
Questo semplice tool offerto da fujitsu facilita la programmazione dei registri relativi ai controller CAN presenti nella propria gamma di microcontrollori a 16 e 32 bit. L’utility fornisce un comodo ausilio nella determinazione dei valori relativi agli id e soprattutto alla complessa temporizzazione dei bit del protocollo can.
Il bus CAN
Il protocollo CAN (Controller Area Network) è stato introdotto verso la fine degli anni ‘80 dalla Robert Bosch GmbH nel settore automotive, con lo scopo di consentire lo scambio di dati tra diverse centraline ed unità di controllo presenti sui veicoli. Le particolari caratteristiche del protocollo hanno poi fatto sì che si diffondesse anche nel campo dell’automazione industriale. Questi fattori hanno portato anche alla standardizzazione del CAN da parte della ISO e della SAE. Il bus CAN in effetti ingloba una notevole quantità di elementi innovativi rispetto ad altri bus di campo e molte soluzioni particolarmente intelligenti ed efficaci. Le caratteristiche distintive di questo protocollo sono la sua particolare immunità ai disturbi e la capacità di gestire o tollerare gli errori a diversi livelli, e il fatto di non essere basato su un modello di comunicazione punto-punto, come invece accade nella maggior parte dei bus di campo. Entrambe queste caratteristiche in effetti rispecchiano l’ambito d’applicazione nativo, ma si sono rivelate particolarmente utili anche in altri settori.
Il protocollo CAN può essere utilizzato su diversi livelli fisici, ciascuno dei quali garantisce prestazioni e costi differenti. La trasmissione è sempre di tipo seriale, con velocità fino ad 1Mbps, ma il mezzo utilizzato può essere una coppia differenziale su doppino intrecciato (tipo RS-485), un singolo filo più una massa comune (questa soluzione è quella utilizzata in campo automotive), o perfino delle interfacce ottiche o soluzioni proprietarie. Come accennato una delle caratteristiche principali del protocollo CAN è che esso non utilizza una modalità di comunicazione punto-punto, in cui cioè una sorgente invia un messaggio ad un destinatario preciso, identificato tramite un indirizzo unico (come avviene praticamente in tutti i protocolli seriali multi-agente). Nel protocollo CAN invece le trasmissioni sono inviate in “broadcast” a tutti gli agenti, ma l’indirizzamento avviene in base al contenuto del messaggio. In altri termini tutti i nodi presenti sul bus ricevono i messaggi, ma scelgono di utilizzarli o meno in base alla tipologia del loro contenuto, che è specificato da un campo presente all’interno del frame. Ad esempio su un’automobile un sensore potrebbe trasmettere sul bus i dati rilevati relativi alla velocità dell’auto, che verrebbero ricevuti da tutti gli apparati ma utilizzati soltanto dal tachimetro e dal controllo di stabilità o frenata. La struttura dei frame DATA, che sono la tipologia di messaggi più frequentemente utilizzata è mostrata in figura 1.
Figura 1: struttura dei frame DATA del bus CAN.
Il campo “Arbitration”, che può avere una lunghezza di 11 bit o di 29 nel caso di frame “extended”, viene utilizzato per determinare la priorità di accesso al bus, ma svolge contemporaneamente anche altre funzioni: esso identifica in maniera univoca il nodo trasmittente e quindi può essere utilizzato per eseguire il filtraggio dei messaggi, e può quindi anche indicare la tipologia del messaggio stesso (il contenuto). L’arbitraggio del bus CAN rappresenta indubbiamente uno degli aspetti più originali ed importanti nell’ottica del funzionamento efficiente del protocollo. Esso sfrutta il fatto che i dispositivi sono collegati nel bus in modo da avere un comportamento tipo “wired-AND”, cioè in cui è sufficiente che un nodo imponga un livello 0 sul bus per forzarlo a questo livello indipendentemente dal valore imposto dagli altri nodi. L’altro fattore sfruttato è che ciascun dispositivo è capace di leggere il valore presente nel bus anche durante la trasmissione. In pratica i dispositivi che hanno dati pronti iniziano a trasmettere assieme quando il bus si libera, e impongono inizialmente gli stessi valori sul bus (la prima parte del frame è uguale per tutti i dispositivi). Mentre viene trasmesso il campo Arbitration succederà che per qualche bit alcuni dispositivi imporranno un livello 0, mentre altri un 1. Dal momento che il bus assumerà il valore 0, i dispositivi che hanno tentato di impostare un 1 si accorgono di avere perso la contesa e smetteranno di trasmettere. Il dispositivo che rimarrà in trasmissione alla fine sarà quello col valore più basso del campo Arbitration. Questa situazione è illustrata in figura 2.
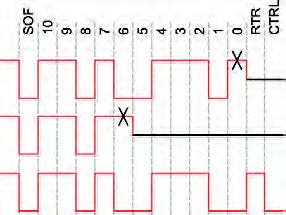
Figura 2: esempio di arbitraggio nel bus CAN.
La grande efficienza di questo meccanismo risiede nel fatto che, a differenza di quanto avviene con altri metodi di accesso, in questo caso non occorre sprecare tempo per la fase di contesa (le trasmissioni avvengono in continuazione in pratica), e non si verificano collisioni distruttive che richiederebbero una nuova contesa ed una ritrasmissione.
La temporizzazioni dei bit
Data la particolarità del metodo di arbitraggio, la natura a pacchetti della comunicazione ed i requisiti di robustezza del protocollo, la sincronizzazione dei bit riveste un ruolo fondamentale. Per questo motivo il protocollo impone alcuni particolari meccanismi per definire in maniera molto precisa e flessibile la temporizzazione dei bit. Oltre la precisione infatti anche la flessibilità è un requisito fondamentale, dal momento che al variare del l’estensione della rete e della frequenza di clock dei singoli nodi, deve essere possibile variare in maniera fine e precisa le temporizzazioni dei bit, su cui tra l’altro il massimo errore tollerato è dell’ordine dell’1%. Lo standard prevede che il tempo di un singolo bit sia diviso in alcune zone e misurato in “quanti” temporali, il cui numero può essere variato in funzione del bit rate e dei parametri di sincronizzazione desiderati. La suddivisione temporale del bit secondo lo standard è mostrata in figura 3.
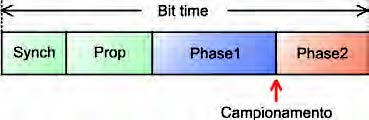
Figura 3: suddivisione temporale del tempo di bit
secondo il protocollo CAN.
Il primo settore (Synch) è lungo un quanto ed è quello in cui viene rilevata la prima transizione sul bus, il secondo settore è previsto per tenere in conto il ritardo di propagazione dei segnali lungo il bus (che può variare in base alla lunghezza ed alla natura dello stesso), gli altri due settori (Phase1 e Phase2) invece fungono da margini e permettono di decidere con precisione l’istante di campionamento (che è collocato tra i due intervalli). L’impostazione del tempo di bit richiede quindi di scegliere il valore del quanto temporale, che in genere è ottenuto dividendo la frequenza di clock utilizzata dal controller CAN tramite un prescaler, e la larghezza dei diversi intervalli. Dal momento che questi parametri devono essere messi in relazione con il bit rate desiderato, con il valore degli altri parametri e con i vincoli imposti dallo standard, la determinazione di un insieme di valori corretti può risultare difficile o comunque laboriosa. Ad esempio, se si dispone di un clock a frequenza relativamente bassa, e si desidera un bit rate elevato, si disporrà di pochi quanti da distribuire sui vari intervalli, e questo comporterà una maggiore difficoltà nella scelta dell’istante di campionamento e probabilmente un erro re percentuale maggiore di quello consentito. Se al contrario si seleziona un valore basso per il prescaler, il numero di quanti per segmento potrebbe superare quelli gestibili dal controller. E’ utile quindi automatizzare la fase di scelta, o quantomeno l’analisi delle diverse possibilità. Nel microcontrollori Fujitsu si ha una difficoltà ulteriore: gli intervalli di tempo su cui è possibile intervenire non sono gli stessi di quelli previsti dallo standard, ma sono quelli mostrati in figura 4.
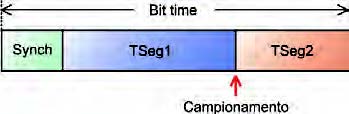
Figura 4: tempo dei bit CAN nei micro Fujitsu.
Sebbene i gradi di libertà siano gli stessi, risulta ulteriormente complicato verificare se tutti i vincoli sono rispettati. Proprio per ovviare a questa difficoltà è stato creato il tool Bitmixer.
Bitmixer
Bitmixer è una semplice utilità (un “register wizard”) che semplifica la scelta e la definizione dei valori dei registri del controllore CAN nei micro dotati di questa periferica. Il programma dispone di due pannelli dedicati alla gestione di due parti diverse del controllore: quella relativa agli ID (campo Arbitration) e quella relativa alla temporizzazioni dei bit seriali. In entrambi i casi è possibile immettere i parametri voluti ed ottenere, dopo eventuali elaborazioni o scelte, dei segmenti di codice ANSI C da copiare nei propri programmi in cui il valore calcolato per i registri è espresso come macro (#define).
Scelta degli ID
La codifica degli ID (che possono essere usati sia per la trasmissione che per il filtraggio) non presenta di per se particolari difficoltà, in quanto la scelta e codifica dei valori risulta piuttosto diretta. Tuttavia il fatto di dovere riportare ID espressi nel formato richiesto dai micro Fujitsu ed esprimere il tutto in decimale o esadecimale può risultare un operazione scomoda, noiosa e soggetta ad errori se eseguita manualmente. Gli ID da inserire nei registri infatti presentano i bit disposti nell’ordine inverso rispetto alla notazione usata normalmente, per cui per ottenere il valore corretto è necessario convertire il numero dell’ID in binario, ribaltare i bit da sinistra a destra, e riconvertire in decimale o esadecimale. Questa operazione deve essere ripetuta per tutti gli ID usati. Bitmixer semplifica molto questo lavoro in quanto mette a disposizione una semplice interfaccia, visibile in Figura 5, che permette di inserire gli ID nel formato preferito (decimale, esadecimale o binario) e convertirli nel formato dei registri, o viceversa. Il programma permette anche di selezionare la larghezza degli ID tra il formato CAN 2.0A ad 11 bit e quello esteso a 29 bit (2.0B). Inoltre, dal momento che spesso vengono usati ID contigui o spaziati di intervalli regolati, è possibile generare automaticamente un certo numero di valori, indicandone il numero e l’intervallo di incremento. L’output del programma, cioè la dichiarazione del valore dei registri, è presentato in un casella di testo in ANSI C, che è possibile copiare ed incollare sul proprio codice.
Scelta delle temporizzazioni
Il pannello di Bitmixer dedicato alle temporizzazioni è un po’ più complesso e ricco di opzioni (figura 5).
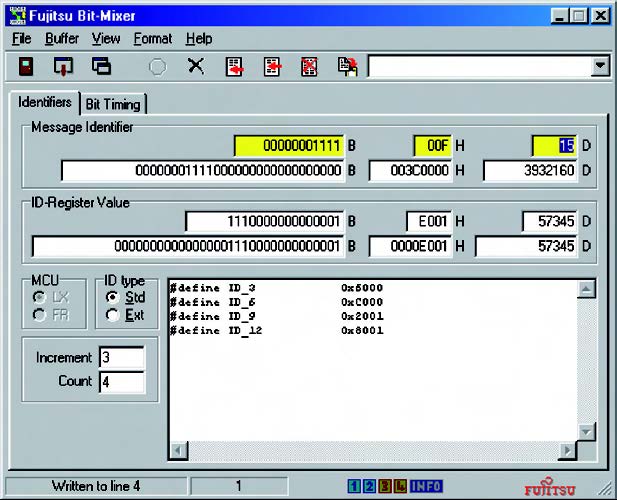
Figura 5: pannello di Bitmixer per l’impostazione degli ID
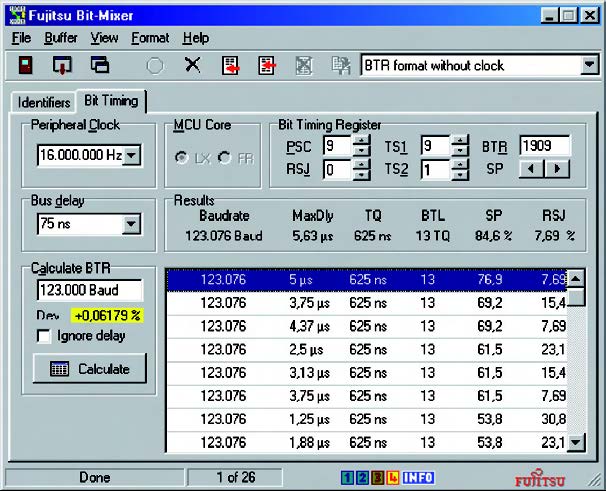
Figura 6: pannello di Bitmixer per l’impostazione del tempo di bit.
In questo caso infatti è necessario non solo determinare i valori appropriati secondo il protocollo, ma determinare anche come esprimerli utilizzando i diversi parametri implementati dai micro Fujitsu. In questo caso quindi il software si rivela uno strumento estremamente importante. Il funzionamento è molto semplice: forniti alcuni dati in ingresso relativi alle impostazioni ed alle caratteristiche volute, il programma è in grado di calcolare e presentare tutte le combinazioni di valori da inserire nel registro BTR per ottenere le prestazioni volute. I valori presi in ingresso sono quelli del clock di sistema, il bit rate desiderato ed il massimo ritardo di propagazione previsto per il bus. A partire da questi valori, premendo il pulsante “Calculate”, il programma genera una serie di possibili opzioni per il valore del registro. Per ciascuna possibile combinazione trovata viene riportato il valore esatto di bit rate, il massimo ritardo di propagazione consentito, il valore del quanto di tempo, la lunghezza del bit in termini di numero di quanti, la posizione in percentuale del tempo di bit in cui viene eseguito il campionamento e la percentuale relativa all’intervallo di ri-sincronizzazione. Una volta selezionato la riga che presenta i valori più soddisfacenti per le specifiche del progetto, il programma mostra il valore del registro BTR e quello dei suoi sottocampi. A questo punto è possibile modificare manualmente i singoli elementi in modo da ottimizzare il risultato trovato: le variazioni provocate da ciascun cambiamento vengono mostrate in tempo reale nel pannello “Results”. Una volta trovate le migliori impostazioni è possibile conf ermare e produrre così la linea di codice con la definizione del valore del registro, che viene riportata nella casella di testo nel pannello relativo agli ID o nella clipboard.
