
Nei sistemi embedded da diversi anni si sono affermate soluzioni che si basano sulla pila TCP/IP. Vediamo alcune considerazioni di base che servono a comprendere meglio questo mondo ricco di protocolli dalle applicazioni più svariate. Il modello TCP/IP è più semplice del modello ISO/OSI e risulta strutturato in quattro livelli. Il modello presenta un’evidente semplificazione con la mancanza completa dei livelli di Sessione e di Presentazione, le cui funzionalità sono completamente demandate al livello Applicativo. Sarà dato, poi, particolare risalto al concetto di MAC.
INTRODUZIONE
Se parliamo di reti di computer ci riferiamo ad un insieme eterogeneo e vasto di mezzi fisici e logici. Infatti, possiamo parlare di cavo telefonico, di fibra ottica, di comunicazioni via satellite, di linee seriali che possono interagire con un insieme diversificato di protocolli raggruppati secondo una stratificazione logica: il modello ISO/OSI e la suite TCP/IP (che è un derivato della pila ISO/OSI) sono illustrati nella figura 1.
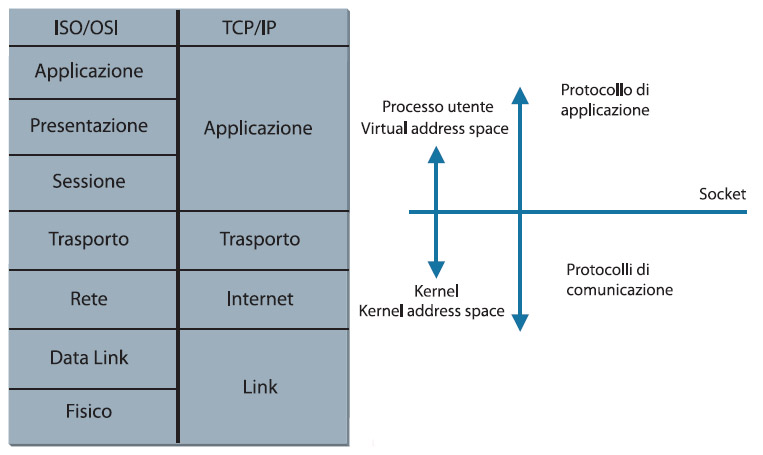
Figura 1. Il modello ISO/OSI ed il protocollo TCP/IP: struttura dei protocolli ISO/Osi e TCP/IP, con le relative corrispondenze fra kernel e user space
IL MODELLO ISO/OSI
L’ISO (International Standard Organization) è uno dei principali enti di standardizzazione internazionale che si occupa anche di reti di calcolatori. Negli anni ’80 decise di supportare lo sforzo progettuale degli sviluppatori di reti dando vita ad un modello di riferimento chiamato OSI (Open Systems Interconnection) strutturato in sette livelli. L’idea di base era quella di identificare e circoscrivere problematiche e funzioni per poi organizzarle in livelli separati ma interoperanti. Non voglio puntualizzare in questo articolo i pregi e i difetti del modello ISO/OSI, ma in sostanza siccome il modello si è rivelato troppo complesso e poco flessibile, l’industria ha deciso di adottare la soluzione DoD (nome alternativo per la suite TCP/IP - vedi riquadro).
IL MODELLO TCP/IP
Il suo nome deriva dai due principali protocolli che lo compongono, il TCP Trasmission Control Protocol e l’IP Internet Protocol (tabella 1).
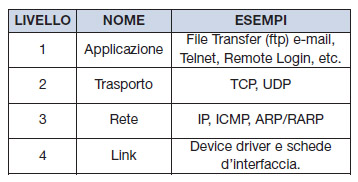
Tabella 1. I quattro livelli del protocollo TCP/IP
Nel caso del TCP/IP si ha un livello 4 connection-oriented poggiato su livelli 2 e 3 connectionless. L’affidabilità della comunicazione è demandata completamente al livello di trasporto. Il livello 3 o livello internet contiene protocolli come l’IP (Internet Protocol) che forniscono la capacità di instradamento del messaggio attraverso una molteplicità di reti.
Le funzioni dei vari livelli sono le seguenti:
- Applicazione
È relativo ai programmi d’interfaccia utente e in genere sono realizzati secondo il modello client/server. - Trasporto
Fornisce la comunicazione tra le due stazioni terminali su cui sono in esecuzione gli applicativi, regola il flusso delle informazioni e può fornire un trasporto affidabile, cioè un recupero errori. Il protocollo principale di questo livello è il TCP. - Rete
Si occupa dello smistamento dei singoli pacchetti su un rete complessa e interconnessa. - Connessione (Link)
È responsabile dell’interfacciamento al dispositivo elettronico che effettua la comunicazione fisica: gestisce l’invio e la ricezione dall’hardware dei pacchetti.
STRATIFICAZIONE TFTP
Se consideriamo un tipico esempio di applicazione, come un TFTP, il modello di stratificazione è definito nella figura 2.
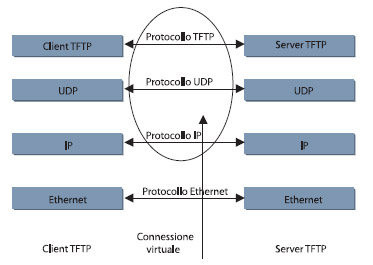
Figura 2. I livelli della pila ISO/OSI in una comunicazione tra server e client
Questa figura mostra la suddivisione in quattro livelli su UDP/IP con 802.3: l’applicazione TFTP permette di scambiare file fra due host utilizzando un UDP. Il flusso dei dati si svolge dal blocco TFTP che scende attraverso l’UDP, utilizza l’IP fino ad arrivare alla trasmissione fisica Ethernet. Poi, in ricezione, risale dalla comunicazione fisica fino alla gestione “vera dei dati con TFTP. Ogni livello sottostante aggiunge un pezzo d’informazione al blocco dei dati da trasferire. La figura 3 mostra l’incapsulamento per ciascun livello.
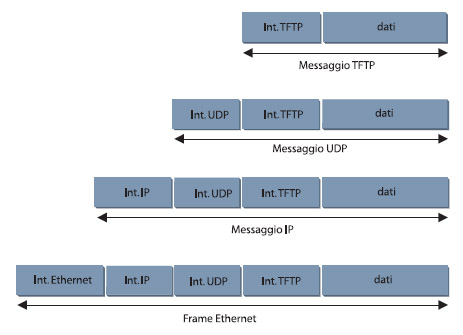
Figura 3. I livelli di incapsulamento del dato in un frame ethernet
IL BYTE E GLI OTTETTI
Nell’architettura di rete si utilizza il termine di ottetto. Questo è costituito da una quantità di 8 bit di dati, ma spesso si utilizza come sinonimo il termine di byte. Il motivo sull’uso del termine ottetto nasceva perché in passato alcuni sistemi di computer non utilizzavano byte di 8 bit (esempio la serie DEC-10 e le serie Control Data Cyber). Un altro argomento importante è l’ordine in memoria dei dati da rappresentare. Si utilizza, a questo proposito, il termine Little-Endian e Big-Endian. In una rappresentazione scalare la scelta sull’ordine dei byte è arbitrario. Ci sono 4!=24 modi di specificare l’ordine di quattro bytes in una word, ma solo due sono sensibili. Se, infatti, consideriamo un intero di 16 bits costituito da due byte, i due modi sensibili per rappresentare il numero sono chiamati Big-Endian e Little-Endian. La endianess di un computer dipende essenzialmente dalla architettura hardware usata; Intel e Digital usano il little endian, Motorola, IBM, Sun (sostanzialmente tutti gli altri) usano il big endian. Il formato dei dati contenuti nelle intestazioni dei protocolli di rete è anch’esso big endian; altri esempi di uso di questi due diversi formati sono quello del bus PCI, che è little endian, o quello del bus VME che è big endian. Esistono poi anche dei processori che possono scegliere il tipo di formato all’avvio e alcuni che, come il PowerPC, possono pure passare da un tipo di ordinamento all’altro con una specifica istruzione. In ogni caso in Linux l’ordinamento è definito dall’architettura e dopo l’avvio del sistema resta sempre lo stesso, anche quando il processore permetterebbe di eseguire questi cambiamenti. Si utilizza il termine big-endian quando si assegna il più basso indirizzo al più alto valore in memoria. Questo perché il “big end” (most significant) di uno scalare, considerato come numero binario, arriva come primo in memoria. Osserviamo indirizzi di memoria crescenti da sinistra e destra. Il Powerpc utilizza una notazione di questo tipo. Si utilizza, in alternativa, il termine Little-endian quando si assegna il più basso indirizzo al basso valore in memoria. Questo perché il “little end” (most significant) di uno scalare, considerato come numero binario, arriva come primo in memoria. Osserviamo indirizzi di memoria crescenti da destra a sinistra. Il processore Intel 80x86, per esempio, utilizza una notazione little-endian. La figura 4 mostra lo schema della disposizione dei dati in memoria a seconda della endianess.
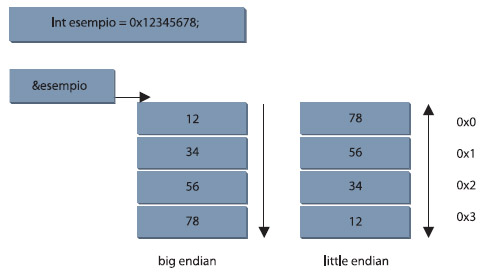
Figura 4. L’allocazione dei dati in memoria nell’uso della endianess
Il listato 1 e le tabelle 2 e 3 mostrano un esempio su di una struttura contenente variabili scalari e tipi char in C.

Tabella 2. Rappresentazione in Big-endian
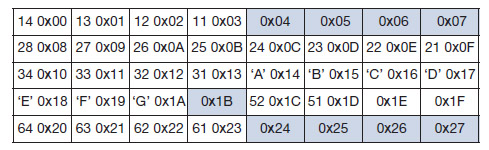
Tabella 3. Rappresentazione in Little-endian
Struct {
Int a; /* 0x1122_1314 word */
Double b ; /* 2122_2324_2526_2728 */
Char *c; /* 0x3132_3334 word */
Char d[7]; /* ‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’
array of bytes */
Short e; /* 0x5152 halfword */
Int f; /* 0x6162_6364 */
}
S;
| Listato 1 |
ROUTINE DI ORDINAMENTO DEI BYTE
Abbiamo sostenuto che differenti processori utilizzano differenti rappresentazioni in memoria e per ovviare a quest’inconveniente diventa necessario predisporre di alcune routine di ordinamento. Questo è un problema tipico dell’endianess, quando si passano dei dati da un tipo di architettura all’altra. Se, infatti, usiamo stack TCP/IP su architetture PowerPC dobbiamo fare in modo di utilizzare rappresentazioni in Big-Endian. Per questa ragione si usano delle funzioni C, o delle macro, di conversione che servono a tener conto in maniera trasparente della differenza fra l’ordinamento usato sul computer e quello che viene usato nelle trasmissione sulla rete; queste funzioni sono htonl, htons, ntohl e ntohs:
- htonl. Converte l’intero a 32 bit hostlong dal formato della macchina a quello della rete;
- htons. Converte l’intero a 16 bit hostshort dal formato della macchina a quello della rete;
- ntohl. Converte l’intero a 32 bit netlong dal formato della rete a quello della macchina;
- ntohs. Converte l’intero a 16 bit netshort dal formato della rete a quello della macchina.
I nomi sono assegnati usando la lettera n come mnemonico per indicare l’ordinamento usato sulla rete (da network order) e la lettera h come mnemonico per l’ordinamento usato sulla macchina locale (da host order), mentre le lettere s e l stanno ad indicare i tipi di dato (long o short, riportati anche dai prototipi). Usando queste funzioni si ha la conversione automatica: nel caso in cui la macchina che si sta usando abbia una architettura big endian queste funzioni sono definite come macro vuote. Per questo motivo vanno sempre utilizzate, anche quando potrebbero non essere necessarie, in modo da assicurare la portabilità del codice su tutte le architetture. Un’altro insieme di funzioni di manipolazione serve per passare dal formato binario usato nelle strutture degli indirizzi alla rappresentazione simbolica dei numeri IP che si usa normalmente. Esistono altre funzioni, per esempio la conversione degli indirizzi IPv4 da una stringa in cui il numero di IP è espresso secondo la cosiddetta notazione dotted-decimal, (cioè nella forma 192.168.0.1) al formato binario (direttamente in network order) e viceversa; in questo caso si usa la lettera a come mnemonico per indicare la stringa. Dette funzioni sono inet_addr, inet_aton e inet_ntoa:
- inet_addr. Converte la stringa dell’indirizzo dotted decimal in nel numero IP in network order, cioè da una notazione con punto ad un indirizzo di Internet.
- inet_ntoa. Effettua la conversione opposta, cioè converte un indirizzo IP in una stringa dotted decimal
- inet_aton. Converte la stringa dell’indirizzo dotted decimal in un indirizzo IP.
MAC
L’indirizzo MAC è integrato nella scheda stessa direttamente dal costruttore: ogni scheda ha un suo MAC e determina in maniera univoca la scheda. Questo indirizzo è rilasciato dall’IEEE ed è costituito da due campi: il Vendor Code e il Serial Number (l’IEEE determina il Vendor Code), vedi tabella 4.

Tabella 4. Indirizzi MAC
L’utente può definire l’indirizzo logico agendo sui livelli superiori, ma non su quello fisico. Ogni costruttore ha un proprio codice, vedi tabella 5.
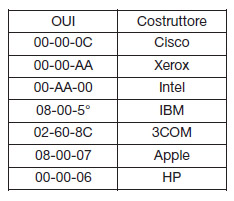
Tabella 5. Alcuni codici OUI
L’indirizzo MAC è composto da 6 byte ed è diviso in due parti: 3 byte identificano il costruttore, e gli altri tre è un numero seriale stabilito dal costruttore stesso (tabella 4). Il codice del costruttore stabilito dall’IEEE è anche chiamato OUI (Organizationally Unique Identifier). L’indirizzo MAC non cambia se ci si sposta da una rete a un’altra, mentre lo stesso non accade per un Indirizzo IP. La conversione tra indirizzo MAC e indirizzo IP avviene mediante alcuni protocolli, il più conosciuto è ARP. Per un dispositivo fisico un MAC valido deve essere assegnato dallo sviluppatore, questo indirizzo è usato a livello di data link ed è implementato dal dispositivo fisico e dal driver di basso livello. L’indirizzo di IP viene assegnato dall’amministratore di rete o utilizzando il protocollo DHCP. Quando stiamo sviluppando un’applicazione embedded, allora lo sviluppatore diventa amministratore di sistema e assegna l’indirizzo IP. Se, per esempio, deve realizzare un local network tra la sua board e un PC allora deve assegnare gli indirizzi IP utilizzando un file C (vedi listato 2).
const tU08 hard_addr [6] = { 0x01, 0x23, 0x45,
0x56, 0x78, 0x9a };
const tU08 prot_addr [4] = { 192, 168, 2, 3 };
const tU08 netw_mask [4] = { 255, 255, 255, 0 };
const tU08 dfgw_addr [4] = { 192, 168, 2,1 };
const tU08 brcs_addr [4] = { 192, 168, 2, 255 };
| Listato 2 |
Possiamo, quindi, racchiudere in un file l’assegnazione del MAC e dell’indirizzo IP (listato 2), l’indirizzo di MAC è rappresentato dalla variabile hard_addr, mentre l’IP del target è identificato come prot_addr.
CONCLUSIONI
Il mondo delle reti è un argomento vasto e ricco di protocolli. Esistono diverse normative e linee di riferimento in continuo aggiornamento. Dal punto di vista del firmware ci sono diverse questioni ancora aperte relativamente alle molteplici applicazioni che invadono il TCP/IP.



L’instradamento IP viene utilizzato per individuare i percorsi in una rete TCP/IP dove verranno inviati i dati. La tecnica prevede anche l’uso di tabelle-database, con molti nodi di rete, attraverso un instradamento statico e dinamico. La funzioe socket è la classica impiegata per attivare una comunicazione.
Si prevede un corso sul network programming?
Ci organizzeremo per farlo 😉
Come strumenti (che sicuramente conoscerete), suggerirei qualche tuttorial di Scapy (vorrei impararlo) e hping, insieme a qualche tutorial sui socket in diversi linguaggi…
Ottimi tools. Grazie per il suggerimento 😉