
Quindi, in soldoni, un sistema operativo è un programma che gira, all’insaputa di tutti gli altri programmi, e che gestisce il loro funzionamento. Fondamentalmente, un sistema operativo serve per convincere tutti i processi in giro per il sistema che tutte le risorse del sistema stesso sono a loro completa e incondizionata disposizione, e che nessun altro gliele sta contendendo. Il sistema operativo riesce ad ottenere questo risultato grazie a due concetti di base: uno, decide lui chi va in esecuzione, quando e per quanto tempo; due, tutti gli accessi alle risorse del sistema (memoria, dispositivi e quant’altro) passano attraverso di lui. In pratica, nessun programma è in grado di accedere direttamente alla memoria, ma il massimo che può fare è chiedere (gentilmente) al sistema operativo se (per cortesia) accede per lui alla memoria e gli legge quel dato di cui ha tanto bisogno. Oggi vi parleremo di come un processo possa eseguire queste richieste.
DUE MONDI SEPARATI
Bene, questa sembra una cosa abbastanza semplice. Il nostro sistema operativo avrà delle librerie con implementate tutte le funzioni che è in grado di offrirci, il che significa che possiamo fare quello che facciamo sempre quando abbiamo a che fare con delle librerie: andiamo su internet, cerchiamo nella documentazione la funzione che ci serve, e aggiungiamo una chiamata nel punto in cui ci serve. Bè, se ragionate come uno sviluppatore di applicativi, avete perfettamente ragione. Tuttavia, come abbiamo detto più volte, uno sviluppatore software scrive software come se non ci fosse un domani, ossia con la convinzione che tutto il sistema sia a sua completa e incondizionata disposizione, e che sono cavoli del sistema operativo fare in modo che sia così.
Il fatto che però in realtà sulla macchina girino più processi, e comunque sempre uno e uno solo per volta (visto che la CPU è una), non è un fattore trascurabile. Se la CPU sta eseguendo il vostro processo, sta eseguendo solo quello, né più né meno: non sta eseguendo altri processi e, più importante ancora, non sta eseguendo il sistema operativo. Il sistema operativo è inattivo, come gli altri eventuali processi che potreste aver avviato. Quindi, se effettuate una chiamata al sistema operativo, e il sistema operativo è inattivo, chi riceverà mai quella chiamata? Se la risposta che vi è salita alle labbra è “nessuno”, potreste aver capito qual è il problema. Non si può chiamare direttamente il sistema operativo, per il semplice fatto che o la CPU la usate voi, o lui.
C’è anche un altro problema, più sottile. Abbiamo visto come il sistema operativo sia codice che viene eseguito “in modalità kernel”, ossia con particolari privilegi, privilegi che, per quello che ci interessa qui, equivalgono a codice che non può essere interrotto da eventi provenienti dal mondo esterno. Dunque, non potete chiamare direttamente il sistema operativo anche perché il codice del vostro processo non è codice in modalità kernel, e quindi non ha questi particolari privilegi.
Tutto però funzionava quando il nostro processo veniva interrotto da un evento esterno, come abbiamo visto parlando del timesharing. L’interrupt proveniente dal timer provocava la sospensione del processo corrente, il passaggio in modalità kernel, e l’esecuzione del codice del sistema operativo, in quel caso la routine di gestione dell’interrupt e poi lo scheduler. Anche in questo caso ci serve qualcosa di simile, ossia una strategia per interrompere il processo, passare in modalità kernel e poi fare qualcosa. Forse ne sarete sorpresi, ma le chiamate al sistema operativo sono molto, molto simili a degli interrupt.
FARSI DA PARTE
Se vi è mai capitato di sfogliare un libro di sistemi operativi (uno di quelli noiosissimi con tanto scritto, tanto pseudo codice e pochissime figure), forse vi sarà capitato di sentirvi dire che in realtà esistono due tipi di interruzioni (sì, nei testi di sistemi operativi di solito traducono anche la parola “interrupt”): quelle hardware e quelle software. Le interruzioni hardware le conosciamo già, sono quelle che arrivano da eventi esterni, come un mouse, una tastiera o un timer. Quei libri vi diranno che si tratta di interruzioni “asincrone”, dal momento che possono verificarsi in qualsiasi momento. Le interruzioni software sono la stessa cosa, eventi che forzano la sospensione del processo in esecuzione, ma generate non da un evento esterno, bensì dal processo stesso. I libri vi diranno che, essendo generate dal processo stesso, queste interruzioni sono “sincrone”, visto che non possono capitare, ad esempio, mentre la CPU sta eseguendo un’istruzione, come potrebbe capitare con un interrupt hardware, ma solo dopo che ha finito di eseguire l’istruzione corrente.
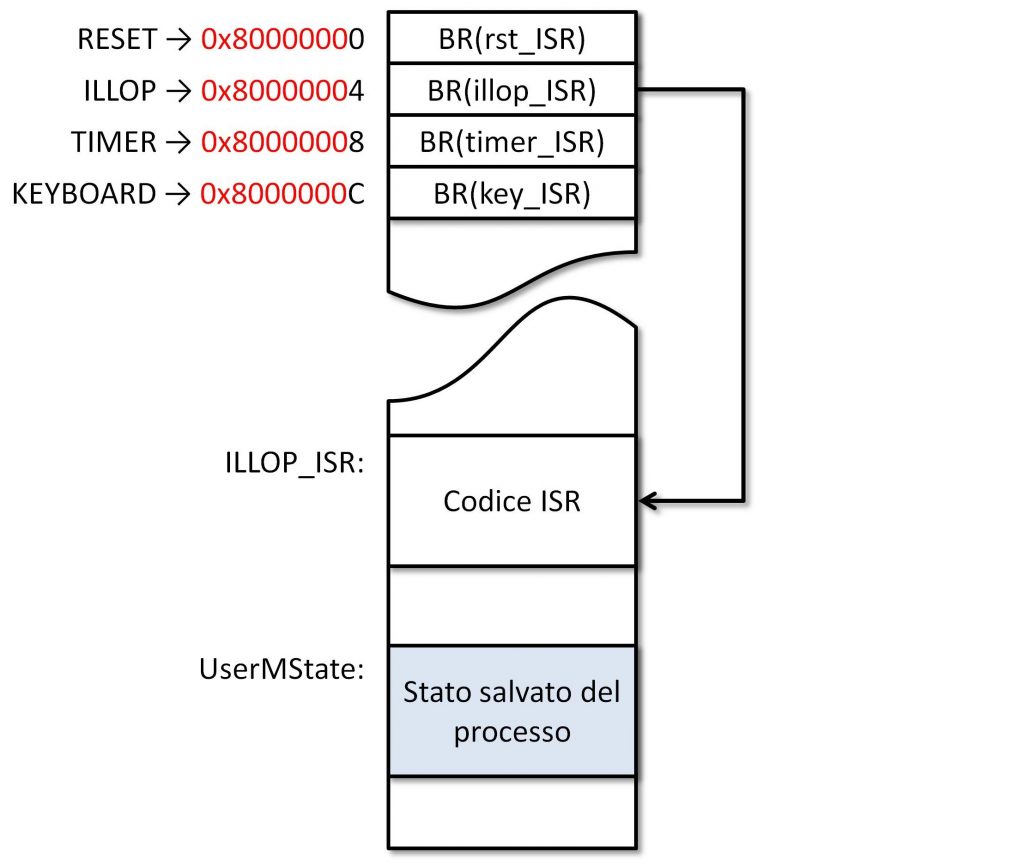
Figura 1: Mappa della memoria
In questa sincronia c’è la chiave per capire come implementare queste cose: le interruzioni software (o eccezioni, o trap) sono esse stesse delle istruzioni! Ma non istruzioni appartenenti al set che avete così pazientemente progettato e implementato, no: sono istruzioni illegali. Se ci pensante, in effetti quando si accorge di non conoscere l’opcode dell’istruzione corrente, il processore reagisce più o meno nello stesso modo in cui si comporta quando riceve un interrupt esterno: salva l’indirizzo dell’istruzione successiva (PC + 4) in un registro opportuno (il registro XP, nel nostro caso), e carica un valore predefinito del program counter, esattamente come faceva per gli interrupt.

Figura 2: ISR per ILLOP
Vediamo un pò cosa deve fare questa nuova ISR. Bè, innanzitutto fa la stessa cosa che fanno tutte le ISR dotate di un pò di decenza: salva tutti i registri del processore, così da consentire la ripresa dell’esecuzione del processo utente alla fine di tutto, e carica lo stack pointer del kernel. Quel save_all_regs() che vedete nel codice della Figura 2 è semplicemente una macro che raccoglie tutte le store che servono a salvare i valori dei registri.
Poi seguono un paio di istruzioni interessanti. Facciamo un piccolo passo indietro. Lo scopo qui è richiedere dei servizi al sistema operativo, giusto? Bene, stiamo implicitamente presupponendo che il sistema operativo sia in grado di offrire più servizi, non uno soltanto. In questo caso, come specificare quale servizio stiamo chiedendo? La soluzione ovvia è, visto che stiamo facendo tutto sostanzialmente aggiungendo istruzioni al nostro set, usare un opcode diverso per ogni servizio che vogliamo richiedere.
La soluzione è sì ovvia e può andare bene oppure no, a seconda dei casi. Il nostro set di istruzioni ha opcode a 6 bit, il che significa 2 alla sesta istruzioni possibili, ossia 64. Non sono tante. Considerate che un numero più o meno grande di queste istruzioni saranno istruzioni legali, che quindi non possiamo usare per identificare un servizio. Quanti spazi vuoti ci sono nella mappa dipende da quante istruzioni legali abbiamo, e a seconda dei casi potrebbe essere un numero congruo oppure no.
In generale, per stare tranquilli, è meglio fare in un altro modo. Su 32 bit di istruzione, solo 6 sono per l’opcode. Se l’istruzione è legale, quei 26 bit restanti hanno un senso, altrimenti possiamo farne ciò che vogliamo. Quindi, se usiamo un unico opcode per identificare quell’istruzione illegale che alla fine richiederà un servizio al sistema operativo, ci restano 26 bit che possiamo usare per codificare i servizi richiesti; 2 alla 26 fa un bel pò di servizi, e in più ci basta un solo spazio vuoto nella mappa per implementare tutti i servizi che vogliamo.
Quindi, torniamo alla Figura 2. La SUBC e la BR servono a caricare l’istruzione illegale che ha provocato l’eccezione, che poi andremo a interpretare per decidere il da farsi. La SUBC toglie quattro al registro XP, che contiene al solito l’indirizzo dell’istruzione successiva a quella incriminata. La BR è un altro paio di maniche e ci costringe a fare un altro passo, stavolta non indietro ma di lato.
Ricordate che, in un sistema con più processi, tutti gli indirizzi che la CPU presenta alla memoria sono indirizzi virtuali, non fisici. La memoria, con il TLB ed eventualmente una mano da parte del sistema operativo, tradurrà questi indirizzi virtuali in fisici e poi passerà alla CPU il contenuto della memoria alla locazione corretta. Ora, anche l’indirizzo associato all’istruzione illegale è un indirizzo virtuale, e per poter leggere questa famosa istruzione dobbiamo prima tradurre l’indirizzo da virtuale a fisico, poi accedere alla memoria, e poi interpretare l’istruzione.

Figura 3 (a): ReadUserMem

Figura 3 (b): ReadUserMem
La BR della Figura 2 salta al codice mostrato nella Figura 3. Questo codice non fa niente di particolarmente sensazionale: semplicemente, estrae numero di pagina virtuale e offset dall’indirizzo virtuale, e chiama a sua volta un’altra funzione, VtoP(), che esegue la traduzione vera e propria. Come venga effettivamente implementata questa traduzione dipende parecchio da come avete deciso di gestire la memoria. Se avete un TLB, per esempio, la traduzione potrebbe avvenire in hardware e dovrete gestire solo i page fault; se un TLB non ce l’avete, probabilmente dovrete gestire anche la traduzione in software.

Figura 4: VtoP
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2541 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
EOS-Book @5 Corso su Android dalla teoria alla pratica
Corso di Elettronica per ragazzi – Puntata 3
Domus 1.0 – Sistema di controllo con gestione remota via Web
Progetto step-by-step con Arduino OPTA e PLC IDE

Giochiamo con Arduino: strumento musicale ad ultrasuoni “no touch”
