
La tecnologia del multicore è attualmente la risposta alla sempre crescente richiesta di alte prestazioni e velocità di calcolo. In questo articolo spieghiamo i motivi di questa attuale tendenza per le architetture delle CPU di nuova generazione e le scelte progettuali adottate dalle industrie elettroniche.
La spinta evoluzionistica alla base di ogni tecnologia futura e attualmente consolidata e impiegata, non si potrebbe attuare senza l’ausilio di macchine in grado di eseguire calcoli (più o meno complessi), in numero sempre crescente ed in tempi sempre più ridotti. Da qui l’esigenza di cercare soluzioni innovative per potenziarne in primo luogo i processori, puntando sulle prestazioni elettriche e/o sulla architettura, come nel caso del multicore.
Cos’è il multicore
E’ un architettura basata sull’impiego di due o più core (nuclei) incapsulati su di un unico package, ognuno dei quali è chiamato ad elaborare, in contemporanea, una parte del carico computazionale. La nuova strategia di calcolo quindi, mira a ripartire il carico di lavoro del processore a due o più nuclei di elaborazione, al fine di: aumentare la velocità di esecuzione delle singole applicazioni e supportare in modo più efficiente e con maggior potenza il multitasking. Queste due motivazioni riguardano un punto di vista prettamente “applicativo” ma, indubbiamente, l’adozione dell’architettura multicore ha dei risvolti significativi anche in termini fisici, fattori questi di grande importanza per le aziende produttrici di processori, e non solo. La prima soluzione affacciatasi nel segmento di mercato dei desktop è stato un dual-core del chipmaker californiano Intel (leader nel settore dei processori assieme alla concorrente AMD), il quale già nell’aprile del 2005 annunciava il Pentium Extreme Edition (EE) 840, funzionante ad una frequenza di clock pari a 3,20GHz e con frequenza FSB (Front Side Bus) pari ad 800MHz. Il nuovo processore, pur lavorando a frequenze inferiori a quelle del predecessore Pentium 4 Extreme Edition (clock da 3,76GHz ed FSB da 1.066MHz), assicurava prestazioni sicuramente superiori. In seguito venne presentato anche il Pentium D, integrante lo stesso core del Pentium EE 840, chiamato in codice Pentium Smithfield. Da quel momento sia Intel che AMD (così come anche molte altre aziende nell’ambito dei sistemi embedded), iniziarono a sviluppare tecnologie a supporto del multicore, per i diversi segmenti di mercato quali Server, Desktop, Laptop eccetera. L’idea della parallelizzazione di molteplici core può risultare a primo acchito semplice ma, come ogni nuova tecnologia elettronica (ed in modo particolare quella dei processori), ha richiesto innovazione nei processi produttivi elettronici e nella ricerca di nuove soluzioni a supporto del multicore. A questo proposito si sottolinea il fatto che anche se esternamente il processore si presenta come unico, un multicore al suo interno è paragonabile ad una moltitudine di processori in parallelo, i quali assieme devono cooperare in modo continuo, contemporaneo ed efficiente. Questi requisiti sono fondamentali affinché l’architettura multicore mostri appieno le proprie potenzialità, invece di risultare un sistema di elaborazione più pesante, rispetto alle architetture single-core. In altre parole, i diversi core devono poter essere gestiti in modo che l’elaborazione di uno non ostacoli quella degl’altri, dal momento che, esternamente, risorse fondamentali quali RAM e FSB (Front Side Bus) sono in comune. A titolo di cronaca va inoltre segnalato il fatto che, molto probabilmente, fù la spinta evolutiva dei DSP (Digital Signal Processor) ad orientare il mercato dei processori al multicore. C’è chi ritiene che quest’ultima sia la naturale evoluzione dei primi: questo perché i DSP (nelle loro elaborazioni dei segnali analogici con tecniche digitali), da sempre fanno uso di potenze di calcolo relativamente alte, così da poter svolgere algoritmi numerici molto complessi. Allora, per potenziarli, si pensò di integrare molteplici moduli DSP assieme ad un processore RISC (Reduced Instruction Set Computer) in modo da parallelizzare l’elaborazione. Questa filosofia avrebbe portato anche alla riduzione dei costi di progettazione, dal momento che sarebbe stato più con veniente realizzare più DSP (già disponibili) su di un unico die, piuttosto che riprogettare un DSP lavorante a frequenze superiori.

Figura 1: schema a blocchi del Pentium D.
Perché integrare più core?
Prima dell’avvento dell’architettura multicore si prevedeva un aumento continuo della frequenza di clock dei processori, cosa che solo in teoria avrebbe fatto raggiungere potenze di calcolo via via crescenti. Tuttavia l’aumento di frequenza, comporta problemi fortemente limitanti nel contesto di un mercato dell’elettronica che punta sempre più a riduzione di ingombri e costi, e a maggiore portabilità e potenza di calcolo. Maggiore frequenza implica una maggiore dissipazione di potenza per unità di superficie del chip, cosa che come minimo richiede meccanismi di dissipazione del calore sempre più efficaci ed ingombranti. Questi meccanismi si basano sull’uso di ventole che, inevitabilmente, richiamano al problema “rumorosità”, oppure sullo scambio di calore con liquidi, anche quest’ultima una soluzione che si scontra con le necessità di miniaturizzazione e portabilità del dispositivo. Và inoltre evidenziato il fatto che frequenze superiori ai 3GHz, nel contesto dello spettro elettromagnetico, corrispondono al campo SHF (Super High Frequency) e quindi a quello delle Microonde (o onde centimetriche –10cm<λ<1cm), particolare questo che comporta non pochi problemi. Uno di questi è l’esigenza di ridurre le dimensioni di transistor, connessioni eccetera, problema che, ammesso che sia sormontabile dalle attuali tecnologie di miniaturizzazione, comporta di certo un aumento della dissipazione di calore per unità di superficie. E’ il cane che si morde la coda e in questo modo si rischiava di vanificare gli sforzi. Ecco perché si è puntato all’alternativa del multicore e dei sistemi multiprocessore, dove il carico elaborativo viene ripartito su molteplici CPU lavoranti in parallelo
Il problema della produzione e della dissipazione della potenza termica è comunque una questione sempre aperta, anche nell’ambito del multicore. Sebbene questa architettura spalmi la potenza termica generata durante le elaborazioni su di un area maggiore, rimane comunque il fatto che più core possono produrre più calore. A questo proposito và tenuto presente che un sistema multicore da n nuclei, genera meno calore di un single core che lavora a frequenza n-volte superiore. Si considerino ad esempio due processori, uno da 3GHz e l’altro (dello stesso tipo) funzionante invece a frequenza doppia (6GHz). Indubbiamente quest’ultimo sarà più potente ma l’aver raddoppiato la frequenza comporterà un aumento di calore più che doppio! In teoria, il carico del single-core da 6GHz può benissimo essere svolto da un dual-core da 3GHz, col vantaggio però che il calore prodotto non supererà il doppio di quello generato dal single-core da 3GHz. Questo aspetto risulta abbastanza evidente esaminando le tabelle di confronto dei processori dei vari chipmaker attualmente in commercio. Per ottimizzare al meglio i consumi di energia e quindi ridurre la produzione di energia termica, vengono adottati diversi accorgimenti di controllo come il CoolCore, messo a punto dalla AMD e già presente in processori come il quad-Core Opteron. Questo controllo consente l’attivazione dei soli core e della sola memoria che effettivamente è necessaria all’elaborazione. Un altro modo per tener sotto controllo le temperature è la possibilità di gestione del livello di operatività dei singoli core. Questo aspetto l’AMD lo risolve con la tecnologia Independent Dynamic Core, che modula la frequenza di lavoro di ciascun nucleo in funzione del tipo di applicazione che il singolo core deve eseguire. Questo consente una più precisa gestione del consumo energetico e del TCO. Il Total Cost of Ownership (costo totale di possesso) rappresenta un metodo di calcolo di tutti i costi del ciclo di vita di un’apparecchiatura informatica IT (acquisto, installazione, manutenzione, smantellamento eccetera). Forse per un privato, che acquista ad esempio un portatile, questa informazione è del tutto irrilevante, ma è sicuramente importante per un’azienda che fa grande affidamento su apparecchiare elettroniche come server, sistemi di comunicazione per telefonia mobile, per esempio. Esistono inoltre sistemi di controllo, integrati in una struttura multicore, in grado di commutare un core con un altro, nel caso la sua temperatura dovesse superare una data soglia. Un altro fattore da segnalare che contribuisce in modo significativo alla generazione del calore, è quello del leakage (dispersione). Questo fenomeno parassita è insito nella tecnologia MOS adottata dalle fonderie di silicio. Il leakage è causato per lo più dalla dispersione di portatori di carica che si verifica per effetto tunneling tra la zona del gate ed il suo strato di ossido, e quella di sub-threshold che si diffonde tra il drain e il source di un transistor. In questo modo si generano delle vere e proprie correnti di dispersione che, in quanto tali, sono causa di ulteriore generazione di calore. Per attenuare il fenomeno si tende a ridurre le lunghezze dei MOS ed in particolare quelle dei gate.
Ecco allora che in questi ultimi anni le fonderie di silicio hanno messo appunto tecnologie di processo a 90nm, 65nm, 45nm e per ultimo, (da poco annunciata dalla Intel) quella a 32nm, prevista per quest’anno. Per dare un idea di queste dimensioni basti pensare che in tecnologia a 65nm, la lunghezza complessiva di cento gate allineati coprono appena il diametro di un globulo rosso. Queste riduzioni vanno a beneficio del livello di integrazione, fattore sicuramente importante quando si intendono realizzare più core su di un unico die, ma non solo: realizzare chip più piccoli aumenta la resa produttiva. Questo accade perché minore è la dimensione del die, minore è la sua probabilità che presenti difetti. Inoltre, và considerato che un multicore occupa un’area n-volte quella di un singlecore (n dunque è il numero di core integrati), e questo aumenta proporzionalmente la probabilità di trovarne difetti. Il fenomeno del leakage inoltre è tanto più forte quanto maggiore è la temperatura raggiunta dal transistor, e può essere ulteriormente attenuato con la tecnica SOI (Silicon On Insulator), che prevede l’uso di dielettrici per il gate diversi dal semplice ossido di Silicio (SiO2), e quindi con diversa costante dielettrica K. Altro accorgimento adottato al fine di limitare le correnti di dispersione è l’impiego del silicio “strained” (stirato), in grado di aumentare la velocità dei portatori di carica di circa il 70%. Questa venne introdotta per la prima volta dalla Intel con la tecnologia di processo a 90nm, e in seguito migliorata. Altri due punti critici legati all’aumento della frequenza di lavoro (oltre all’incremento della potenza dissipata per unità di area) sono: difficoltà a realizzare memorie che “tengano il passo”, nonché i ritardi causati dalle linee di connessione interne al core.
Multicore, threading e pipeline
Una delle prime soluzioni adottate per aumentare il numero di istruzioni elaborate nell’ unità di tempo (throughput) fù quella della pipeline dei dati, introdotta per la prima volta nel 1966 dalla IBM. Questa è una tecnica di parallelizzazione delle operazioni molto efficace, che consiste nella frammentazione dell’elaborazione di una data istruzione in più stadi consecutivi. A titolo di esempio consideriamo soli 4 stadi (in realtà i processori attuali ne contano molti di più): IF, ID, EX e WB (rispettivamente lettura istruzione dalla memoria, decodifica dell’istruzione e lettura operandi, esecuzione dell’istruzione e scrittura del risultato sui registri). Come in una catena di montaggio, i diversi livelli si passano in cascata il risultato della propria elaborazione, cosicché l’ultimo restituirà il prodotto finito (nel nostro caso il risultato dell’elaborazione). Supponendo un numero di livelli pari al numero di stadi intermedi, ne consegue che ad ogni ciclo di clock una istruzione ha inizio ed una precedente avrà fine. Se si dovesse invece serializzare tutto il processo, l’esecuzione dell’istruzione richiederebbe. nel nostro esempio, un tempo 4 volte superiore (4 cicli di clock). Questo meccanismo non è di certo perfetto, soprattutto nei casi di salti condizionati, dove le istruzioni precedentemente iniziate vengono ovviamente terminate (con un inevitabile perdita di tempo per lo svuotamento dei diversi livelli), oppure nei casi in cui l’elaborazione di una istruzione dipende dal risultato di quella/e precedenti. A questo proposito le tecniche che possono ovviare a questi due problemi sono diversi, come ad esempio l’integrazione di molteplici pipeline in un unico processore. In questo caso si suole parlare di scalarità dei processori. Anche i microcontrollori PIC implementano una semplice pipeline basata su due soli stadi di elaborazione: fetch ed execute (vedere figura 2).
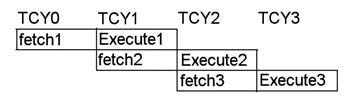
Figura 2: pipeline di un pic.
Il multi-threading technologies invece, consiste nella parallelizzazione delle operazioni che compongono un processo. In altre parole il processore elabora molteplici flussi di istruzioni occupandosi ora dell’uno e in seguito degl’altri. In figura 3 viene proposta una rappresentazione dei molteplici canali (i threads) per alcuni processori multicore.
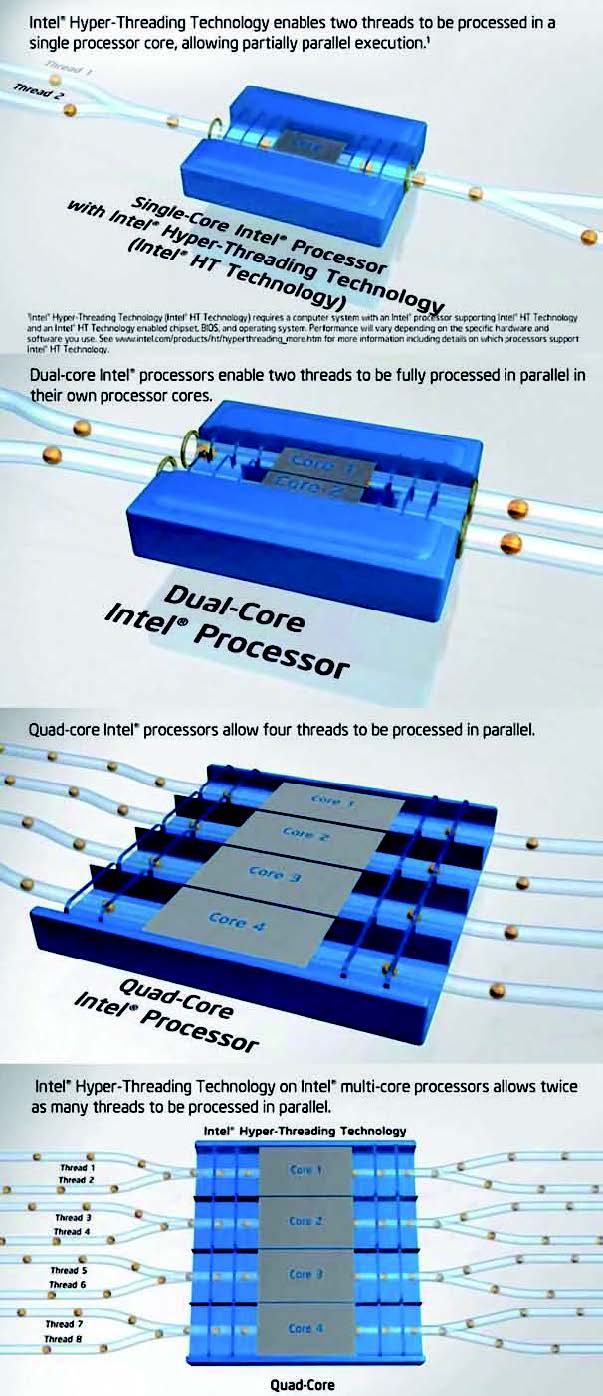
Figura 3: il multi-threading (Fonte: www.intel.com).
La strategia, che evoca l’idea della multiplazione, consente così l’elaborazione di più applicazioni alla volta, o un applicazione più velocemente se i suoi sottoprocessi vengono ripartiti nei vari threads. Se il sistema di elaborazione nel suo complesso è sufficientemente veloce, l’utente che sta al computer potrà spostare il puntatore del mouse o digitare un carattere dalla tastiera mentre è in esecuzione una grossa applicazione, quale può essere un acquisizione video o un altra elaborazione che richiede molte risorse. Se a questa tecnica si aggiunge la struttura multicore, allora un processore può raggiungere livelli di potenza computazionale davvero elevati, potendo così gestire molti threads (o canali) contemporaneamente. Negl’ultimi anni si è puntato molto sulla integrazione del multicore e del threading. Si pensi ad un quad-core come l’ultimo processore Intel Core™ i7 Extreme Edition da 3,20GHz, in grado di gestire ben 8 thread di elaborazione (2 per ogni core). Se si parla di prodotti tipo laptop e desktop, 8 canali sono davvero un buon numero, ma volgendo l’attenzione a sistemi più complessi come ai Webserver con numerosi accessi, il numero di thread sarà dell’ordine delle decine. Il processore UltraSPARC T1 (nome in codice Niagara) della Sun Microsystems, a titolo di esempio, è un multicore da 4/6/8 nuclei ognuno dei quali è in grado di gestire fino a 4 thread contemporaneamente. In totale, allora, può al massimo gestire ben 32 canali, e il tutto per soli 72W di consumo (79W di picco). Realizzato in tecnologia a 90nm e funzionante a soli 1 o 1,2GHz, bene si presta a supportare la virtualizzazione e la crittografia.

Figura 4: la tecnologia Independent Dynamic Core di AMD che modula la frequenza di lavoro di ciascun nucleo in funzione del tipo di applicazione che il singolo core deve eseguire (Fonte: www.amd.com).
Singolo die oppure doppio?
Inizialmente si pensò di realizzare due core identici l’uno di fianco all’altro, impiegando le mascherature dei processori precedentemente sviluppati, su di un uncio die (o chip). La semplicità realizzativa però si scontra in primo luogo con la perdita di efficienza elaborativa, dal momento che i due core, per comunicare tra loro, devono occupare il bus esterno (esattamente come se fossero due processori indipendenti), e in secondo luogo con la diminuzione di produttività a parità di wafer realizzati. Infatti, dal momento che risulta impossibile ottenere chip perfettamente identici su di un unico wafer (ancor di più se si stratta di strutture a semiconduttore estremamente complesse come i processori), se i due core accoppiati non risultano sufficientemente simili in termini di prestazioni (in frequenza ed elettriche), la probabilità di incontrare una coppia non idonea per un processore dual-core risulta essere maggiore che nel caso del singolo core. Comunque sia, in questo caso, il produttore potrà vendere il “mancato” dual-core come processore classico a singolo nucleo, pur perdendo metà del chip realizzato. Si fa osservare che questa soluzione prevede doppie memorie cache, ciascuna integrata in ogni core, cosa questa che inficia inevitabilmente sull’efficienza elaborativa. Un alter nativa è quella del doppio die, ovvero impacchettare due core realizzati su singolo chip (Consolidated Highly Integrated Processor) e connetterli tra loro grazie a connessioni interne al package. Questa soluzione ha un vantaggio non indifferente sulla produzione: è possibile infatti “scegliere” due processori con prestazioni molto simili (quindi compatibili sia in frequenza che in tensione), e accoppiarli in un dual-core. Anche in questo caso però l’efficienza non è ottimizzata a causa della separazione fisica (e quindi strutturale). Le maggiori prestazioni, come si può a questo punto facilmente intuire, si ottengono realizzando un multicore monolitico. Questa soluzione prevede la riprogettazione dell’intero chip, dal momento che qui i core sono connessi tra loro da un apposito bus interno (e non dal bus di sistema) e condividono la cache, o parte di essa. Questo accorgimento non è l’unico, dal momento che altri moduli in tegrati dovranno essere modificati a supporto dell’architettura multicore, come la cache nei suoi diversi livelli (L1,L2….) e i sistemi di controllo e di schedulazione prima esaminati. Ecco allora che il multicore può mostrare le sue piene potenzialità a discapito però di un maggior costo di produzione. Un processore realizzato con questa filosofia è l’AMD Opteron quad-core, basato su di una struttura quad-core nativo (ovvero integrata su unico supporto di silicio). Un compromesso tra costi e funzionalità (fattore questo sicuramente molto importante e condizionante), può essere raggiunto con un approccio ibrido, ovvero fare uso di più di un die integranti più core. Per esempio un quad-core si può realizzare accoppiando due dual-core realizzati in chip distinti.

Figura 5: il quad-core Opteron di AMD

Figura 6: processore UltraSPARC da 8 core Dimensioni: 2 pollici quadrati
Pro e contro del multicore
A questo punto i vantaggi del multcore risulteranno sufficientemente chiari. Dal punto di vista dell’elettronica applicata otteniamo così Server (e computer di ultima generazione) sempre più potenti e con maggior “respond faster”, desktop più performanti sia per le applicazioni di lavoro che per quelle di intrattenimento, e laptops (e sistemi portatili in genere) più piccoli e con autonomie (battery life) crescenti. Un altro vantaggio non ancora menzionato è la possibilità di unire su di un unico supporto sia una CPU (Central Processing Unit) che una GPU (Graphics Processing Unit), particolare che andrebbe a tutto vantaggio di portabilità e performance nel settore elettronico-multimediale e non solo. Gli svantaggi esistono nella misura in cui un processore multicore viene impiegato in modo inappropriato. Uno dei problemi più importanti può essere l’inadeguatezza dei sistemi operativi e dei software delle diverse applicazioni, i quali possono non essere ottimizzati per supportare il multi-threading e quindi il sistema multicore. Per i sistemi embedded il problema è meno sentito, dal momento che il relativo software di gestione deve essere ottimizzato per forza di cose. I sistemi general-purpose come i personal computer, sono indubbiamente i più soggetti al problema, che in questo caso richiede, alle aziende di software, uno sforzo aggiuntivo affinché i loro prodotti possano adeguarsi a queste nuove necessità.
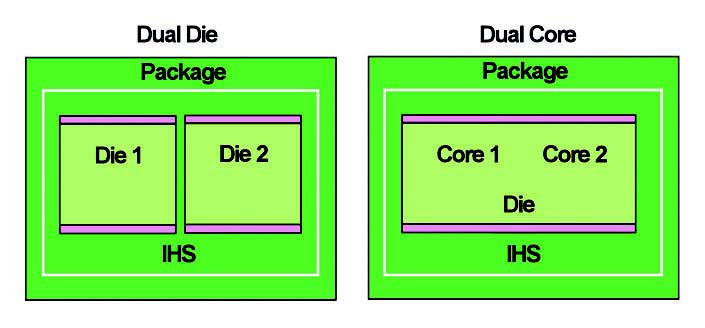
Figura 7: dual core in die doppio e singolo.

Figura 8: schema a blocchi di un dual-core AMD
Conclusioni
Certamente l’architettura multicore ha dato una direzione diversa allo sviluppo di processori sempre più performanti. Molti sistemi sono ormai basati sull’architettura multicore, dalle console di gioco, ai grandi server. I possibili sviluppi, annunciati e non, sono davvero molteplici e volti a risolvere problematiche di elaborazione diversificate. A questo proposito si parla anche di architetture “Heterogeneous Multi-Core”, ovvero strutture in cui core specializzati per l’elaborazione di particolari processi, vengono affiancati a core di uso generale. La cooperazione tra le coppie di core consente così maggiore potenza di calcolo e quindi tempi di elaborazione più brevi, in applicazioni come i giochi 3D, l’acquisizione e l’elaborazione audio/video. In questo modo, il compito che un tempo era demandato al software, adesso migra direttamente nell’hardware, ed in modo particolare sui processori.
