
Se per un programmatore di media esperienza la gestione di un processore “single-core” non rappresenta un problema, le cose possono complicarsi anche notevolmente nel caso in cui i “core” da gestire siano più di uno. In questo articolo, ultima puntata della serie "La programmazione Multicore" della Rubrica Firmware Reload, contenente articoli della rivista cartacea Firmware, affrontiamo in maniera esaustiva questa complessa materia.
GESTIONE DELLA MEMORIA CONDIVISA
Dal momento che le risorse di sistema sono comunque limitate, è molto frequente che esse debbano essere condivise tra applicazioni e pertanto diventa critico l’interesse verso un protocollo uniforme che venga seguito da ciascun core all’interno del sistema. Il protocollo può dipendere dal set di risorse che vengono condivise ma le regole restano comuni. Tanto per iniziare, esistono le cosiddette “Global Flag”, ovvero segnalatori utili per ciascun core nel caso di modello single-threaded. Se c’è una risorsa che dipende da un’azione e dal suo completamento, si utilizzano i flag globali per effettuare un controllo molto semplice. Se sono basate su strutture software, possono essere utilizzate in ambienti multicore anche se questo non è particolarmente consigliato. Altra soluzione sono gli “OS Semaphore”. Tutti i sistemi che operano in maniera Multitasking li utilizzano per la gestione delle risorse condivise e la sincronizzazione dei task. Se siamo su core singolo, naturalmente, questo sistema risulta praticamente sovrapposto al primo dal momento che queste variabili risulterebbero globali. Esistono anche gli “Hardware Semaphore”, che sono necessari solo nel caso di gestione tra core differenti. Non c’è alcun vantaggio nell’utilizzarli su core singoli dal momento che esistono meccanismi interni al sistema operativo che causano un overhead indubbiamente più basso. Se i core sono più di uno, allora il supporto hardware è essenziale per il corretto funzionamento e ci sono algoritmi software che possono essere utilizzati insieme con la memoria condivisa ma rischiano di richiedere cicli di sistema non indispensabili.
Che sia memoria condivisa o meno, in ogni caso, dal momento che stavamo facendo delle considerazioni sulla velocità, sulla latenza e sulle prestazioni più in generale, è il momento giusto di esprimere un parere tecnico: per rendere più veloce la lettura dei programmi, dei dati da dispositivi esterni, per esempio memorie, magari della generazione DDR3, o che provengano da memorie condivise L2, ciascun core sarà dotato di un set di registri di pre-fetch dedicati. Essi vengono utilizzati per effettuare un pre-caricamento nella memoria da quella esterna prima che sia richiesto dal core. Il meccanismo di pre-fetch stabilisce la direzione di transito dei dati, la lettura della memoria esterna ed il caricamento dei dati e del programma che potrebbero certamente essere letti nel futuro. Ciò si traduce, di fatto, in una più ampia larghezza di banda. Ciascun core può controllare il pre-fetch e la cache separatamente. Per chiarirne le possibilità, in Figura 1 è illustrato un diagramma a blocchi abbastanza esplicativo.
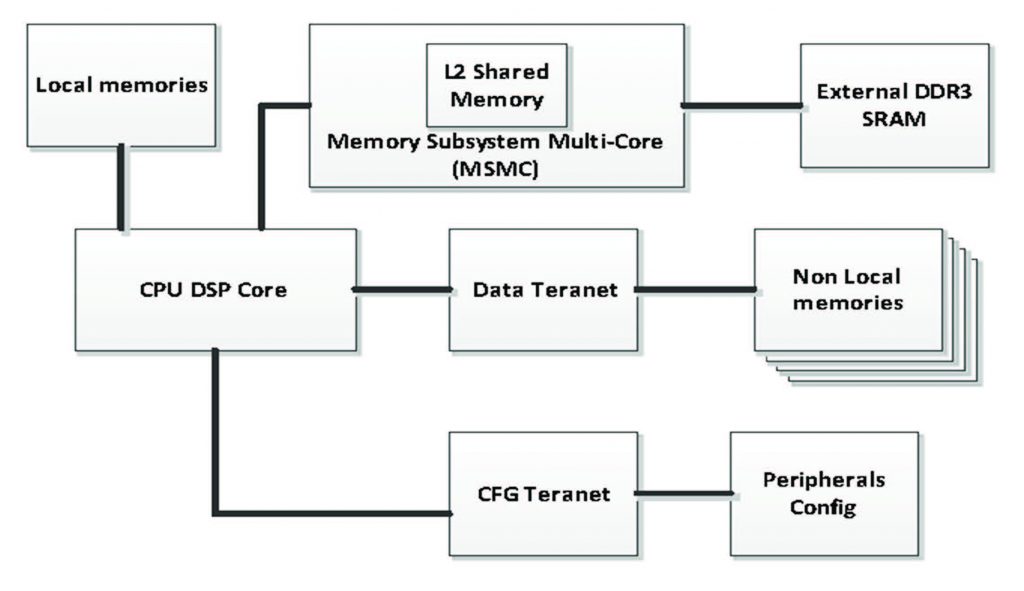
Figura 1: Schema a blocchi del meccanismo di pre-fetch
IL DEBUG
Come sempre, non tutto va bene al primo colpo. C’è sempre la necessità di fare debug e di capire che cosa è andato storto; sui microcontrollori di cui abbiamo parlato questa possibilità esiste e ci sono diversi strumenti previsti. Essi sono sia hardware sia software, e possono essere utilizzati sia a runtime sia per risolvere uno specifico problema, sia grazie all’emulazione hardware sia grazie alla strumentazione software. Si tratta di analizzare, tra gli altri, trace log, API call log e statistics log. Senza considerare DMA transaction log, Event log e customer Data log. Tutto questo viene poi accompagnato dalla possibilità di esaminare grafici funzionali che diano informazioni su differenti scenari mostrando le interazioni tra core distinti.
CONCLUSIONI
Questa serie di articoli è stata un lungo viaggio attraverso la programmazione in sistemi multicore. Lo scopo è stato chiaramente quello di provare a fornirvi tutti gli elementi di base e gli strumenti fondamentali per cominciare ad analizzare le metodologie operative e cercare di prendere confidenza con gli strumenti hardware e software. I processori di cui abbiamo parlato offrono performance di alto livello grazie ad architetture di memorie molto efficienti, una gestione delle risorse condivise molto affidabile e tutta una serie di strumenti che possono permettere lo studio professionale e l’analisi completa del funzionamento. Tutto questo in un ambiente di sviluppo che trasforma i System-On-a-Chip in sistemi relativamente semplici da gestire.
Leggi anche le puntate precedenti
La programmazione Multicore – Parte 1 | Elettronica Open Source
La programmazione Multicore – Parte 2 | Elettronica Open Source
La programmazione Multicore – Parte 3 | Elettronica Open Source



