
Due proposte per il settore embedded che rispecchiano due differenti soluzioni architetturali: da un lato ARM si basa su un core RISC e dall’altro, Renesas, con un core CISC.
Renesas e ARM hanno un ruolo rilevante in un’infinità di applicazioni. Ad esempio, il Mindstorms NXT è composto di servomotori e sensori (di tipo luminoso, tattile, sonoro e a ultrasuoni) e da un dispositivo intelligente: un microprocessore a 32 bit di Atmel, siglato come AT91SAM7S256 (un dispositivo che appartiene alla classe ARM7) con la frequenza di funzionamento di 48 MHz e, come si rileva dalla sua sigla di identificazione, con 256k di memoria non volatile e 64k di RAM. Il core ARM, inoltre, è utilizzato anche in altre applicazioni; la tabella 1 mostra un confronto delle principali caratteristiche hardware di alcuni dispositivi presenti nel mercato.

Tabella 1: Alcuni sensori disponibili per WSN.
Diversi sono i costruttori che utilizzano un core ARM nelle loro applicazioni: tra i micro utilizzati possiamo citare LPC2148 e LPC2378, della famiglia LPC2000. Per esempio, il microcontrollore LPC2378, prodotto da NXP, appartiene alla famiglia degli ARM7: si identifica, a questo riguardo, un core di microprocessori di tipo Reduced Instruction Set Computer (RISC) a 32 bit ottimizzati per applicazioni negli ambiti in cui il consumo ha una certa importanza, cioè è di tipo power-sensitive. L’impiego principale di questo componente NXP è rivolto al settore per le applicazioni di controllo industriale, sistemi elettro-medicali, convertitori di protocollo e sistemi di comunicazione. Il microcontrollore LPC2378 è basato su una CPU ARM7TDMI-S a 16/32 bit combinata ad una memoria Flash ad alta velocità. I microprocessori ARM consentono un elevato throughput di istruzione e un’eccellente risposta in tempo reale alle interruzioni. Il microcontrollore è provvisto anche di un’interfaccia di memoria a 128 bit e, tramite un’architettura comprendente acceleratori hardware, consente l’esecuzione di codice a 32 bit alla massima frequenza. Il microcontrollore è adatto anche nelle applicazioni mission-critical e per questo è disponibile anche la modalità di utilizzo “thumb” che permette così di aumentare le prestazioni di circa un 30%. Il componente trova un suo ruolo importante anche per le applicazioni basate su comunicazioni seriali multi-purpose in quanto è fornito di numerosi tipi di interfacce con l’esterno. La figura 1 mostra l’architettura interna di questo microcontrollore.
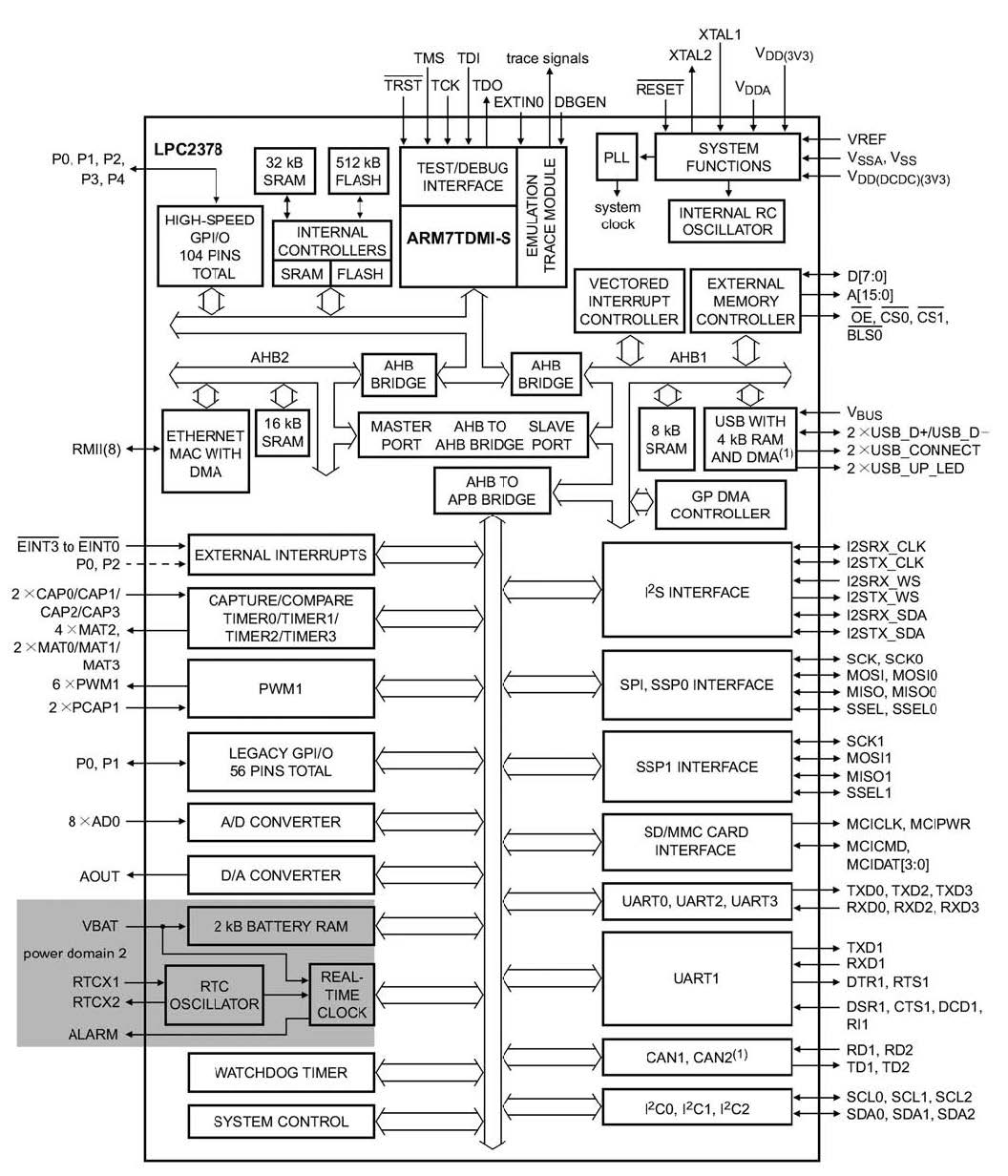
Figura 1: architettura del microcontrollore LPC2378.
Il microcontrollore è dotato di due particolari bus: HB (Advanced High-Performance Bus) e APB (Advanced Peripheral Bus). Il primo è utilizzato per interfacciarsi, ad alta velocità, con la memoria ester na, mentre il secondo si occupa della connessione con le periferiche on-chip. Tra queste tipologie esistono dei bridge che hanno lo scopo di agevolare lo scorrimento del traffico evitando percorsi più lunghi e, nello steso tempo, permettono di evitare un errato flusso di informazioni garantendo una totale indipendenza tra essi. Questi sono stati introdotti nel 1996 dall’AMBA (Advanced Microcontroller Bus Architecture). Renesas e ARM si differenziano sostanzialmente per l’uso di core differenti; infatti, ARM, con ARM7TDMI, basa la sua tecnologia su RISC, mentre Renesas ha preferito utilizzare un’architettura di tipo CISC. In ogni caso, con la famiglia RX, Renesas si è indirizzata verso una soluzione ibrida. La tabella 2 mostra un sottoinsieme, abbastanza ristretto, di processori con alcune loro caratteristiche hardware.
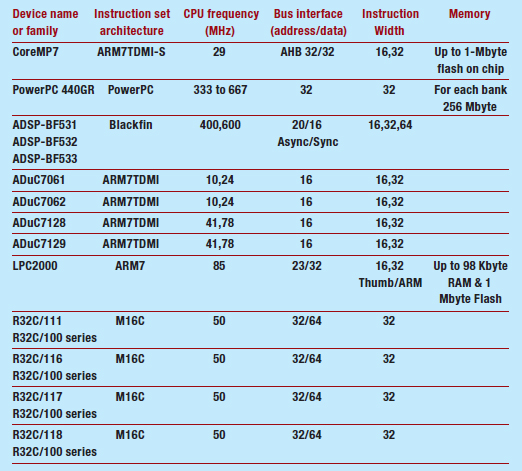
Tabella 2: Breve panoramica sulle disponibilità esistenti per i micro a 32 bit.
Arm
L’architettura ARM copre un importante settore, grazie alle sue caratteristiche di basso consumo in rapporto alle sue prestazioni, orientato ai dispositivi mobili dove il risparmio energetico delle batterie è certamente un aspetto importante. Inoltre, è una delle più diffuse architetture a 32 bit del mondo. I processori ARM sono utilizzati in PDA, cellulari, lettori multimediali, videogiochi portatili e periferiche per computer. Appartengono alla famiglia ARM i processori XScale e OMAP prodotti da Texas Instruments. Il microprocessore AR7TDMI è un membro della famiglia di processori ARM che utilizza un’architettura RISC a 32-bit, la cui struttura interna rispecchia quella di Von Neumann. I dispositivi ARM presentano un’architettura RISC ‘load and store’ per parole di 16 e 32 bit, un set di istruzioni ortogonali, 37 registri di interi a 32-bit (6 registri di stato e 31 di uso generale) e 7 modi di operare (USR, FIQ, IRQ, SVC, ABT, SYS, UND). Il suo set di istruzioni ed il relativo meccanismo di decodifica sono abbastanza semplici rispetto a sistemi come i processori CISC e questa minor complessità si traduce in una notevole velocità di esecuzione delle istruzioni e di risposta agli eventi ester ni (interrupt). La figura 2 mostra la pipeline dell’ARM7TDMI nella configurazione ARM e Thumb.
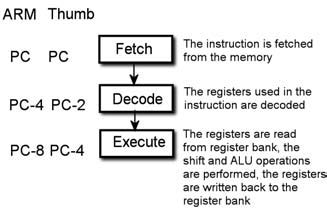
Figura 2: pipeline dell’ ARM7TDMI nella configurazione ARM e Thumb
Il processore consente di operare su dati di differente dimensione. Oltre alla parola standard (32 bit), infatti, possono essere gestiti dati di ampiezza pari al singolo byte (8 bit) o anche valori a 16 bit; inoltre, possono anche essere specificati dati numerici con o senza segno (in notazione complemento a 2). L’organizzazione della memoria può essere di tipo big endian o little endian ed il processore è dotato di un’interfaccia di memoria in grado di gestire sia memorie statiche che dinamiche in maniera estremamente flessibile, anche sfruttando risorse di tipo misto all’interno della stesso sistema. Una delle caratteristiche più interessanti dei processori ARM sono 4 bit addizionali utilizzati lizzati per realizzare dei codici condizionali per ogni istruzione. Questi codici hanno ridotto le possibilità di indirizzo dato che il processore non ha molti bit per poterli specificare ma il grande vantaggio è che questi codici permettono di evitare i salti nei caso di semplici istruzioni if. Gli ultimi 4 bit dell’operando sono quindi comparati con i con le flag del CPSR. Il CPSR è un registro di controllo e di stato a 32 bit contenenti delle flag le quali monitorano il funzionamento del processore ed è in grado di settare particolari opzioni. Gli ultimi 4 bit del registro sono le classiche condition flag, mentre il bit 7 e 8 sono i bit che abilitano e disabilitano i due interrupt esterni al pr ocessor e. Il bit 5 è il cosiddetto THUMB e permette al processore di stabilire se le istruzioni lette sono da interpretare come istruzioni ARM o THUMB. Se il bit T è posto a 1 allora l’istruzione è da considerarsi in THUMB mode. I primi 5 bit rivestono un’importanza fondamentale, infatti determinano la modalità di funzionamento del processore, tra le sei privilegiate: USER, FIQ, SUPERVISOR, ABOR T, IRQ, UNDEFINED e SYSTEM. Il normale funzionamento del micro è la modalità “user mode”. A fronte di un interrupt, o un errore della memoria, il processore cambia modalità di funzionamento e i registri interni cambiano le loro funzioni. Ogni modo di funzionamento ha il proprio link register e il proprio stack pointer. Inoltre, tutti i modi di funzionamento che gestiscono le eccezioni hanno un registro aggiuntivo chiamato SPSR, Saved program status register. Al verificarsi dell’evento, l’intero CPSR è salvato nel SPSR. Questo fa sì che, ultimata l’esecuzione del codice di reazione all’evento, il programma è in grado di ripartire da dove si era fermato. I registri non possono essere utilizzati tutti insieme, nella modalità di esecuzione normale solo sedici di essi (uno dei quali è il program counter) sono accessibili, mentre una serie di banked register sono visibili solo, quando il processore opera nella altre modalità. Per evitare di dover memorizzare il contenuto di molti registri in memoria, prima di effettuare il cambio di modalità operativa verso quella di Fast Interrupt Request (FIQ), essa può beneficiare di una serie di ben sette registri dedicati. A parte la gestione degli eventi di interrupt e fast interrupt sono previste le modalità di gestione di instruction e data abort, per gli errori nella gestione delle operazioni sulla memoria, una modalità per la gestione delle istruzioni indefinite e l’interfacciamento con i coprocessori ed una modalità di interrupt alla quale è possibile accedere tramite un’istruzione software (SWI). La tabella 3 riporta le eccezioni che fanno cambiare modalità al processore.

Tabella 3: Relazione esistente tra le diverse modalità per ARM7DTMI
Ognuno degli eventi ha associato un vettore che rappresenta l’indirizzo al quale punta il PC immediatamente dopo il verificarsi dell’evento stesso. Ogni eccezione ha chiaramente una sua priorità, questo per gestire i conflitti nei casi in cui due eccezioni sopraggiungano contemporaneamente. Un’altra caratteristica unica del set di istruzioni è la capacità di spostare i dati durante le normali operazioni sui dati (operazioni aritmetiche, logiche e di copia di registri). Inoltre, il processore ricorre a meno accessi alla memoria e riesce a riempire meglio le pipeline. Quindi le CPU ARM possono utilizzare frequenze inferiori a quelle di altri processori consumando meno potenza per svolgere gli stessi compiti. Un processore ARM possiede anche caratteristiche viste raramente nei processore RISC come ad esempio l’indirizzamento relativo al PC, indirizzamento con il pre e post incremento. Una caratteristica curiosa dei processori ARM è che, con il tempo, il set di istruzioni incrementa. I primi processori ARM (prima dell’ARM7TDMI) per esempio non avevano istruzioni per caricare quantità a due bit. E quindi non erano in grado di gestire direttamente tipi di dati corti. I primi processori ARM di largo consumo come gli ARM7 erano basati su un disegno con pipeline a 3 stadi: fetch, decode e execute. I processori più moderni, come l’ARM11, per incrementare le prestazioni, sono passati a pipeline a 5 stadi.
Altri cambiamenti per incrementare le prestazioni includono un sommatore veloce e un sistema di predizione dei salti. Altra interessantissima caratteristica dei processori ARM riguarda le instrunction set presenti. Oltre al nativo ARM a 32 bit ne esistono altri: il Thumb e il Jazelle. Thumb, ovvero una porzione dell’architettura a 32 bit che implementa un set di istruzioni a soli 16 bit il cui comportamento è equivalente ad alcune istruzioni appartenenti al set di istruzioni completo dell’ARM. Questa soluzione consente di ottenere un’elevata densità di codice mantenendo molte delle prestazioni del processore ed è una caratteristica unica della famiglia di processori ARM. Il sistema di decodifica del set di istruzioni Thumb consente di realizzare una traduzione dinamica immediata verso il set di istruzioni completo dell’ARM ed all’interno del medesimo programma sorgente possono essere utilizzati entrambi i set di istruzioni, che il processore è in grado di eseguire cambiando la sua configurazione interna. Per passare da uno stato interno all’altro i due set di istruzioni forniscono una particolare istruzione denominata branch and exchange; essa consente, tra l’altro, di saltare ad altre parti del codice in esecuzione. Esistono, nel contempo, alcune limitazioni, per esempio solo i salti possono essere condizionati e alcuni opcode non possono essere utilizzati da tutte le istruzioni. Nonostante questo, nel caso di sistemi dotati di limitata larghezza di banda verso la memoria, il Thumb fornisce prestazioni migliori del set di istruzioni completo. Molti sistemi embedded sono dotati di un bus verso la memoria limitato e sebbene il processore possa indirizzare con 32 bit spesso si utilizzano indirizzamenti a 16 bit o simili. In queste situazioni conviene creare codice Thumb per la maggior parte del programma e ottimizzare le parti di codice che richiedono molta potenza di calcolo utilizzando il set di istruzioni completo. Esistono anche due varianti del codice Thumb: il Thumb-2 il quale contiene particolari istruzioni a 32 bit, e il Thumb-2EE specificamente progettato per gestire codice per applicazioni real time. Il primo processore dotato di Thumb è stato l’ARM7TDMI. Tutti gli ARM9 e le famiglie successive (incluso gli XScale) sono dotati di Thumb. Il Jazelle, invece, permette al processore di eseguire nativamente il Java byte code. Questa tecnologia è totalmente compatibile con il codice ARM standard e il Thumb. Il primo processore dotato di Jazelle è stato l’ARM926J-S, utilizzato sui telefoni cellulari per velocizzare l’esecuzione del software e dei giochi Java. Il Jazelle aumenta per oltre il 95% le prestazioni del codice java supportando 140 istruzioni java ed emulando le restanti 94 con routine ARM.
Renesas
Renesas propone diversi modelli che senz’altro trovano riscontri positivi nel mercato; infatti, la qualità, le prestazioni e le funzionalità offerte sono sicuramente un aspetto importante per la definizione di una valida alternativa. È possibile, per esempio, citare la serie 1700 della famiglia H8SX: questa offre una nuova generazione di sistemi di controllo utilizzati negli autoveicoli. Questi dispositivi dispongono, infatti, di una frequenza operativa che può arrivare a 80 MHz e utilizzano, poi, un core di CPU CISC a 32 bit H8SX. Questi modelli rappresentano la naturale evoluzione tecnica rispetto a quelli della serie H8SX/1500; infatti, la serie 1700 propone dei miglioramenti architetturali e prestazionali. Possiamo, in particolare porre in evidenza che il componente H8SX/1725F dispone di una memoria non volatile di tipo flash con prestazioni sicuramente superiori rispetto a quelli precedenti. Non solo, dispone anche di un set di istruzioni che permette di interfacciarsi direttamente con le diverse periferiche interne, oltre alla garanzia della totale compatibilità delle istruzioni che fanno capo al core utilizzato con i prodotti delle famiglie H8SX e H8S. C’è di più, Renesas propone anche una serie di MCU basati sulla CPU core a 32 bit di elevate prestazioni R32C/100: questo contiene un moltiplicatore a 32 bit, un’unità FPU in singola precisione e un barrel-shifter ad alta funzionalità. Il core è sempre un CISC (Complex Instruction Set Computer). Questi modelli propongono diversi accorgimenti tecnici che sono di estremo interesse per le applicazioni più spinte, per esempio la memoria on-chip di tipo flash permette operazioni di lettura/scrittura in un tempo che è pari a tre volte superiore a quella delle serie M32C/80, oltre ad un livello di affidabilità non trascurabile. Tutto questo incide sulla programmazione in linea. Renesas non finisce di stupire. Con la proposta della famiglia RX, che si basa su un “CISC riveduto” con istruzioni di lunghezza variabile per migliorare le prestazioni della memoria di programma, segna una nuova evoluzione delle sue scelte architetturali. In questa prospettiva, l’architettura della famiglia RX (dove X sta per eXtreme family), si coniugano gli aspetti della famiglia M16C con quelli della H8S/H8SX, oltre a potenziarne le prestazioni della memoria flash on-chip. La famiglia RX risponde al mercato proponendo una soluzione tecnica che trova riscontri nella famiglia RISC e CISC. Grazie ad una soluzione integrata, RX è in grado di proporre prestazioni superiori: un aumento di almeno del 30% dell’efficienza del codice, una diminuzione di oltre il 60% dei consumi e un aumento delle sue prestazioni in termini di MIPS e MHz. A questo proposito la figura 3 mostra le prestazioni raggiungibili da RX, mentre la figura 4 pone in evidenza le varie caratteristiche disponibili in maniera abbastanza riassuntiva.
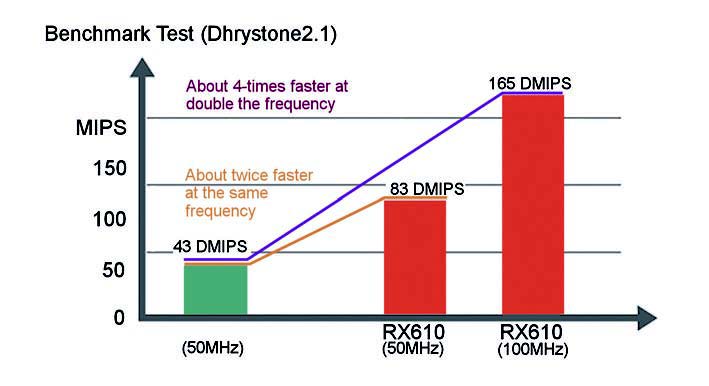
Figura 3: prestazioni per la famiglia RX di Renesas.

Figura 4: schema riassuntivo per la famiglia RX di Renesas.
Uno degli aspetti maggiormente visibili da parte di un programmatore è la nuova disponibilità di registri a 32-bit. Infatti, nel modello RX i registri a 32-bit sono 16. La figura 5 mostra, secondo stime di Renesas, di quanto il numero dei registri, con la loro dimensione, incide sulle prestazioni di un microcontrollore.
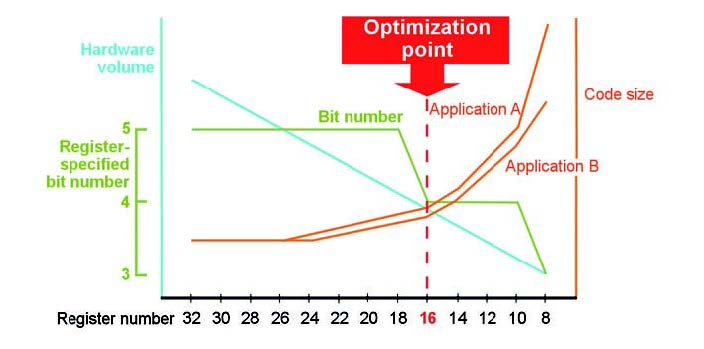
Figura 5: quanto il numero dei registri, con la loro dimensione, incide sulle prestazioni di un microcontrollore.
La figura pone in evidenza che l’uso di registri, definiti come general-purpose, offrono migliori prestazioni per le operazioni di tipo aritmetico e di controllo, le prestazioni scendono notevolmente utilizzando solo 8 registri, oltre ad aumentare la densità del codice generato dovuto, in prima battuta, dall’uso frequente di istruzioni di save/restore utilizzati. Un altro aspetto da non trascurare, come si evince dalla figura, è il rapporto con i bit number dei registri. Come vediamo, il punto di ottimizzazione si incontra con l’intersezione tra il numero di 16 registri con profondità di 32bit. Renesas ha ottimizzato la gestione degli interrupt utilizzando a questo scopo un algoritmo denominato register-assignment per aumentare l’efficienza della loro gestione: questa nuova gestione sostituisce l’altro sistema chiamato banco di registri. La figura 6 visualizza lo schema utilizzato.
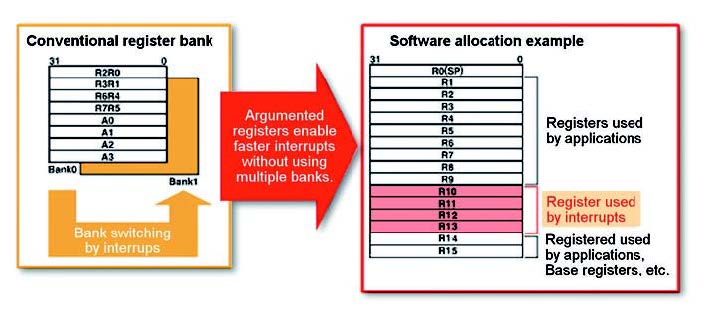
Figura 6: gestioni eventi asincroni.
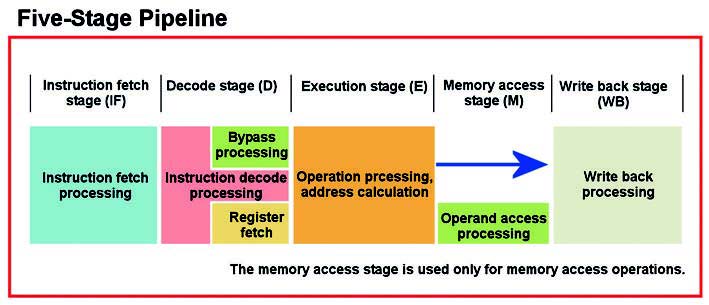
Figura 7: pipeline per la famiglia RX di Renesas.
La struttura interna di RX rispecchia una diversa concezione fino ad ora utilizzata. I progettisti di Renesas propongono, in questo modo, due metodi per raggiungere i nuovi valori prestazionali. Per prima cosa, si utilizza una architettura di tipo Harvard per abilitare l’esecuzione parallela tra prelievo dell’istruzione e accesso dei dati. Inoltre, si utilizza una struttura basata su cinque stadi di pipeline, mentre si adopera una sequenza, definita come, out-of-order per eseguire porzioni di codice che non risultano essere dipendenti tra loro o quando, nella sequenza di pipeline, si incontra, così come è chiamata, un wait mode. La figura 8 pone in evidenza quanto affermato. Utilizzare una struttura del genere permette di raggiungere una velocità fino a 200 MHz.
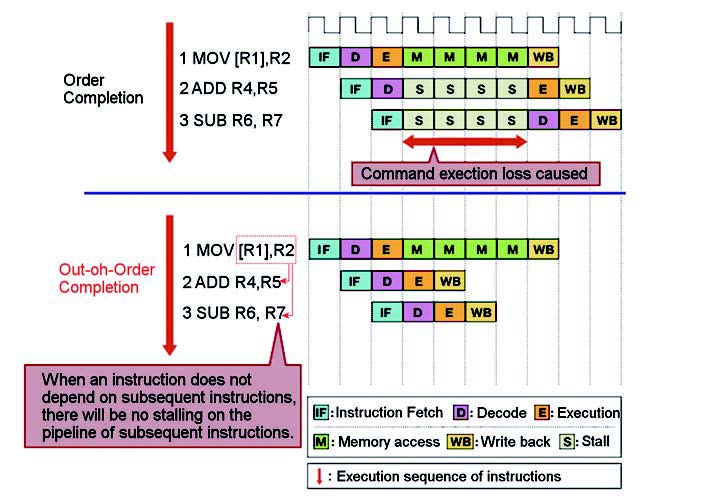
Figura 8: la sequenza Out-of-Order per l’esecuzione di parti di codice non indipendenti.

