
Se per un programmatore di media esperienza la gestione di un processore “single-core” non rappresenta un problema, le cose possono complicarsi anche notevolmente nel caso in cui i “core” da gestire siano più di uno. In questo articolo della Rubrica Firmware Reload, all'interno della quale sono inclusi gli articoli della rivista cartacea Firmware, affrontiamo in maniera esaustiva questa complessa materia.
ASPETTI FONDAMENTALI DELL’ESECUZIONE MULTICORE
Prima di ogni altra considerazione, è necessario analizzare i modelli di elaborazione parallela dei dati. Uno dei primi passi per eseguire la mappatura di un’applicazione su un processore multicore è quello di identificare il parallelismo e selezionare il modello di processamento che meglio si adatta al caso specifico. I due modelli principali sono: Master/Slave e Data Flow. Il primo probabilmente si intuisce più facilmente che cosa sia, è una modalità in cui un core controlla l’assegnamento su tutti gli altri mentre il secondo caso somiglia molto ad una pipeline, ovvero si segue l’esecuzione del programma nel suo flusso. Vediamoli meglio. Il primo modello rappresenta un controllo centralizzato con esecuzione distribuita, per cui si ha un core che svolge il ruolo di controllore ed è responsabile per la programmazione e lo scheduling di tutti i thread e dell’indirizzamento nei vari core slave. Le applicazioni che meglio si adattano a questo modello sono costituite da piccoli thread indipendenti che possono essere facilmente indirizzati su singoli core.
Questo genere di software spesso contiene una grande quantità di codice di controllo e spesso accede alla memoria in ordine casuale. Di solito, le applicazioni che vengono eseguite secondo questo modello girano su sistemi operativi di alto livello come Linux e che sono potenzialmente già pronti per l’esecuzione multi-thread. La sfida per le applicazioni che utilizzano questa modalità è il bilanciamento real-time del carico di lavoro perché l’attività dei thread, e la loro attivazione, può essere casuale. L’esecuzione di ciascuno può avere anche requisiti particolarmente differenti ed anche questo deve tenere in conto il core principale: deve essere disponibile una lista di tutti i core free e disponibili per eseguire tutti i compiti per ottenere il miglior risultato dal parallelismo. Per raccontare tutto questo tramite un’immagine, utilizziamo la Figura 1.
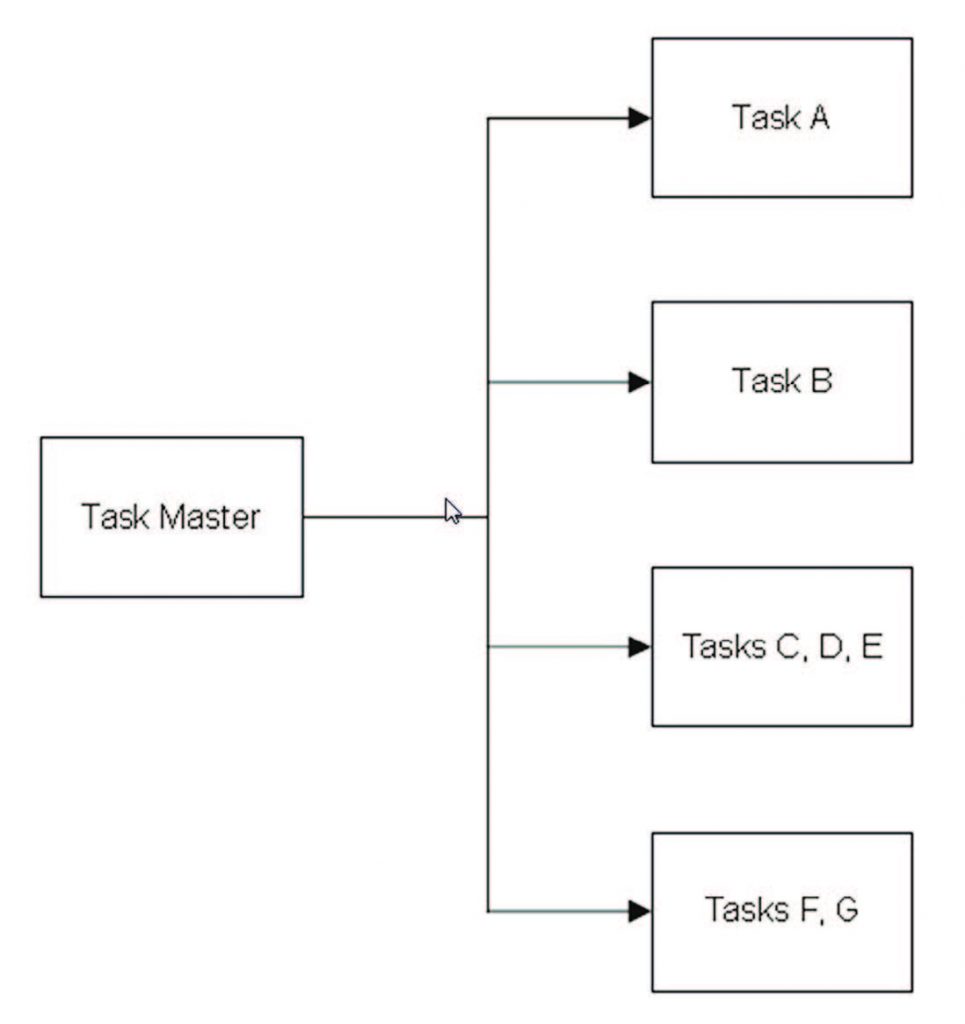
Figura 1: Esempio di gestione multitask
Dal momento che uno o più task sono in esecuzione su altrettanti core, è assolutamente indispensabile il cosiddetto “task alignment”, che si può raggiungere utilizzando messaggi tra core. Essi sono costituiti da informazioni di trigger ed effettuano il controllo dell’esecuzione. Per quanto riguarda il modello Data Flow, invece, esso rappresenta una modalità di controllo e di esecuzione distribuita; ciascun core elabora un blocco di dati utilizzando vari algoritmi e successivamente i dati vengono “passati” ai core che eseguiranno le operazioni successive. Si tratta, in buona sostanza, di una sorta di catena di montaggio. Le applicazioni che tipicamente vengono eseguite secondo questo modello contengono componenti dedicati ad importanti ed onerose applicazioni computazionali, e di solito si tratta del modello funzionale di sistemi operativi real-time, in cui la latenza è un parametro assolutamente critico. La sfida, in questo genere di applicazioni, è proprio il partizionamento sia delle istruzioni sia del flusso di dati attraverso il sistema. Eccone un esempio esplicativo in Figura 2.
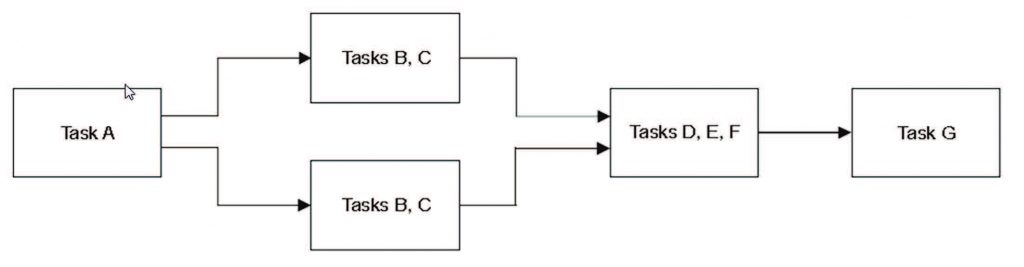
Figura 2: Partizionamento delle istruzioni e del flusso dati
Un’applicazione che si presta bene a questo modello è il layer fisico di un protocollo di comunicazione, il quale traduce le richieste di comunicazione dal data link layer in operazioni specifiche per l’hardware, che hanno effetti sulla trasmissione oppure sulla ricezione di segnali elettrici. Il software implementa operazioni di elaborazione sul segnale anche complesse, utilizzando istruzioni intrinseche che si avvantaggiano proprio del meccanismo di parallelismo. In questo panorama non possiamo non dedicare alcune righe al modello OpenMP. Si tratta di un “Application Programming Interface” (API) per lo sviluppo di applicazioni multi-threaded in C/C++ per architetture a memoria condivisa parallela (meglio nota come SMP ovvero “Shared-Memory Parallel”).
Si tratta, di fatto, di uno standard che specifica come le operazioni in questo genere di sistemi devono essere svolte, ed offre diversi vantaggi dal punto di vista della programmazione perché è molto semplice da utilizzare e veloce da implementare: una volta che il programmatore identifica le regioni parallele ed inserisce il costrutto OpenMP più opportuno, il compilatore ed il sistema eseguono conti che definiscono il resto dei dettagli. L’API rende semplice un’eventuale operazione di scalatura tra i core e pertanto se si passa ad un processore con un numero maggiore oppure minore di core disponibili, questo non rappresenta affatto un problema. Quando un programmatore ha a disposizione del codice sequenziale e lo vuole “parallelizzare” non è necessario creare una versione del programma totalmente nuova, dal momento che, piuttosto che fare questo, è possibile adottare un approccio incrementale in cui il programmatore può focalizzarsi sui blocchi che realizzano il parallelismo e codificarli in una volta sola. Va certamente studiata ed approfondita come un capitolo a sé stante, ma quello che è importante dire è che permette agli utenti di mantenere un codice con una struttura unificata sia nella versione sequenziale sia nella versione parallelo. Esistono diversi scenari di implementazione per dimostrare com’è facile ed utile l’OpenMP per un programmatore. Se volete approfondire, di certo il riferimento migliore è questo sito Internet: www.openmp.org.
È PARALLELA?
Serve conoscere come deve essere svolta l’esecuzione di un programma e pertanto è importantissimo identificare l’implementazione parallela. Si tratta di una sfida che deve essere affrontata con metodo: se da un lato è vero che in particolare la Texas Instruments è al lavoro per sviluppare dei tool di generazione del codice che permettano l’identificazione più semplice, è comunque necessario conoscere le modalità attraverso cui si identificano mapping, scheduling ed altri nella programmazione multi-core. Esistono pertanto:
- partizionamento
- comunicazione
- combinazione
- mapping
Il Partitioning, o partizionamento, di un’applicazione avviene in funzione dei requisiti e della complessità computazionali connessi con la stessa. Le operazioni di lettura, di scrittura e così via devono essere analizzate con attenzione per decidere come suddividere l’applicazione stessa. La maniera più semplice per effettuare una misurazione dei requisiti computazionali è quella di utilizzare il software per accogliere “timestamps”, cioè le impronte temporali, all’ingresso ed all’uscita di ciascun modulo di interesse. Utilizzando lo schedule dell’esecuzione è possibile calcolare i requisiti in termini di MIPS. Stimare l’accoppiamento di un componente caratterizza la sua interdipendenza con tutti gli altri sottosistemi coinvolti nel suo funzionamento, pertanto un’analisi del numero di funzioni oppure dei dati all’esterno di ciascun sottosistema che dipende dagli altri, può dare le informazioni necessarie. L’analisi del numero di funzioni all’interno dei sottosistemi che dipendono da funzioni oppure da dati o variabili generali, identifica il livello di dipendenza dagli altri sottosistemi. Viene anche definita la commistione dei sottosistemi che caratterizza l’interdipendenza interna ed il grado di connessione del modulo al suo interno.
Questa, se vogliamo, non è altro che una dimensione di quanto il modulo funzioni bene sulla base della cooperazione tra i vari sottosistemi. Se un singolo algoritmo deve utilizzare ogni singola funzione all’interno di un sottosistema, allora si dice che c’è un’alta coesione; al contrario, naturalmente, se diversi algoritmi utilizzano soltanto alcune funzioni, la coesione è considerata bassa. Pertanto, la suddivisione in moduli oppure in sottosistemi è un problema di ricerca dei breakpoint che rendono l’intera soluzione comunque coesa. La comunicazione, invece, riguarda sempre il funzionamento ma, per esempio, il momento in cui, dopo che i moduli software sono stati identificati nello stadio di partizione, è necessario misurare i requisiti di comunicazione tra loro. Il controllo del diagramma di flusso può permettere l’identificazione dei percorsi di controllo indipendenti che aiutano a determinare eventuali task concorrenti all’interno del sistema. I diagrammi Data Flow dovrebbero essere un ottimo strumento per determinare oggetti e dati di sincronizzazione necessari, anche perché il controllo dei diagrammi di flusso rappresenta un metodo efficace per controllare i percorsi tra moduli, specie dal punto di vista della sincronizzazione. Lo vediamo meglio con la Figura 3.
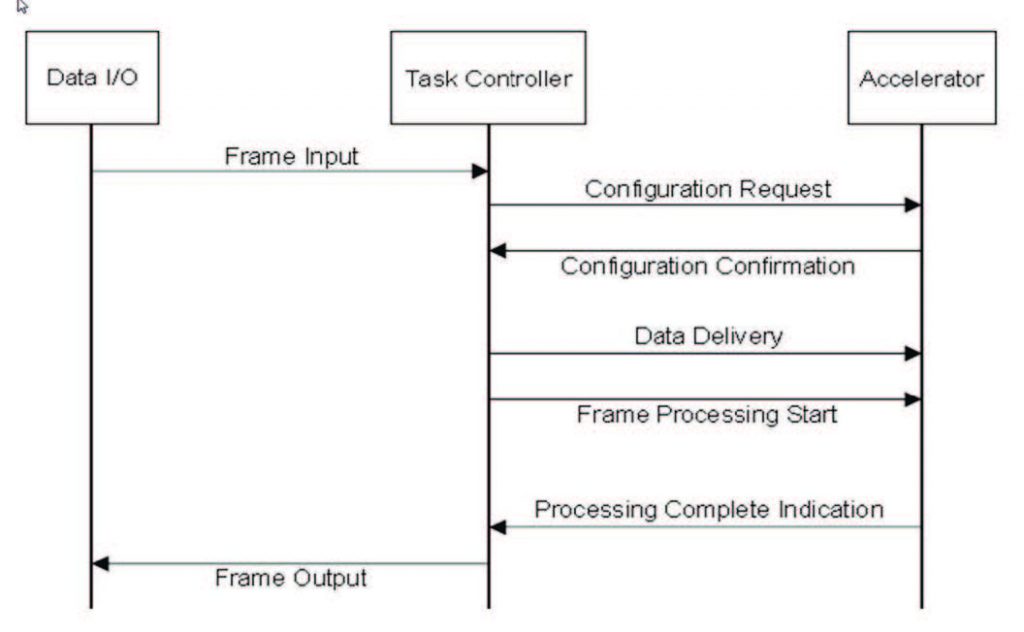
Figura 3: Data Flow
Un esempio di diagramma Data Flow lo troviamo riportato in Figura 4.
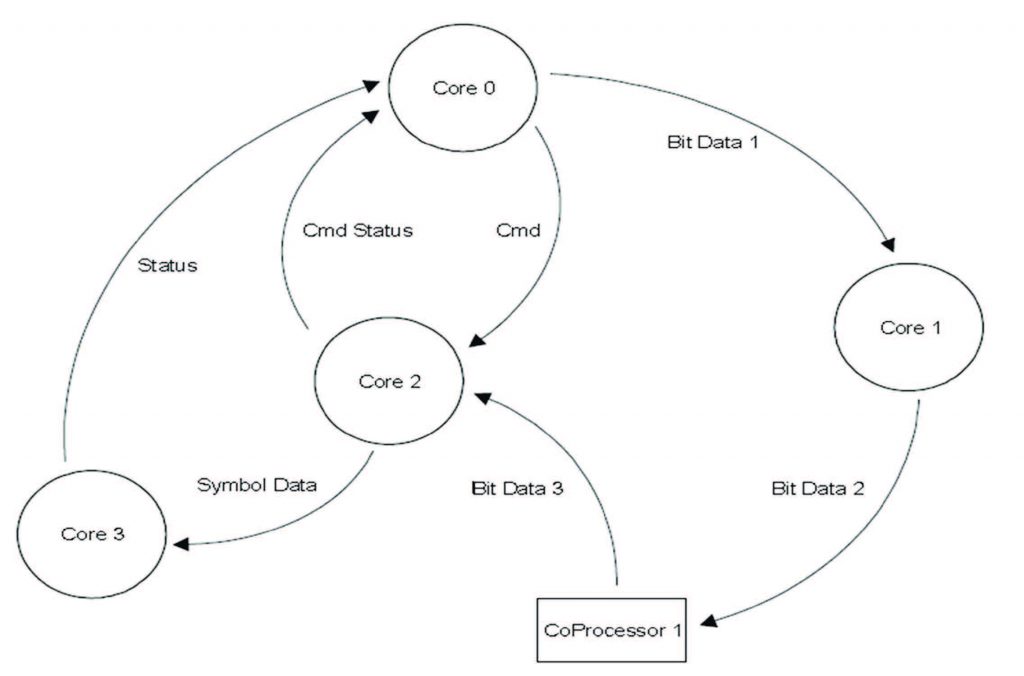
Figura 4: Data Flow Multicore
Com’è evidente dalla figura, ciascun core esegue istruzioni che sono collegate ad altre in esecuzione altrove. Questo genere di interconnessioni rappresenta l’elemento fondamentale da analizzare. Dicevamo, poi, combinazione: la fase di combinazione determina se sia utile oppure meno combinare i task che sono stati identificati nella fase di perfezionamento in maniera tale da ridurre il numero di task ancorché facendoli diventare di dimensioni più grande. In questa fase si decide, anche, se sia il caso o meno di replicare i dati e se questo possa avere degli effetti deleteri sulla velocità di esecuzione. Moduli con costi computazionali e di comunicazione molto elevati vengono decomposti in elementi più piccoli con costi individuali più contenuti. Infine, il mapping, ovvero un processo di assegnazione di moduli, task e/o sottosistemi ai singoli core. Come una vera e propria mappatura, quindi. Si tratta di un processo che conclude l’intera sequenza del partizionamento, della comunicazione e della combinazione che serve per eliminare ogni genere di problema che potrebbe insorgere nell’esecuzione dovuta all’accoppiamento tra moduli. I sottosistemi sono allocati su core differenti sulla base del modello di programmazione selezionato, come avevamo detto in precedenza. Per garantire la possibilità che ci siano comunicazioni efficaci tra processori, e quindi bassi tempi di latenza e scalatura parametrica, è importante riservare alcune delle MIPS, la memoria L2 e la banda di comunicazione al mapping.
Dedicare queste risorse renderà l’intera esecuzione più veloce ed affidabile. I processori embedded non dispongono, tipicamente, di una gerarchia nella memoria in cui esistono più livelli di memoria cache off-chip; viene preferita l’operatività in cache rispetto all’utilizzo di memorie esterne per le quali sia necessario utilizzare dell’interfaccia. Il partizionamento potrebbe richiedere ulteriori buffer di memoria, insieme alla duplicazione dei dati, per compensare quei fenomeni di latenza inter-core. Proprio per questo motivo, le performance della cache risultano fondamentali. Se si dovessero instaurare fenomeni di sviluppo, il parallelismo potrebbe rappresentare la soluzione ma un approccio “forza bruta” dei dati sulla base del numero di core disponibili naturalmente non è esattamente una scelta intelligente. Dovranno essere valutati tutti i dati in gioco, la quantità di memoria disponibile, il numero di core liberi e tutti i fattori di cui abbiamo parlato fino a questo momento per poter operare un processo di scalabilità compatibile con parametri critici dell’intero sistema. Torniamo brevemente su OpenMP perché queste API forniscono degli utili supporti rispetto alla parallelizzazione, ma resta centrale il ruolo del programmatore nell’identificare la strategia per arrivare a questo risultato. Il costrutto “omp parallel” può essenzialmente essere utilizzato per effettuare la parallelizzazione di qualunque funzione ridondante attraverso i core: supponiamo che il codice sequenziale contenga dei loop for con un gran numero di iterazioni. In questo caso, è possibile utilizzare “omp for” in OpenMP che suddivide le iterazioni in ciascun core disponibile. Naturalmente, si tratta solo di un esempio, ma che apre la strada a ben altre considerazioni.
Per leggere la prima parte dell'articolo seguire il link: La programmazione Multicore – Parte 1 | Elettronica Open Source



