Quali sono le considerazioni da tener presenti per sviluppare un kernel per la gestione di un ambiente multithread? in questo articolo vediamo quali sono le caratteristiche di minimal multithread (mmt), il nostro kernel didattico.
In questo articolo vedremo come realizzare un kernel per il multithreading, vedremo le considerazioni da tenere presenti e un’applicazione per ambiente windows. E’ possibile, poi, portare questo kernel verso altri ambienti grazie alla presenza di un Board Support Package.
Architettura del sistema
Le relazioni tra un programma di un generico utente e la nostra libreria MMT non è mediata da nessuna interfaccia: ogni porzione del codice utente è in grado di colloquiare con le primitive messe a disposizione. Per esempio, un programma utente crea i threads nel sistema utilizzando le chiamate che la libreria rende disponibile. Uno dei maggiori propositi del nostro lavoro è di avere un sistema estremamente portabile, in questo modo è possibile distribuire e utilizzare MMT in diversi ambienti di lavoro. L’obiettivo del nostro MMT è quello di ottenere un sistema estremamente flessibile. Infatti l’applicazione può andare bene su sistemi Solaris, Pthreads o anche Win32. In questo modo può essere utile provare il nostro algoritmo in un sistema ospite prima di andare direttamente su target.
Strutture dati
Ogni thread deve disporre di una serie di informazioni utilizzate, in fase di run-time, per gestire correttamente il suo flusso di esecuzione. Per esempio, esiste un solo thread che ha lo stato di running ed è il thread corrente in esecuzione. Solo il primo thread in testa alla coda dei READY può essere messo in esecuzione in un successivo cambio di contesto. Le informazioni che devono essere considerate e trattate in una idonea struttura dati sono, sicuramente, il suo thread identifier, il suo stato e la quantità di stack. La tabella 1 mostra alcune considerazioni sullo stato di un thread.

TABELLA 1 – LO STATO DEI THREAD
Il listato 1 for nisce un esempio tipico di una struttura di questo genere utilizzato in un header file in linguaggio C.
enum thread_state {
RUNNING,
READY,
SUSPENDED,
JOINING,
WAITING,
TERMINATED};
/* current status of the any task may be any one of the state */
struct {
jmp_buf context;
unsigned pmask;
unsigned priority;
unsigned /* altre informazioni da registrare*/
thread_state t_state;
} thread_info[MAXTASK];
| Listato 1 |
Chiaramente non esiste un vero parallelismo dei processi o thread, per farlo, in realtà, occorrerebbe disporre di risorse fisiche (CPU) in aggiunta a quello che disponiamo. Quello che ci proponiamo è di dare l’illusione del parallelismo alternando le esecuzioni delle singole unità di elaborazioni (le nostre funzioni in c) a fronte di eventi esterni o attraverso meccanismi di sincronizzazione. Il processo padre per noi è il programma vero e proprio messo a punto dall’utente con il suo spazio di indirizzamento, la sua occupazione, in termini di memoria e di risorse fisiche. I thread, in realtà, in questo modo, non sono altro che le funzioni dell’utente che diventano thread attraverso chiamate che MMT rende disponibili. In questo modo, MMT fornisce il modello d’esecuzione di cui necessitiamo per permettere il multithreading. Quando, nel corso di esecuzione, si rientra in un thread (funzione c dell’utente), l’esecuzione stessa continua dal punto esatto del precedente exit point. In figura 2 vediamo graficamente come si evidenzia questo comportamento.
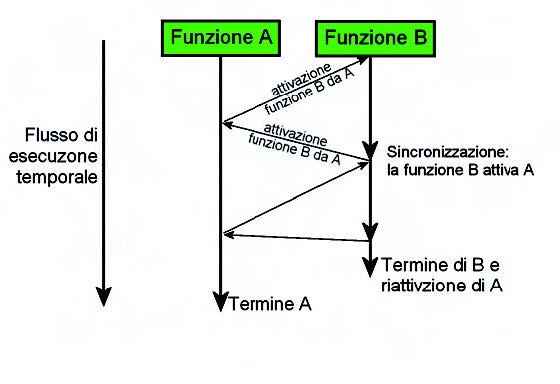
Figura 2: flusso temporale dei thread.
Di conseguenza, tutti i threads nel sistema, che sono di fatto delle funzioni, si comportano come delle unità di elaborazione in cui sono valide tutte le considerazioni in ordine di schedulabilità di un vero processo con alcune limitazioni. Il thread dispone di diversi punti di ingresso di un thread sono messi, oltre al la prima istruzione eseguibile della funzione, in modo arbitrario a seconda dei criteri di schedulazioni e di sincronismo. In questo modo, quando un thread è nello stato di Wait, esegue una delay, richiede il lavoro di un altro thread (join) o perché semplicemente termina: allora il thread è interrotto e lo schedulatore trasferisce il controllo verso un altro thread. Inoltre, quando, per qualsiasi ragione, un thread diventa eseguibile allora lo schedulatore lo pone in esecuzione dalla istruzione immediatamente successiva al punto in cui era stato interrotto.
Context switching
Ma come viene svolto questo lavoro di cambio di contesto tra differenti thread? Una tecnica è quella di utilizzare le prerogative della libreria ANSI C attraverso l’uso delle funzioni setjmp() e longjmp(): queste due funzioni permettono di cambiare il contesto di una funzione attraverso l’accesso un’istanza di una variabile di tipo jmp_buf. Quello che sta alla base di tutto è il concetto di stato del task; cioè quando si decide, per diversi motivi, di sospendere un task è necessario preservare il suo stato, cioè l’insieme di informazioni che sono necessarie ad un thread per riprendere il proprio lavoro in qualsiasi momento. I prototipi delle due funzioni dell’ANSI C, definiti in un file header setjmp.h, sono mostrati nel listato 2.
int setjmp( jmp_buf env ); void longjmp( jmp_buf env, int value );
| Listato 2 |
Questo è un tipo di salto incondizionato ed è reso possibile dalle funzioni setjmp e longjmp, infatti setjmp(jmp buf env) e longjmp sono utili, per esempio, per gestire errori ed interruzioni ricevute in una funzione fortemente annidata in un programma. setjmp() salva lo stack per essere utilizzato successivamente dalla longjmp(), longjmp non può usare 0 come valore di ritorno (secondo argomento). Se longjmp è invocato con un secondo argomento uguale a 0, allora è impostato automaticamente a 1. Le variabili che sono dichiarate globali o statiche non sono modificate quando viene eseguita la longjmp. Nell’implementazione di MMT utilizzeremo queste due funzioni per effettuare il nostro cambio di contesto. In questo modo, la funzione setjmp() prende come argomento la jump buffer, salva l’ambiente di esecuzione corrente (per esempio il contesto del thread) nella jump buffer e restituisce il valore 0, come vediamo dalla porzione di codice:
if (setjmp(current_thread->context)==0)
Quindi, in sostanza salva il suo ambiente chiamante nell’argomento di tipo jmp_buf, per un successivo utilizzo da parte della funzione longjmp. Viceversa, la funzione longjmp() ha due argomenti: jump buffer e un intero. Il controllo dell’esecuzione è trasferito alla locazione registrata in jump buffer, rimette a posto l’ambiente di esecuzione e forza il corrispondente setjmp mediante il valore 1. Il comportamento della longjmp() è quello di ripristinare l’ambiente salvato dalla più recente invocazione della macro setjmp nella stessa chiamata del programma, con il corrispondente argomento di tipo jmp_buf. Il parametro di setjmp è utile per determinare se si proviene da un salto o da una invocazione. Le operazioni di questo tipo sono abbastanza pericolose, infatti, l’esecuzione di longjmp potrebbe corrompere lo stack. Questo può succedere quando da una funzione, dopo aver chiamato la setjmp(), chiamiamo un’altra funzione. La seconda chiamata a funzione è invocata ancora prima della creazione del suo stack frame e, di conseguenza, con la chiamata a setjmp() questa non dispone delle informazioni sulla seconda funzione. In questo modo, con la chiamata a longjmp() il ritorno dalla seconda funzione non è realizzabile. La soluzione per ovviare a questo problema è quello di utlizzare porzioni di stack differenti per ogni thread. Cioè, quando creiamo un thread è necessario indicare lo spazio di stack necessario per eseguire il thread stesso e tutte le sue eventuali funzioni che dipendono dal thread. In MMT, quando è creato un thread viene richiesto uno spazio di stack dalla zona heap, in questo modo lo stack pointer è posto all’inizio di quest’area.
Thread Scheduler
In questa implementazione, lo schedulatore chiama una setjmp() per salvare l’ambiente corrente di esecuzione in un jump buffer: questo è parte del thread control block, e, successivamente, invoca la parte del dispatcher. Il seguente frammento di codice mostra una possibile realizzazione:
if (setjmp(&(Running->Context)) == 0) {
/* in questa sezione si deve spostare il thread nella ready queue */ chiama_lo_schedulatore()
}
É ovvio che lo schedulatore è una funzione senza ritorno. La funzione dell’ANSI C, longjmp(), è utilizzata per passare il controllo ad un altro thread. Così, per riassumere quanto scritto:
void scheduler(THREAD next_process)
{
/* mettiamo da qualche parte il contesto del processo corrente */
if (setjmp(current_thread->context)==0){
/* facciamo qualcosa nello schedulatore*/
longjmp(current_thread->context,1); /* passiamo il controllo ad un altro thread */
}
}
Le chiamate in MMT
Il sistema MMT fornisce una serie di interfacce utili per sfruttare le prerogative che mette a disposizione il sistema. Di seguito vediamo alcune funzioni:
- THREAD_SYS_INIT
Questa chiamata permette di inizializzare l’ambiente multithreading. La funzione deve essere chiamata prima di ogni altra API di MMT.
- THREAD_CREATE
Questa funzione trasforma una funzione C in un thread in ambiente MMT. In definitiva, prende il puntatore alla funzione e ai suoi dati, alloca uno spazio di stack dall’area heap. Se ha una priorità maggiore del thread corrente in esecuzione, allora lo sostituisce altrimenti è messo posto nella coda ready. Il parametro di ritorno di questa funzione è l’identificatore associato al thread.
- THREAD_EXIT
Questa funzione termina il thread chiamante e rende nuovamente disponibile lo stack allocato sulla zona heap.
- THREAD_TIME_SLICE
Questa interfaccia permette di inizializzare il sistema ad un determinato time slice. In questo modo il sistema MMT funziona con le prerogative di time slice.
- THREAD_JOIN
Questa interfaccia è utilizzata per cambiare il flusso di esecuzione tra thread.
- THREAD_PAUSE
Questa chiamata muove il thread chiamante nella coda dei thread ready e, lo schedulatore, pone in esecuzione il primo thread in cima alla ready queue. In questo modo si forza un cambio di contesto.
- THREAD_VERSION
Questa interfaccia permette di conoscere la versione di MMT.
- THREAD_GET_PRIORITY
Questa chiamata in MMT consente di conoscere la priorità associata ad un thread.
- THREAD_SET_PRIORITY
Questa interfaccia permette di cambiare la priorità di un thread.
- THREAD_GET_IDENTIFIER
Questa chiamata consente di conoscere il thread identifier del thread chiamante.
- THREAD_SUSPEND
Sospende l’esecuzione del thread corrente e lo pone nella coda di thread sospesi.
- THREAD_CONTINUE
Questa è l’operazione inversa. Cioè, pone un thread, mediante il suo identificatore, dalla coda dei sospesi nella coda ready.
- THREAD_SIGNAL
Questa interfaccia permette di inviare un signal ad un thread specifico individuato dal suo identificatore. Questa chiamata è utilizzata per sincronizzare thread differenti.
- THREAD_ON_SIGNAL
Con questa chiamata un thread si pone in uno stato di attesa su un determinato signal.
- THREAD_MUTEX_INIT
Questa funzione inizializza i mutex locks.
- THREAD_UNLOCK
Questa interfeccia consente di disabilitare la mutua esclusione di una regione critica
- THREAD_LOCK
Questa chiamata consente ad un thread di ottenere la mutua esclusione di una regione critica. In MMT si è scelto di implementare i cosiddetti mutex locks per realizzare le primitive di sincronizzazione assimilabili ai semafori. Ogni mutex locks ha un proprietario individuato dall’identificatore di un thread e una coda per gestire la sua politica di schedulazione, la wait list.
Per realizzare i mutex sono previsti tre primitive:
THREAD_MUTEX_INIT, THREAD_LOCK, THREAD_UNLOCK. É opportuno ricordare che un thread non può acquisire in modo ricorsivo lo stesso lock senza averlo, precedentemente, liberato attraverso la chiamata a THREAD_UNLOCK.
Il comportamento in MMT quando si vuole acquisire un lock è il seguente:
➤ Se il lock è già occupato, il thread che richiede il servizio viene messo in una coda in attesa della prima occorrenza del lock libero, la coda della wait list. In caso contrario, il thread che richiede il servizio diventa il proprietario del lock.
➤ In caso opposto, cioè quando un thread vuole sbloccare un lock il programma
applicativo dovrà utilizzare la chiamata THREAD_UNLOCK. Il parametro di ingresso di questa funzione è l’indentificatore di un lock. Se il thread che chiama il servizio non risulta esserne il proprietario, allora la richiesta verrà rifiutata, in caso contrario il lock è liberato e assegnato al primo thread in attesa nella wait list. considerazioni su AVR Come possiamo portare il nostro lavoro su AVR? Per prima cosa occorre rispondere, in realtà, ad un’altra domanda: esistono nel nostro ambiente di sviluppo quelle prerogative che ci permettono di supportare il nostro lavoro anche su AVR? Tutto quello che dobbiamo scoprire è se la cross-factory, o meglio la libreria del C, è in grado di darci strumenti quali Setjmp() e longjmp(). Con la libreria libc questo lavoro è senza dubbio fattibile.

