Qualsiasi programmatore di sistemi dedicati che utilizza soluzioni basate su System-onChips (SoCs) ha la necessità di utilizzare codice oggetto che coniuga aspetti di safety con quelli d’efficienza: il codice deve occupare poco spazio, deve garantire prestazioni paragonabili a quella d’esecuzione e utilizzare codice che sia il più efficiente possibile.
Per rispondere a queste esigenze occorre disporre di soluzioni appositamente realizzate. Utilizzare un compilatore GCC può non essere praticabile, è necessario modificarlo nella parte di back-end. Quando si parla di compilatori di solito si considerano due aspetti: il front-end e il back-end, vale a dire lo stato iniziale e finale di un processo computazionale. Il termine front-end è utilizzato per definire quell’insieme d’interfacce che un compilatore rende disponibili all’utente, il suo processo sintattico e semantico. Back-end, invece, rappresenta lo stadio finale del compilatore, la generazione, l’ottimizzazione del codice, la generazione del codice per un’architettura hardware particolare. Se il processo di back–end è articolato su diversi livelli di IRS (Intermediate Representations), allora si ha un codice generato più efficiente. I processi d’ottimizzazione e generazione del codice avvengono in passaggi graduali utilizzando diversi livelli di IRS, in questo modo si cerca di avvicinarsi il più possibile al codice finale: le ottimizzazione che non richiedono conoscenza dell’architettura della macchina avvengono in un primo livello, così, gradualmente nei livelli successivi, l’ottimizzazione e la generazione del codice, si sposano sempre più con il target fisico.
INTRODUZIONE
Con il termine XCC ci si riferisce al compilatore Xtensa C/C++ compiler, ed è basato sull’architettura GCC. Nell’implementazione XCC sono state apportate delle modifiche al processo di generazione del codice e di ottimizzazione. Sono state introdotte ottimizzazione chiamate interprocedural e tecniche software quali il loop pipelining per il parallelismo a livello d’istruzioni. In pratica, il compilatore XCC utilizza il front-end di GCC con la parte di back-end modificata e adattata per supportare Xtensa Instruction Set Architecture (ISA).
PRESTAZIONE
Esistono dei dati prestazionali che danno un’idea della potenzialità del compilatore. Infatti, come possiamo vedere dalla tabella 1 il compilatore XCC produce codice più efficiente rispetto alle architetture RISC confrontate, quali ARM. I dati sono stati ottenuti da EEMBC e per questo assumono una valenza importante.

Tabella 1. Prestazione del compilatore XCC
L’ente EEMBC (Embedded Microprocessor Benchmark Consortium) è un consorzio costituito da più di 40 compagnie. Lo scopo della sua attività è di fornire benchmark certificati per valutare le possibili applicazioni dei processori embedded. I membri di questo consorzio sono compagnie quali ARM, AMD, IBM, Intel, LSI Logic, MIPS, Motorola, National Semi, NEC, TI, Toshiba. Anche Tensilica è membro di EEMBC. Il compilatore di XCC genera densità di codice più alta rispetto agli compilatori RISC presenti in tabella. XCC rappresenta oggi sicuramente uno dei migliori compilatori in quanto incrementa la velocità di esecuzione del codice e riduce lo spazio occupato, per fare questo il compilatore adotta diverse tecniche quali: software pipelining, function inlining, Static Single Assignment (SSA).
Vediamo un esempio di un codice C generato per Xtensa e per ARM. Il codice è il seguente:
for (i=0; i < NUM; i++) if (histogram[i] != NULL) insert (histogram[i], &tree);
Il codice viene espanso con le seguenti notazioni assembler, con Xtensa occupa 7 istruzioni e 17 bytes:
L16: addx4 a2, a3, a5 l32i a10, a2, 0 beqz a10, L15 add a11, a4, a7 call8 insert L15: addi a3, a3, 1 bge a6, a3,L16
con ARM 8 istruzioni 36 bytes:
J4: ADD a1,sp,#4 LDR a1,[a1,a3,LSL#2] CMP a1,#0 MOVNE a2,sp BLNE insert ADD a3,a3,#1 CMP a3,#&3e8 BLT J4
Con Thumb 10 istruzioni e 20 bytes:
L4: LSL r1,r7,#2 ADD r0,sp,#4 LDR r0, [r0, r1] CMP r0,#0 BEQ L13 MOV r1,sp BL insert L13: ADD r7,#1 CMP r7,r4 BLT L4
OTTIMIZZAZIONI CON XCC
Vediamo in questa sezione alcune caratteristiche di questo compilatore. Il compilatore supporta l’estensione verso il linguaggio TIE (Tensilica Instruction Extension), cioè la register allocation e l’instruction scheduling. Vediamo di seguito un esempio di istruzione TIE (ADD4):
#ifdef NATIVE
#include ADD4_cstub.c
#endif
int a[ ], b[ ], c[ ];
char *x=a, *y=b, *z=c;
... read(x); read(y);
for (i = 0; i < n; i++) {
c[i] = ADD4(a[i], b[i]);
}
write(z);
...
In figura 1 vediamo come viene rappresentata, in maniera semantica, l’istruzione. Il compilatore XCC supporta il Tensilica’s Flexible Length Instruction Xtensions (FLIX) e automaticamente estrae il parallelismo del codice C/C++, fino a 15 operazioni indipendenti (il limite esiste sulla disponibilità degli opcode) in 32 o 64 bit VLIW bundle. XCC utilizza una tecnica di ottimizzazione conosciuta come feedback-directed optimization (FDO).
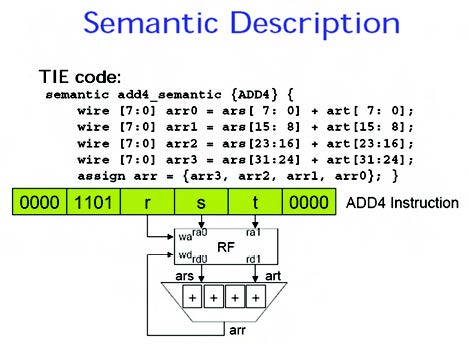
Figura 1. Rappresentazione dell’istruzione ADD4
Il FDO è un termine che è generalmente utilizzato per descrivere qualsiasi tecnica dove il flusso di esecuzione di un programma si basa su considerazioni di tipo comportamentale, cioè osserva il flusso del programma presente e passato. Chiaramente, in base alla tecnologia in uso, hardware e software, dove vengono applicate criteri di ottimizzazioni statiche e dove il processo di esecuzione è pressoché immutabile il criterio adottato non è più sufficiente per supportare una tecnica di questo tipo. Occorre aumentare la comprensione del programma in esecuzione e prevedere i vari comportamenti dell’applicazione in esecuzione per sfruttarli nell’ottimizzazione. Il criterio adottato da XCC è basato su due fasi: il codice è instrumentato durante il primo passaggio del compilatore, in questo modo diventa possibile prevedere i vari passi successivi in esecuzione, questo processo prevede la generazione di file contenente informazioni di profile e branch dell’applicazione. Nella seconda fase, si prende questo file generato, utilizzando le informazioni in esso contenute, per ottimizzare l’applicazione riducendo, per esempio, le operazioni di stack, utilizzando function inlining. Inoltre, XCC può anche utilizzare la tecnica FDO mediante l’uso di un supporto hardware: in questo modo il codice instrumentato viene eseguito su una piattaforma target che contiene, in FPGA, una implementazione Xtensa. Le informazioni di profiling sono utilizzate allo stesso modo del metodo precedente. Un’applicazione del genere può essere utile quando vogliamo eseguire l’applicazione in un ambiente reale con tutte le periferiche e memorie. L’analisi interprocedurale è un altro metodo. L’analisi dei data-flow (flussi di dati) sostiene l’ottimizzazione in una maniera molto più spazio-efficiente che utilizzando l’inlining analizzando solamente una sola copia di ogni procedura. Per catturare una precisa informazione interprocedurale si richiede un approccio di tipo flow-sensitive, in questo modo il programma viene analizzato per ricavare informazioni su ogni possibile control-flow. Un approccio del genere è abbastanza difficile perché le informazioni sia del calling context e sia l’effetto secondario di una invocazione confluiscono in una procedura unica. L’analisi interprocedurale (IPA) obbliga il compilatore di ottimizzare differenti file (l’intero programma sotto analisi) e, se fatto bene, si ottiene di solito un grosso potenziamento delle prestazioni. Alcuni compilatori permettono di definire in che modo svolgere l’analisi: sul compilatore o anche sul linker, su una porzione del programma o sull’intera applicazione. L’ultima tecnica di ottimizzazione che consideriamo è Global optimization. Questa attività deve essere mirata a trovare il migliore insieme di parametri per ottimizzare le relazioni che intercorrono tra le chiamate di funzioni. Infine, XCC è pienamente aware con le istruzioni generate da Tensilica’s Instruction Extension (TIE) compiler, infatti automaticamente aggiorna XCC con le istruzioni TIE.
OPZIONI ASSEMBLER PER TENSILICA
Le seguenti opzioni sono disponibili quando l’assemblatore (GAS) è configurato per un processore Xtensa.
—text-section-literals | —no-text-section-literals Con —text-section-literals, i pool literal sono sparpagliati nella sezione testo. Il default è —no-text-section-literals, che mette i literal in una sezione separata nel file di output. Queste opzioni influenzano solo i literal referenziati attraverso istruzioni relative PC “L32R”; i literals per le istruzioni in modo assoluto “L32R” sono gestiti separatamente.
—absolute-literals | —no-absolute-literals
Indica all’assembler se le istruzioni “L32R” usano indirizzamenti PC assoluti o relativi. Il default è di prendere l’ indirizzamento assoluto se il processore Xtensa include l’opzione “L32R” di indirizzamento assoluto. Altrimenti può essere usato solo il modo PC relativo “L32R”.
—target-align | —no-target-align
Abilita o disabilita automaticamente l'allineamento per ridurre le penalizzazioni dei salti al costo di un pò più codice. Il default è —target-align.
—longcalls | —no-longcalls
Abilita o disabilita la trasformazione delle istruzioni di chiamata per permettere chiamate attraverso un maggior spettro di indirizzi. Il default è —no-longcalls.
—transform | —no-transform
Abilita o disabilita tutte le trasformazioni assembler delle sitruzioni Xtensa. Il default è
—transform; —no-transform deve essere usato solo nei rari casi in cui le istruzioni devono essere esattamente come specificato nel sorgente assembly.
OPZIONI GCC PER TENSILICA
Le seguenti opzioni sono disponibili quando il compilatore c (GCC) è configurato per un processore Xtensa.
-mconst16
-mno-const16
Abilita o disabilita l’uso della istruzione CONST16 per caricare valori costanti. L’istruzione CONST16 non correntemente una opzione standard per Tensilica, quando è abilitata, l’istruzione è sempre utilizzata in luogo dell’istruzione standard L32R. L’uso dell’istruzione è abilitata per default solo se l’istruzione L32R non è disponibile.
-mfused-madd
-mno-fused-madd
Abilita o meno l’uso dell’istruzione cosiddetta fused multiply/add e multiply/subtract nelle opzioni di floating-point.
Questa opzione non ha effetto se l’opzione di floating-point non è abilitata. Viceversa, se disabilitiamo l’istruzione si forza il compilatore di utilizzare istruzioni separate per queste operazioni.
Può anche succedere che, per determinati casi, dove l’uso del formato IEEE754 è strettamente richiesto, l’istruzione non arrotonda il risultato intermedio, ma produce un risultato che contiene più bit di precisione specificati dallo standard IEEE754.
-mtext-section-literals
-mno-text-section-literals
Controlla il trattamento dei literal pools. L’opzione di default è -mno-text-sectionliteral, e pone i literal in una sezione separata del file di output. Questo permette literal pools di mettere i dati RAM/ROM, e permette anche al linker di combinare literal pools in separati file oggetto per rimuovere literal ridondanti e migliorare la quantità del codice prodotto. Con -mtext-section-literals, i literal sono inframmezzati nella sezione di testo per tenerli più vicini alle loro referenze. Questo può essere necessario per grandi file assembly.
-mtarget-align
-mno-target-align
Quando questa opzione è selezionata, GCC istruisce l’assemblatore ad allineare automaticamente le istruzioni. Per default l’opzione è -mtarget-align. Questa opzione non impattano il trattamento di istruzioni autoallineate quali Loop, infatti in questo caso l’assemblatore allineerà sempre l’istruzione, o allargando la densità delle istruzioni o inserendo istruzioni no-op.
-mlongcalls
-mno-longcalls
Quando viene specificata questa opzione, il compilatore istruisce l’assemblatore a tradurre chiamate dirette a indirette, a meno di particolari condizioni . Questa traduzione accade tipicamente per chiamate a funzioni, specificamente, l’assemblatore traduce un’istruzione di chiamata diretta in un L32R seguito da un’istruzione di CALLX. L’opzione di default è -mno-longcalls. Questa opzione dovrebbe essere usata in programmi dove può succedere che, potenzialmente, risulta essere fuori scope l’indirizzo del target. Questa opzione è implementata nell’assemblatore, in questo modo il codice generato da GCC evidenzierà ancora istruzioni di chiamate dirette. Nota che l’assemblatore userà una chiamata indiretta per ogni chiamata di cross-file, non solo quelli che realmente saranno fuori range.
UN BUON CODICE C
In linea di massima non è possibile sapere in che modo un compilatore ha generato il codice partendo dal programma sorgente. Per questo motivo può essere necessario esaminare il codice prodotto per intervenire, se possibile, sul processo di traduzione. Può essere utile avere un listing in assembler del codice prodotto, per fare questo è sufficiente utilizzare lo switch –S durante la compilazione. È una operazione abbastanza delicata: questa analisi statica del codice può dare elementi utili per scoprire se, e in che modo, il compilatore ha generato un codice che è possibile definire critical code. In caso negativo occorre intervenire nel codice sorgente per cambiare l’algoritmo utilizzato fino a ottenere quello che maggiormente soddisfa le aspettative. Per questo motivo risulta utile già intervenire in fase di codifica del programma per ridurre o evitare errori che possono appesantire l’applicazione introducendo overhead di sistema. In conclusione prima di incominciare ad ottimizzare è necessario controllare la propria applicazione per vedere se sono possibili i seguenti miglioramenti:
- Scegliere algoritmi con impatti, in termini di spazio, minimi;
- Evitare di utilizzare duplici copie di dati;
- Utilizzare strutture di dati che siano in grado di minimizzare il cosiddetto padding tra variabili/oggetti.
Vediamo alcuni accorgimenti/suggerimenti che possono essere considerati per migliorare la codifica della propria applicazione:
- Non utilizzare chiamate indirette
- Queste sono le chiamate che utilizzano i puntatori a funzioni e anche quelle chiamate passate come parametri in funzioni. Queste possono causare effetti secondari, per esempio possono modificare variabili globali che possono arrecare impatti sull’algoritmo di ottimizzazione;
• È preferibile passare un valore ad una funzione mediante argomento piuttosto che ricevere il valore da una variabile globale;
- È meglio chiamare direttamente una funzione che utilizzare puntatori a funzioni;
- Evitare di spezzettare il programma in tanti piccole funzioni. Se per esigenze di programma è necessario utilizzare piccole funzioni, allora diventa importante inscatolare automaticamente inline tali funzioni ed utilizzare altre tecniche per ottimizzare chiamate tra funzioni;
- Selettivamente utilizzare la modalità inlining delle funzioni, utilizzando per esempio la key-word inline. Infatti, una funzione di questo tipo richiede un minore overhead ed è generalmente più veloce. I candidati ideali per questa tecnica sono sicuramente le funzioni piccole che sono chiamate con maggiore frequenza;
- Non utilizzare funzioni che hanno argomenti variabili, se è necessario farlo allora è meglio utilizzare le prerogative dell’ANSI standard stdarg.h. Utilizza tabella in luogo di if-then-else o istruzioni switch;
- Utilizza variabili locali, preferibilmente automatiche, infatti il compilatore si costruisce delle assunzioni sempre worst-case quando tratta delle variabili globali
int len = 10;voidzero(char *p){int local_len = len;int i; for (i=0; i< local_len; i++) *p++ = 0;} - Utilizza variabili locali per mascherare le globali. Le variabili globali, per definizione, portano a spasso i valori in tutto il programma. Il compilatore non sa il motivo dell’uso di una variabile globale, è necessario forzare l’uso sempre di una variabile locale. Infatti, il compilatore deve utilizzare le variabili globali nelle chiamate e per dereferenziare un puntatore. In questo modo:int g;void foo(){int i;for (i=0; i<100; i++;i fred(i,g);}
- La variabile globale g è caricata fuori dal ciclo ed è poi passato alla funzione in foo(). Ma se fred() modifica g? Il compilatore non può saperlo, allora per evitare ambiguità è necessario creare una variabile locale di lavoro, cosi:
int g;void foo(){int i, local_g=g;for (i=0; i<100; i++) {fred(i,local_g);}} - Se si ha l’esigenza di utilizzare variabili globali allora si devono utilizzare definizioni di tipo static;
- Particolare cura deve essere posta nella definizione dei dati e nella relazione con i loro tipi. Un dato di tipo unsigned char utilizza 8 bits, in questo modo il valore oscilla da 0 a 255. In un programma C si può presumere che se sommiamo 1 a 255 viene generato un 0. Ma in una architettura a 32 bits l’addizione viene rappresentata non su 8 ma su 32 bits: in questo caso il comportamento potrebbe anche non essere quello atteso;
- Alcuni computer hanno una rappresentazione dei dati su 16 bit, in questo modo risultano essere carenti di istruzioni di moltiplicazioni a 32 bit. Le moltiplicazioni su 32 bits sono emulate con danni alle prestazioni del sistema;
- Utilizzare rappresentazioni del tipo register-sized integers per i scalari. Per array di interi di grosse dimensioni, utilizzare uno o due byte o bit fields;
- Utilizzare una rappresentazione in virgola mobile non trascurando l’hardware in uso. Utilizzare rappresentazioni del tipo long double quando è veramente richiesta una precisione del genere;
- Se occorrono utilizzare delle variabili esterne allora è meglio raggruppare le variabili in una struttura o array: tutti gli elementi della struttura sono accessibili, così, sullo stesso base address;
- Utilizzare costanti in luogo delle variabili. In questo modo il lavoro di ottimizzazione è svolto a compile-time. Per esempio, se il corpo di un ciclo ha un numero costante di iterazioni, allora è meglio utilizzare nella condizione del ciclo per meglio ottimizzare.
for (i=0; i<4; i++)Può essere meglio ottimizzato di:for (i=0; i<x; i++)). - Se un componente di una espressione è utilizzata in un’altra espressione, può essere utile assegnare i valori cosi duplicati ad una variabile locale. In questo modo si evita che il compilatore si occupi della conversione tra numeri interi e a virgola mobile;
- Evitare di costringere il compilatore a convertire numeri tra rappresentazioni diverse, per esempio tra un intero e un floanting-point. Quando è necessario utilizzare delle conversioni del genere, allora è opportuno calcolare/codificare separatamente;
- Evitare l’uso di goto che saltano nel mezzo di un ciclo, perché queste istruzioni possono interdire le ottimizzazioni;
- Migliorare la predicibilità del codice facendo in modo di utilizzare percorsi più probabili, per esempio questo codice:
if (error) {handle error} else {real code}dovrebbe essere scritto come:if (!error) {real code} else {error} - Con C++, utilizzare il blocco try per la gestione delle eccezioni solo quando realmente serve perché incide in maniera negativa sul processo di ottimizzazione.
CONCLUSIONE
L’ottimizzazione del codice, si è visto, non è un’attività relegata al compilatore: certamente questo da un apporto decisivo, ma occorre anche predisporre l’ambiente. È necessario predisporre il programma in modo che il processo di ottimizzazione ne ricava il massimo beneficio.



Articolo molto interessante. Non conoscevo la tecnologia Xtensa. Esistono quindi delle Evaluation Board con processori Xtensa? Il sistema di sviluppo e’ gratuito? Grazie per la gentilezza.