestrati vengono testati per rilevare i guasti nei processi industriali. Vale la pena notare che, in parallelo, alcuni approcci non quantistici hanno mostrato un vantaggio asintotico simile a quello promesso dai computer quantistici. Generalmente, si usano algoritmi di apprendimento profondo, per ottenere il controllo dei qubit per la preparazione degli stati quantici. Il nuovo studio di cui parliamo, invece, segue un approccio diverso poiché combina l'apprendimento automatico con la potenza di calcolo dell'hardware quantistico stesso.
Addestramento di un RBM con un AQC
Utilizzando un AQC per addestrare un RBM abbiamo risultati di un caso piuttosto ristretto; tuttavia, sono elementi costitutivi fondamentali per reti più complesse. Questo metodo di apprendimento ha introdotto anche un’operazione preliminare che si potrebbe paragonare a un’inversione dello scorrere del tempo nel computer quantistico, chiamata reverse annealing. Con altri metodi si lascia che il sistema durante l’apprendimento ricerchi le soluzioni da imparare iniziando da uno stato di partenza generico. Il nuovo metodo, invece, parte da una soluzione nota; tramite il reverse annealing si porta il sistema ad un migliore stato di partenza, come se si riavvolgesse il nastro del tempo per qualche microsecondo, e poi si procede con la ricerca che, a sua volta, dura alcuni microsecondi.
Una Macchina Boltzmann può essere rappresentata da un grafico composto da unità che possono assumere valori binari {0, 1}, collegate da connessioni pesate e reali. Le unità sono divise in due classi, visibile e nascosta. In generale, un BM ha connessioni tra qualsiasi coppia di unità, mentre un RBM è bipartito, senza connessioni nascoste - nascoste o visibili - visibili. La Figura 1b mostra la struttura di una RBM 16 × 16, utilizzata in questo studio.
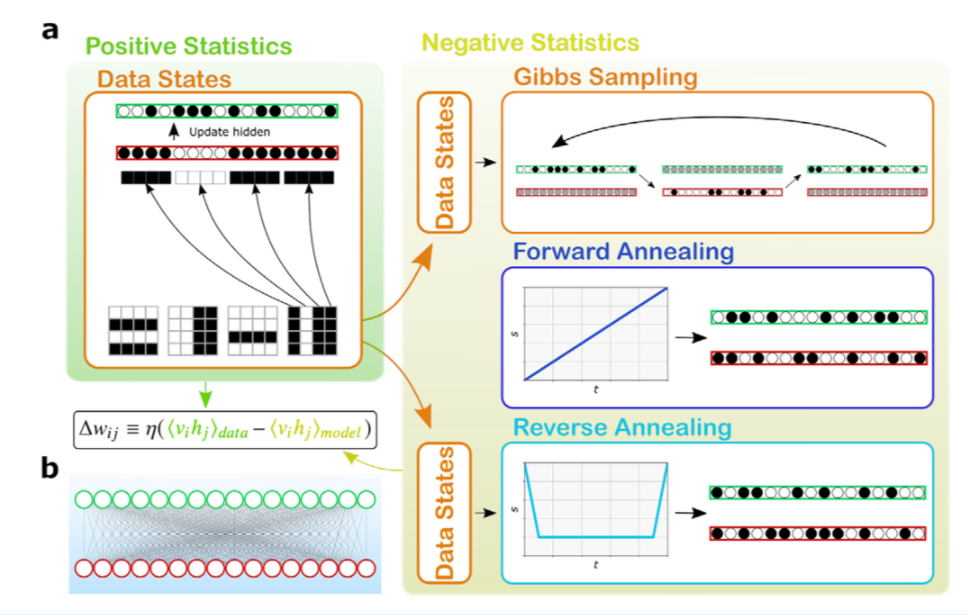
Figura 1: a) Panoramica schematica dei metodi per addestrare una RBM. Le caselle verde e gialla mostrano quale parte del gradiente è stimata da ogni fase dell'algoritmo. I passaggi che richiedono solo calcoli classici sono cerchiati in arancione. Gli elementi del dataset vengono caricati nelle unità visibili (rosso) e le unità nascoste (verde) vengono aggiornate di conseguenza. Il risultato consente la stima delle statistiche positive. Successivamente, si effettua il campionamento per stimare le statistiche negative. b) Struttura della macchina Boltzmann ristretta utilizzata nell'articolo, con 16 unità visibili completamente collegate a 16 unità nascoste. Fonte: Quantum Semantic Learning by Reverse Annealing of an Adiabatic Quantum Computer, Lorenzo Rocutto, Claudio Destri and Enrico Prati
Prima dell'addestramento, i pesi vengono inizializzati in modo casuale, secondo una certa distribuzione di probabilità. Per codificare le informazioni è necessario un processo di formazione che modifichi adeguatamente i pesi del BM. Un BM addestrato può accettare un'informazione incompleta e ricostruire le parti mancanti in base a quelle acquisite in precedenza. Nel caso della ricostruzione di un'immagine, sia i pixel noti che quelli mancanti sono rappresentati univocamente da un'unità visibile. Le unità visibili corrispondono sia all'input che all'output del modello generativo. Infatti, quando si ricostruisce un'immagine corrotta, inizializziamo e correggiamo parte delle unità visibili, mentre le unità visibili non inizializzate restituiscono i pixel mancanti. Le unità nascoste, invece, conferiscono al BM il potere di estrarre le caratteristiche essenziali dal dataset. Un numero maggiore di unità nascoste aumenta la capacità del BM di imitare la struttura del set di dati.
Nel caso dell'RBM, poiché non ci sono connessioni tra unità nascoste, è abbastanza facile ottenere un campione imparziale di dati, se le unità visibili sono fissate ai valori di un vettore di addestramento, mediato su tutti i vettori dell'insieme di dati di addestramento. Questa si chiama statistica positiva. È necessario un singolo passaggio di campionamento per aggiornare le unità nascoste, ripetuto per ogni vettore di allenamento.
Ottenere un campione imparziale quando entrambe le unità visibili e nascoste sono prodotte dal modello è molto più difficile. Un calcolo esatto comporterebbe una somma su tutte le possibili combinazioni di valori per unità nascoste e visibili, il che significa sommare su 2N elementi. In molte situazioni pratiche, un calcolo esatto non è fattibile, quindi approssimiamo queste situazioni con il metodo seguente.
Inizialmente, i valori delle unità visibili sono posti uguali a quelli di un vettore di addestramento. Successivamente, applichiamo ripetutamente l'algoritmo di campionamento; una sequenza di configurazioni viene prodotta estraendo alternativamente i valori delle unità nascoste con le unità visibili fisse e i valori delle unità visibili con le unità nascoste fisse, calcolando la media del valore della sequenza. Ogni passaggio di questa sequenza ha lo stesso costo computazionale di una statistica positiva. Il processo viene ripetuto per ogni elemento del set di dati e ciò fornisce una stima del modello, che è effettivamente non distorta. Gli RBM in genere apprendono meglio se vengono utilizzati più passaggi di campionamento alternato, prima di raccogliere i vettori per le statistiche negative. [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 1980 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
