
In questo articolo affronteremo il problema della codifica con perdite, analizzando le tecniche predittive e con trasformata, che sono tra le più comuni nell'ambito delle codifiche video e audio. Le tecniche di compressione con perdite (lossy), sono tecniche nelle quali parte dell'informazione del messaggio originale viene perduta per sempre. Ci si potrebbe chiedere allora il perchè preferire questi algoritmi a quelli senza perdite (loseless) visti in un articolo precedente. Il motivo è semplice, e sta tutto nel tasso di compressione (data compression ratio) cioè nel rapporto tra la dimensione originale del messaggio e quella dopo la compressione.
Introduzione
Gli algoritmi loseless riescono a raggiungere un rapporto di compressione di 2:1 mentre quelli lossy anche di 50:1. Per dirla in parole povere, gli algoritmi lossy consentono di comprimere di più rispetto ai concorrenti senza perdite, ma al prezzo di ottenere in fase di decodifica solo un'approssimazione del messaggio originale. Perdere informazione può sembrare inaccettabile nella codifica di un messaggio, ma occorre considerare il fatto che non tutti i tipi di messaggi vengono recepiti allo stesso modo:
- ad esempio un testo o un software non possono perdere di informazione durante la codifica poichè l'integrità del messaggio è fondamentale per la comprensione di quest'ultimo. Per questo tipo di messaggi si preferisce dunque una codifica senza perdite.
- File audio o video invece possono perdere parti non necessarie di informazione, poichè i sensi umani (vista e udito) sono limitati nella loro percezione dei dettagli. Per questo tipo di messaggi si preferisce dunque una codifica con perdite.
Nella tabella 1 vengono classificati alcuni formati di uso comune in base alla tipologia di codifica utilizzata:
| Testuale | Immagine | Audio | Video | |
| Loselesss | ZIP | PNG | FLAC | Sheervideo |
| Lossy | JPEG | MP3,WMA | MPEG,DivX |
Tabella 1: classificazione formati in base alla codifica
Nel seguito di questo articolo andremo ad analizzare le due principali categorie di codifiche con perdite: quelle predittive e quelle con trasformazione. Prima però occorrerà una breve introduzione ad alcuni concetti di base, necessari per meglio comprendere il funzionamento delle codifiche.
Distorsione e quantizzazione
Con le codifiche di tipo lossy sorge il problema di quanto si possa comprimere il messaggio senza eccedere nella perdita di informazione. Nelle codifiche di sorgente senza perdite avevamo visto che l'entropia H di una sorgente rappresentava il più piccolo numero medio di bits/simbolo con cui si poteva codificare il messaggio in uscita. L'entropia rappresentava quindi il limite inferiore (lower bound) per le lunghezze di codici applicabili a quella sorgente. Similmente, nelle codifiche con perdite, il ruolo dell'entropia è svolto dalla teoria Tasso-Distorsione (Rate-Distortion). Definiamo R come il tasso di codifica espresso in bit/campione, e D come la distorsione di codifica ovvero il grado di perdita dell'informazione. In una codifica con perdite lo scopo principale è quello di ottenere un tasso di codifica minimo con la minima distorsione. La teoria tasso-distorsione fornisce gli strumenti matematici per valutare il limite inferiore (lower bound) di questa ricerca. Il concetto di distorsione, quindi, si lega a quello di qualità della codifica, ovvero quanto i dati ricostruiti distano da quelli originali. La qualità a sua volta dipende dall'applicazione con cui si ha a che fare, per questo esistono differenti tipi di misure di distorsione a seconda dei singoli casi applicativi. Tra le più comuni c'è sicuramente l'errore quadratico medio (MSE):
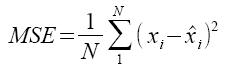 Dove N rappresenta il numero di campioni su cui si svolge la media mentre la sottrazione viene fatta tra il campione originale xi e quello approssimato in uscita dal decodificatore. Il principale colpevole della perdita di informazione nelle codifiche lossy è rappresentato dal processo di quantizzazione. La quantizzazione insieme al campionamento rappresentano i blocchi base del processo di conversione analogico - digitale. Possiamo definire un quantizzatore Q di dimensione N (intero positivo) come una funzione che associa ad un elemento x ∈ RN, un elemento di un set finito di cardinalità K.
Dove N rappresenta il numero di campioni su cui si svolge la media mentre la sottrazione viene fatta tra il campione originale xi e quello approssimato in uscita dal decodificatore. Il principale colpevole della perdita di informazione nelle codifiche lossy è rappresentato dal processo di quantizzazione. La quantizzazione insieme al campionamento rappresentano i blocchi base del processo di conversione analogico - digitale. Possiamo definire un quantizzatore Q di dimensione N (intero positivo) come una funzione che associa ad un elemento x ∈ RN, un elemento di un set finito di cardinalità K.
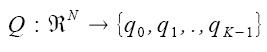 Gli elementi indicati con la lettera q sono numeri reali seppur appartenenti ad un insieme discreto. In base al valore che assume N si distinguono due casi notevoli:
Gli elementi indicati con la lettera q sono numeri reali seppur appartenenti ad un insieme discreto. In base al valore che assume N si distinguono due casi notevoli:
- per N = 1, avremo un quantizzatore scalare;
- per N > 1, avremo un quantizzatore vettoriale.
Gli elementi del dominio, nella funzione Q, sono infiniti, e devono essere associati ad elementi di un insieme finito. Per realizzare Q, occorre quindi suddividere il dominio in tanti intervalli quanti sono gli elementi del codominio. Tali suddivisioni prendono il nome di intervalli di quantizzazione e vengono indicati con il carattere Δ. Ogni valore compreso in un intervallo viene cosi associato ad un valore del set. La figura 1 mostra un esempio con N pari a 1.
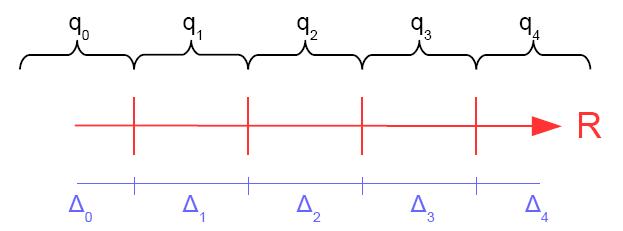
Figura 1: esempio di quantizzazione
Codifiche predittive
Pulse code modulation (PCM)
Il modo in cui suddividere il dominio (uniforme o non uniforme) e il modo di associarne i valori con il set finito, variano molto a seconda dell'applicazione specifica. In questo [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2810 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
L’amplificatore operazionale nel design di circuiti elettronici

EOS-Book @4 RFID & NFC
Un sistema IoT di controllo remoto degli attuatori con l’ESP32

Regolatori a commutazione SIMO per le applicazioni portatili

Con queste due puntate interessanti abbiamo visto un’ottima panoramica sulle codifiche di sorgente file/audio/video. Alcune volte forse appare lapalissiano l’argomento, ma dietro c’è una bella teoria che vale la pena conoscere!