
L’utilizzo del meccanismo di pipeline permette al microprocessore di incrementare la sua velocità d’elaborazione. Questo incremento prestazionale fornisce quelle chiavi di lettura per convincere il progettista per l’uso di architetture del genere per le proprie realizzazioni.
Negli ultimi anni l’evoluzione della tecnologia dei processori ha portato a definire sempre nuove soluzioni architetturali: da soluzioni basate su CISC a quelle RISC per approdare a quelle di tipo VLIW. La tecnologia che avuto il maggior seguito è certamente quella RISC: la chiave vincente è basata su due proposte tecnologiche convincenti:
➤ un formato di istruzione fisso, non eccessivamente esteso, e di tipo load-store;
➤ un’esecuzione standard di tutte le istruzioni, preferibilmente in unico ciclo macchina, che si coniuga con la tecnica della pipeline.
In questo articolo verrà data particolare enfasi alla tecnica della pipeline e con un riferimento pratico con la soluzione SHARC. Quando parliamo di soluzioni del genere certamente quello che si evidenzia è il risultato prestazionale che, grazie alla pipeline, si raggiunge.
Analisi delle prestazioni
La definizione delle performance è definita come il prodotto di tre fattori. Se, infatti, definiamo con TT il tempo speso da ogni task (qui per task si vuole riferire ad ‘un insieme di operazioni per raggiungere un obiettivo, come per esempio un’attività computazionale), allora questo tempo è dato da:
TT = C * T * I
Con C si definisce l’insieme dei cicli di clock per istruzione, T è il tempo speso per ciclo (il clock speed) e con I le istruzioni per ciascun task. Questo tempo è dipendente, come si può dedurre, dal tipo di architettura che utilizziamo: RISC piuttosto che CISC. La pipeline è la chiave che ci permette di ridurre il fattore C, poiché l’esecuzione avviene per overlapping (figura 1).
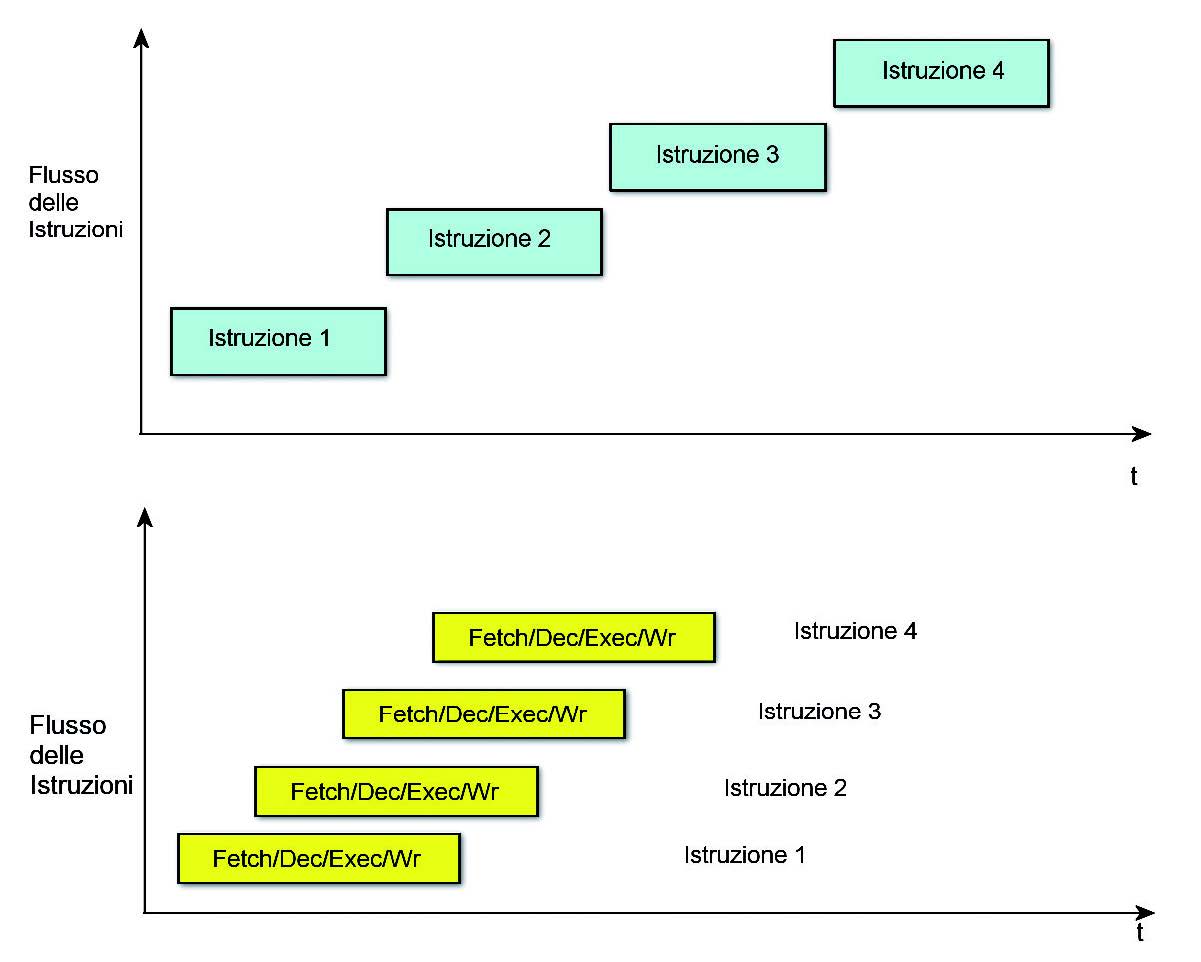
Figura 1: comparazione tra due CPU - una con 4 livelli di pipeline e lÆ altro senza pipeline.
L’esecuzione delle istruzioni può essere suddivisa in una serie di porzioni (fetch, decode, execute, write). Una istruzione, in questo modo, sottoposta a pipeline, può ridurre il numero dei cicli per istruzioni mediante l’overlapping, in esecuzione, di multipli istruzioni. Il concetto di pipeline in una CPU richiama il concetto di suddivisione del lavoro, infatti la pipeline è la sudddivisone del nostro lavoro in una serie di micro-stadi ognuno dei quali identifica una parte delle istruzioni. Questi micro-stadi eseguono, in maniera concorrente, differenti parti di diverse istruzioni. Questi micro-stadi sono chiamati pipe stage o stadio della pipe. Gli stage sono connessi in cascata per formare una pipe: l’istruzione entra da un’estremità, prosegue attraverso i diversi passi della pipe ed infine esce dall’altra estremità. Poiché gli stadi sono sequenziali, ognuno deve produrre un risultato, entro un certo tempo, affinché l’istruzione possa procedere correttamente nella pipe. Questo tempo in cui un’istruzione muove da uno stage all’altro è il tempo di un ciclo di cadenza detto anche ciclo di clock, determinato dallo stage più lento. Compito fondamentale dei progettisti è il bilanciamento ottimale della pipe, ovvero cercare di realizzare stadi i quali producano un risultato, sostanzialmente, nello stesso tempo, minimizzando gli istanti di inattività (idle time) in ciascuno stage. In una macchina perfettamente bilanciata il tempo in cui ogni istruzione viene eseguita nella pipe è dato tra il rapporto tra il tempo di esecuzione dell’istruzione con il numero dei stadi della pipe. Analizziamo la struttura del pipeline di un’istruzione macchina partendo da un semplice esempio con quattro stadi:
➤ fetch (caricamento). L’istruzione è caricata nella CPU;
➤ dec (decodifica). L’istruzione è decodificata e gli operandi vengono eventualmente prelevati dal register file.
➤ exec (esecuzione). L’istruzione è eseguita.
➤ Wr (memorizzazione). I risultati dell’esecuzione vengono memorizzati.
Un diagramma temporale della pipe, sopra descritta, si evince dalla lettura della figura 1. Il diagramma mostra i quattro stadi di esecuzione di quattro istruzioni successive. La figura assume che ogni operazione è completata in un singolo ciclo di cadenza (ciclo di clock). Questo, in realtà, non accade sempre. Infatti, se si può supporre che la fase di decodifica impiega un ciclo, sicuramente per le altre fasi questo numero è maggiore di uno. Un’istruzione composta di più parole in una macchina con ampiezza del bus dei dati limitata ad una parola, può occupare infatti nel caricamento (stadio di fetch) più di un ciclo. Solo nei sistemi dove tutte le istruzioni non sono più lunghe della larghezza del bus dei dati, è possibile prevedere di caricare un’istruzione per ciclo. Lo stadio di esecuzione è particolarmente critico. Difficilmente moltiplicazioni, divisioni e operazioni in virgola mobile potranno essere terminate in un unico periodo del segnale di clock. Il completamento della fase di write invece dipende dalla destinazione di memorizzazione. Se questa destinazione è un registro del processore potrebbe essere sufficiente un unico ciclo di clock; se invece è esterna al chip questi potrebbe non bastare. Si vedrà successivamente come solo per i processori di tipo RISC si può raggiungere l’esecuzione di un’istruzione per ogni ciclo di clock. Ci sono altri potenziali problemi che possono pregiudicare il regolare funzionamento della pipeline. Se, per esempio, l’istruzione corrente dipende dal risultato della precedente, si ha un problema di elaborazione. Inoltre un’istruzione di salto interrompe la sequenza della pipe poiché comporta la scelta di un altro flusso di istruzioni. Tutte questi eventi pregiudicano l’esecuzione lineare del pipeline e sono detti pipeline hazard. Questo è senza dubbio l’aspetto più importante dell’architettura RISC.
La pipeline nei micro SHARC
Il processore SHARC, attraverso il suo sequencer, determina la prossima istruzione da eseguire. Questo è fatto esaminando l’istruzione corrente che deve essere eseguita e lo stato corrente del processore. L’unica condizione che può alterare il normale flusso del programma sono le istruzioni condizionali, in questo caso se nessuna istruzione di questo tipo è presente, allora il processore esegue le istruzioni dalla Program Memory in ordine sequenziale incrementando, ad ogni istruzione, l’indirizzo di fetch. Le istruzioni dello SHARC, utilizzando la sua architettura pipeline, sono eseguite in tre cicli di clock (come per il microprocessore ARM). Gli stadi della pipeline del processore SHARC:
➤ Fetch cycle. In questo fase il processore legge l’istruzione direttamente nella memoria del programma o dalla cache
➤ Decode cycle. Il processore SHARC decodifica l’istruzione e genera le condizioni che controllano il flusso delle esecuzioni.
➤ Execute cycle. Il processore esegue l’istruzione.
Le operazioni non sequenziali di un programma includono i seguenti aspetti:
➤ Jumps
➤ Subroutine calls and returns
➤ Interrupts and return
➤ Loops
Tecniche di compressione
Con l’architettura SHARC e con tecniche di compressione è possibile aumentare le prestazioni di questi microprocessori. Ma com’è possibile utilizzare la compressione in queste tecnologie? Introduciamo in questo paragrafo una tecnica di compressione che può essere applicata al processore SHARC. Ci riserviamo, magari in un prossimo futuro, di approfondire questa tematica in quanto può rendere le nostre applicazioni più flessibili e aumentare le prestazioni. Lo schema di compressione che esamineremo approfitta dell’osservazione che le istruzioni nei programmi sono estremamente ripetitive. In questo modo, ogni opcode di una istruzione non ripetitiva è messa in una, così chiamata, instruction table. Ogni istruzione nel programma è, di conseguenza, rimpiazzata con un indice in questa tabella. Siccome le parole delle istruzioni sono sostituite con un codice più corto e poiché la dimensione della tabella è più piccola rispetto alla dimensione di un programma, allora la versione compressa risulta più piccola dell’originale. In questo modo, le istruzioni che compaiono una volta sola nel programma rappresentano la parte più problematica, poiché inficia il nostro lavoro di compressione. La pipeline del processore SHARC è mostrata in figura 2.
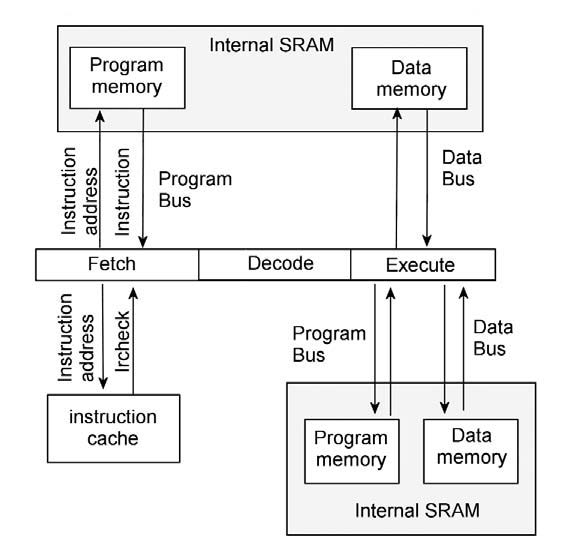
Figura 2: sharc pipeline.
Il processore utilizza il Program Memory Bus per fetchare le istruzioni e usa il data memory bus per fetchare i i dati. Tuttavia, il processore può anche utilizzare questi bus per accessi duali. Quando è utilizzato in questa modalità, le istruzioni sono eseguite dalla instruction cache così il Program Memory bus può essere utilizzato per fetchare i dati. La possibilità di utilizzare il processore SHARC per programmi compressi è mostrata in figura 3: come si vede ai 3 stage della pipeline dello SHARC è aggiunta uno stadio di pre-fetch.
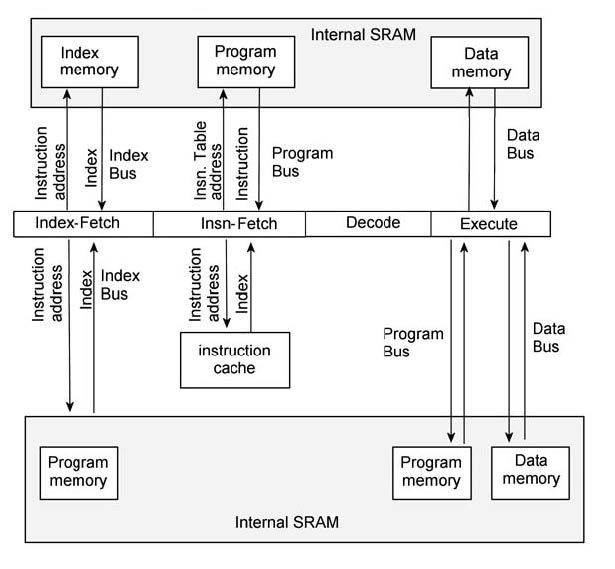
Figura 3: compressed program pipeline
Lo stadio di pre-fetch prende i 16-bit instruction indirizzati dalla memoria esterna. Lo stadio di pre-fetch recupera l’indice dei 16-bit instruction dalla memoria esterna. Il registro instruction table address contiene l’ubicazione della tavola di istruzione nella memoria interna. Lo stadio di fetch utilizza questo indirizzo per trovare i 48-bit dell’instruction word. Infine, l’istruzione così ottenuta è passata alla fase di decodifica (decode stage). Occorre tenere presente che ci sono dei costi per aggiungere degli stadi di pre-fetch.
➤ Un bus di memoria interno, la index memory, deve essere aggiunto per sostenere un accesso simultaneo alla memoria. Il processore SHARC utilizza una SRAM dual port per realizzare accessi simultanei sul program e data bus. Invece di aggiungere un’altra porta verso la SRAM per indicizzare i bus, un blocco SRAM potrebbe essere allocato per indicizzare la memoria.
➤ Lo stadio di pre-fetch aggiunge un terzo branch delay slot
➤ Un ulteriore registro deve essere aggiunto nell’architettura per gestire correttamente questa instruction table.
Quando accessi in data e program competono sull’uso del program bus, il processore SHARC pone l’istruzione in conflitto nella instruction cache. In questo modo, qualsiasi futuro riferimento allo stesso indirizzo può utilizzare la I-cache e allocare il program bus per essere utilizzato come data. Questa caratteristica permette l’uso di loop con istruzioni che utilizzano il program bus per accessi su dati senza conseguenze sul contenzioso della risorsa di bus. Questa caratteristica è estremamente importante per algoritmi con DSP che tipicamente sono contraddistinti da computazione intensivi con l’uso molto diffuso di ricorsione e strutture iterative. Chiaramente, in una architettura che vuole sfruttare la compressione è utile tenere conto di questa prerogativa tale da considerarlo parte dell’implementazione. Utilizzando una indicizzazione a 16-bit ci consente di utilizzare senza problemi 64K di istruzioni uniche
Tipica sessione di debug con SHARC
Per condurre una sessione di test con questo microprocessore non è necessario conoscere particolari meccanismi poiché una sessione di questo genere non si scosta rispetto ad una tradizionale. Disporre di una architettura di tipo pipeline non comporta nessuna differenza, a meno di qualche particolare accorgimento, per esempio con il comando di breakpoint, in questo caso è azzerata la pipeline del microprocessore. Supponiamo ora di utilizzare il listato 1, check.asm, per mostrae una sessione di debug utilizzando un processore con una pipeline.
/*a small interrupt table: */ .segment/pm int; nop; nop; nop; nop; nop; jump start; nop; nop; /*a segment containing code*/ .segment/pm text; start: r0 = 0x100; r1 = 5; r2 = r0*r1(ssi); f0 = 200.0; f1 = 7.0; f2 = f0*f1; jump start;
| Listato 1 - check.asm |
Dopo aver assemblato il programa mediante il comando:
brasm -g -o check.obj check.asm
Utilizziamo il file, check.arch, per la definizione delle direttive di clinker: occorre, infatti, piazzare i vari segmenti nelle relative zone di memoria:
/*place all text segments starting at 0x20080*/ place *.text at memory: 0x20080..0x23fff, ram, pm, bits=48; /*place the interrupt table at 0x20000*/ place *.int at memory: 0x20000..0x2007f, ram, pm, bits=48;
Per fare questa operazione è necessario utilizzare il commando:
brlink -g -o check -a check.arch check.obj
Dopo aver acceso il target scarichiamo il nostro esempio, attraverso l’interfaccia JTAG, nella sua memoria:
brdbg check
Notiamo che il debugger visualizza le informazioni di loading e mostrerà il suo prompt:
load_sharc loading to 0x20000, 8 words, width=48 load_sharc loading to 0x20080, 7 words, width=48 softbreaks not enabled >
Il passo successivo è quello di inizializzare il program counter utilizzando il comando:
>pc=start
Dove start è a label di inizio del programma di test. Procediamo ad eseguire il programma in modalità step by step:
>s 20: r1 = 5; >s 21: r2 = r0*r1(ssi); >s 22: f0 = 200.0; >p r2 1280 >p \x r2 0x500
Con il commando “p r2 “ verrà visualizzto il contenuto del registro r2: il primo comando provvederà alla sua visualizzazione in formato decimale, mentre quel lo successivo in esadecimale (p \x r2). Il passo finale è quello di mettere un breakpoint. Per prima cosa vediamo che cosa c’è in memoria, con list:
>p list( start ..+ 6) 0x20080 r0 = 0x100; 0x20081 r1 = 0x5; 0x20082 r2=r0*r1 (ssi); 0x20083 r0 = 0x43480000; 0x20084 r1 = 0x40e00000; 0x20085 f2=f0*f1; 0x20086 jump 0x20080;
È opportuno tenere presente che list è una funzione che prende in ingresso uno o più parametri (indirizzi di memoria), e nel nostro caso passiamo a list l’indirizzo di partenza start e quello finale +6 (rispetto a start). L’effetto che si ottiene con list è quello di avere l’indirizzo assoluto del primo parametro con il disassemblato del contenuto della memoria. Per mettere un breakpoint, un hardware breakpoint, dobbiamo ricorrere al seguente commando:
>b 0x20086
Il breakpoint è messo all’indirizzo 0x20086 con opcode jump 0x20080. Per riprendere l’esecuzione dal punto del PC utilizziamo il comando continue:
>c sharc halted on inst break (id=1) 19: start: r0 = 0x100; >
Poiché l’architettura SHARC è del tipo a pipeline, il microprocessore spende qualche ciclo di clock per azzerare la sua pipeline ad ogni occorrenza di un breakpoint hardware.
Conclusione
Si conclude a questo punto la nostra panoramica della pipeline del microprocessore SHARC. Un argomento che non può trovare una conclusione in un articolo, infatti esistono altri aspetti che meritano di essere trattati. Da quello che abbiamo scritto, certamente si possono trovare altri spunti, per esempio, l’architettura SHARC ha delle similarità con quella dell’ARM, il modello ARM7 TDMI.


