
Se si vuole eseguire un modello di rete neurale su un sistema embedded, il Raspberry Pi rappresenta senza alcun dubbio la migliore opzione attualmente disponibile. In questo articolo vedremo come configurare una normale scheda Raspberry Pi per l'esecuzione di modelli di Deep Learning, attraverso l'installazione guidata di OpenCV, TensorFlow e Keras.
Introduzione
Il Deep Learning (DL), un sottoinsieme del Machine Learning (ML) e più in generale dell'intelligenza artificiale (AI), utilizza dei modelli di rete neurale per decidere, in modo completamente autonomo, il valore assunto da un'uscita a fronte di un determinato valore degli ingressi. Una delle applicazioni più note del Deep Learning è sicuramente la classificazione delle immagini: fornendo in ingresso alla rete un'immagine (acquisita in tempo reale tramite una telecamera oppure caricata in modalità "offline"), il modello deve riconoscere e classificare l'immagine, determinando a quale categoria di oggetti, animali, luoghi, o altro essa appartenga. Questa "predizione" compiuta dalla rete, coincidente con la sua uscita, è tanto migliore quanto più si approssima all'unità, corrispondente al grado di assoluta certezza (in tal caso la scelta compiuta dalla rete neurale è esatta al 100%). Nella pratica un grado di confidenza così elevato non è raggiungibile, per cui si ritengono già accettabili dei livelli di probabilità pari o superiori al 90%. In un qualunque modello di rete neurale possiamo individuare almeno due fasi distinte: la fase di training e la fase di inference (inferenza), come indicato nello schema di Figura 1. Partendo da un modello di rete neurale definito tramite una delle architetture per il Deep Learning oggi disponibili, la fase di training non fa altro che "alimentare" la rete fornendo una quantità enorme di valori in ingresso, aggiustando poi i parametri interni della rete in base allo scostamento rilevato tra il valore predetto dalla rete e il valore atteso. Tornando all'esempio del classificatore di immagini, la rete viene "addestrata" nella fase di training fornendo, una dopo l'altra, una quantità elevatissima di immagini (dell'ordine delle decine o centinaia di migliaia) e adattando a ogni iterazione i parametri interni della rete in base all'errore di predizione compiuto. L'obiettivo è ovviamente quello di rendere la rete sempre più intelligente, avvicinandosi il più possibile alle capacità di riconoscimento di un essere umano.
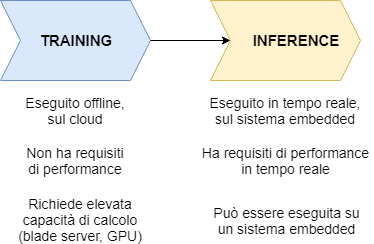
Figura 1. Le fasi di training e di inference
La fase di training è molto onerosa dal punto di vista computazionale, in quanto vengono applicati degli algoritmi (come il back propagation, la cui funzione è quella di eseguire una regolazione dei pesi della rete) la cui complessità cresce con il numero di nodi presenti nella rete. L'aspetto positivo è che il training viene eseguito una sola volta (o comunque solo quando si modifica il modello) e non ha requisiti di performance in tempo reale. Per questi motivi, il training viene eseguito su macchine con elevata capacità di calcolo (server, o ancora meglio sul cloud) e può richiedere anche parecchie ore. Eseguito il "tuning" del modello, questo può essere utilizzato su un'altra macchina, anche embedded, purché la stessa sia in grado di supportare il framework utilizzato per implementare il modello. A questo punto inizia la fase di inference (predizione): la rete, nel nostro caso eseguita su un Raspberry Pi, esegue l'algoritmo per cui è stata creata (ad esempio la classificazione delle immagini) dopo aver ricevuto i dati in ingresso (l'immagine da classificare). La fase di inference ha normalmente dei requisiti di performance real-time.
Deep Learning su un sistema embedded
È inutile negarlo, il Deep Learning è diventato un termine sempre più familiare negli ultimi anni, un termine entrato di diritto nel dizionario della tecnologia. Grazie ai recenti progressi compiuti in diversi settori dell'intelligenza artificiale, come i modelli di reti neurali convoluzionali (CNN), Long short Term Memory (LSTM), reti antagoniste generative (GAN), apprendimento con rinforzo e altro ancora, stiamo assistendo a un trend positivo di diffusione delle applicazioni in svariati contesti della vita di tutti i giorni. Il Deep Learning è oggi in grado di eseguire decisioni che un tempo erano facoltà esclusiva degli esseri umani. Ad esempio, scrivere la didascalia associata a un'immagine, comporre un brano musicale, riconoscere del testo scritto a mano, o persino guidare un veicolo in modo autonomo sono oggi funzionalità che possono essere eseguite da reti neurali opportunamente addestrate. Disponendo di una quantità elevatissima di serie di dati in ingresso (cosa oggi possibile grazie a internet e alla disponibilità di potenza quasi illimitata sul cloud), un modello di rete neurale opportunamente progettato può avvicinarsi ad imparare determinati compiti senza essere esplicitamente programmato. Quando si sente parlare di deep learning (soprattutto con riferimento alla fase di training) è normale sentire termini come GPU, CUDA, esecuzione parallela degli algoritmi, multi-thread, operazioni sulle matrici e altro ancora. Per questa applicazione utilizzeremo invece un approccio molto più semplice. Anche se alla fine testeremo dei modelli il cui training è stato eseguito offline su macchine molto performanti, il nostro sistema embedded sarà rappresentato da un comune Raspberry Pi 3 B/B+. Dimostreremo infatti come sia possibile eseguire su questo sistema un framework completo per il deep learning, divertendosi e imparando molti concetti utili relativi al mondo delle reti neurali. Il framework che utilizzeremo è Keras, che in questa configurazione sarà basato su TensorFlow, a sua volta un altro framework basato sui tensori e sviluppato da Google. Installeremo sul Raspberry Pi anche OpenCV, che può far comodo in altre applicazioni dove le immagini vengono acquisite "live" tramite una telecamera (la Pi Camera ufficiale oppure una webcam USB supportata dal Raspberry Pi). Risulta infatti superfluo e in alcuni casi anche lesivo voler reinventare l'acqua calda: se già esistono tool validi e liberamente utilizzabili, perché farne a meno?
Keras, TensorFlow e OpenCV
TensorFlow è una libreria software sviluppata dal Google Brain Team, un gruppo di ricercatori e sviluppatori che opera all'interno dell'organizzazione Machine Learning Intelligence di Google. La caratteristica principale di TensorFlow è quella di utilizzare tecniche di algebra computazionale particolarmente ottimizzate in termini di efficienza, rendendo possibile l'esecuzione di espressioni matematiche anche molto complesse su piattaforme hardware con stretti requisiti temporali o disponibilità limitate di capacità di elaborazione. Le principali funzionalità disponibili su TensorFlow possono essere così sintetizzate:
- definizione, ottimizzazione e calcolo efficiente di espressioni matematiche basate sull'utilizzo di array multi-dimensionali (detti anche "tensori")
- supporto per la definizione e programmazione di applicazioni di deep learning e machine learning
- utilizzo, eseguito in modalità trasparente all'utente, della GPU (ove disponibile)
- utilizzo efficiente delle risorse di memoria disponibili
- portabilità del codice tra architetture hardware differenti. Lo stesso codice può essere eseguito su CPU o GPU e il framework determina automaticamente quando l'esecuzione di una porzione di codice oppure un intero algoritmo può essere spostata su una GPU
- elevata scalabilità: il framework si adatta in modo autonomo a variazioni della capacità di calcolo disponibile e alle dimensioni delle strutture dati utilizzate dai modelli di rete neurale.
Keras è invece una libreria sviluppata in Python come progetto open source per lo sviluppo e la valutazione dei modelli di deep learning. Molto potente e semplice da utilizzare, Keras si appoggia su diversi framework di basso livello, selezionabili di volta in volta dall'utente, permettendo la definizione e l'addestramento di modelli di reti neurali con poche linee di codice. Keras non gestisce direttamente le operazioni di basso livello, come il prodotto tra tensori, la convoluzione o operazioni simili. Keras segue piuttosto un approccio di tipo modulare, permettendo l'utilizzo di più framework, detti anche "backend". La versione attuale di Keras gestisce tre backend: TensorFlow, Theano e CNTK. Theano è un framework open source per la gestione simbolica dei tensori sviluppato dal team LISA dell'università di Montréal. CNTK è invece uno strumento per la gestione di applicazioni di deep learning sviluppato da Microsoft. OpenCV (Open Source Computer Vision Library) non ha bisogno di presentazioni. Si tratta infatti di una delle più note librerie open source per le applicazioni basate su computer vision e machine learning. La libreria include oltre 2500 algoritmi ottimizzati, utilizzabili per l'identificazione e il riconoscimento di oggetti o persone, eseguire il tracking in tempo reale di oggetti in movimento e altre operazioni avanzate di elaborazione delle immagini.
Setup software
L'installazione contemporanea di Keras, TensorFlow e OpenCV sul Raspberry Pi può sembrare un'operazione molto complessa ma in realtà, seguendo alcuni semplici passi, vedremo come la stessa possa essere portata a termine senza grossi problemi e in un tempo relativamente ridotto.
Immagine Raspbian
Il primo passo consiste nell'installazione, su una scheda di memoria microSD di almeno 16 gigabyte ed elevata velocità di lettura/scrittura, della distribuzione Raspbian Stretch. Sceglieremo la versione completa disponibile quando è stato scritto l'articolo, ovvero la "Raspbian Stretch with desktop and recommended software". Una volta programmata la scheda microSD e avviato il Rasperry Pi, conviene procedere come di consueto, attivando la connessione di rete WiFi e abilitando sia il protocollo SSH che la connessione remota tramite VNC. D'ora in avanti sarà così possibile accedere alla scheda da remoto, senza dover collegare tastiera, mouse e monitor. Può essere utile a questo punto verificare la versione di Python3 installata, visto che la stessa verrà utilizzata nei passi successivi della configurazione del sistema. Digitare il seguente comando in una finestra terminale:
python3 -V
L'output dovrà essere analogo a quanto visibile in Figura 2.
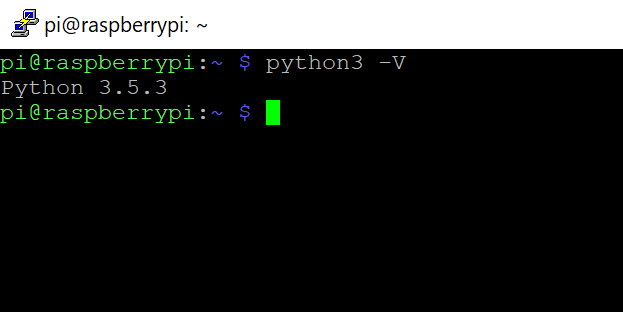
Figura 2. Verifica della versione di Python3
Installazione di pip
Il packet installer di Python va installato attraverso i seguenti comandi:
wget https://bootstrap.pypa.io/get-pip.py
sudo python3 get-pip.py
Creazione e attivazione di un ambiente virtuale
Lavorando con Python, può risultare molto utile creare degli ambienti virtuali, all'interno dei quali è possibile operare senza avere impatti sul resto della distribuzione installata sul sistema. L'installazione di OpenCV, TensorFlow e Keras sul Raspberry Pi può infatti condurre facilmente a situazioni in cui non si riesce a procedere a causa [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2676 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.


Grazie davvero per questo articolo,
era proprio quello che cercavo per iniziare a sperimentare con questi tool!
Non ho ancora seguito tutti i passi, ma intendo farlo al più presto; anzi, a tal proposito, volevo chiedere se secondo te la procedura si differenzia molto per un Raspberry 4 nuovo nuovo, se posso trovare intoppi o cose molto diverse.
Saluti.
Ciao, l’articolo parla di come addestrare la rete neurale per il rilevamento di oggetti con TensorFlow? Mi spiego meglio, l’articolo dice come addestrare la rete neurale con dei modelli in grado di poter riconoscere degli oggetti specifici?
Ti scrivo perché non sono abbonato e prima di spendere 40€ voglio essere sicuro che l’articolo parli di ciò che mi serve!
Articolo molto interessante, anche se forse la parte di test del modello avrebbe potuto essere un po’ più dettagliata. Manca ad esempio la discussione del tempo che impiega un Raspberry Pi ad analizzare una immagine, una cosa fondamentale per un sistema embedded che dovrebbe lavorare in tempo reale.
In ogni caso, comunque, poter utilizzare un computer da 50 euro per cose come queste è veramente strabiliante.
Un altro microsistema che meriterebbe ulteriori approfondimenti è il NVIDIA jetson Nano che è più o meno un Raspberry Pi con una GPU di buon livello integrata sulla scheda madre.
La presenza della GPU lo rende particolarmente adatto all’analisi delle immagini, che richiede calcoli relativamente semplici ma fortemente paralleli. In teoria questo SBC dovrebbe essere in grado di effettuare da solo anche la fase di pretraining, almeno per modelli relativamente semplici.
Qualcuno ha qualche idea o esperienza in proposito?
Articolo molto interessante e che mi ha fatto scoprire le altre potenzialità di raspberry pi. L’autore spiega bene tutti i passaggi da seguire per poter installare il software necessario. Questo è un argomento molto nuovo per me ma sicuramente da approfondire.
Un enorme ringraziamento per questo interessantissimo articolo,
Avevo da tempo il desiderio di sperimentare nel campo del deep learning e trovo devvero “incoraggiante” questo howto per compiere i primi passi.
Chissà che non conduca a un’approfondimento anche professionale.