
Nel corso degli ultimi anni abbiamo assistito a un’evoluzione vertiginosa delle tecnologie impiegate per la realizzazione dei microprocessori. Termini come multi-core, pipeline, hyper-threading, superscalare, tanto per citarne alcuni, sono diventati comuni e familiari. Siamo sicuri di avere compreso bene il loro significato?
Obiettivo di questo articolo è cercare di fare chiarezza sulla terminologia tecnica che contraddistingue le caratteristiche e le funzionalità offerte dagli attuali microprocessori, cioè quelli che utilizziamo tutti i giorni e che equipaggiano i nostri personal computer, cellulari e altri dispositivi elettronici a elevata integrazione.
LA PIPELINE
Fino a qualche anno fa, i microprocessori erano progettati per eseguire le istruzioni secondo una regola prettamente sequenziale: una volta completata l’istruzione corrente si passava a quella successiva, secondo l’ordine stabilito dal flusso di programma. Da un po’ di tempo a questa parte, tuttavia, le cose funzionano in un modo un po’ diverso: i processori attuali, infatti, sono in grado di eseguire diverse istruzioni contemporaneamente, anche se ciascuna di esse viene eseguita in modo parziale. Si consideri un’istruzione macchina generica; la sua esecuzione può essere suddivisa in cinque fasi distinte che, nell’ordine temporale di esecuzione, sono le seguenti:
- fetch – l’istruzione da eseguire viene prelevata dalla memoria in cui risiede il codice eseguibile (memoria RAM, memoria flash );
- decodifica;
- esecuzione;
- attivazione della memoria – è una fase opzionale e può non essere presente, in quanto dipende dal particolare tipo di istruzione;
- writeback – scrittura del risultato negli opportuni registri.
In figura 1 è mostrato il flusso di istruzioni riferito a un processore prettamente sequenziale.
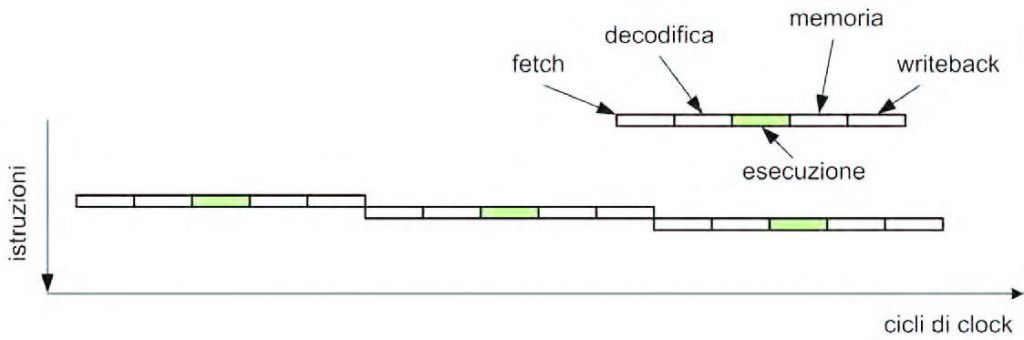
Figura 1: il flusso di esecuzione in un processore sequenziale.
Assumendo che sia necessario un ciclo di clock per ogni fase, l’esecuzione di una singola istruzione richiederebbe un totale di 5 cicli di clock (si dice anche che si ha un CPI=5, dove CPI è l’acronimo di Cycles Per Instruction). Nei processori moderni, le istruzioni vengono parzialmente sovrapposte tra di loro, nel senso che nello stesso ciclo di clock in cui viene eseguita la fase x di una certa istruzione, viene anche eseguita la fase x+1 relativa all’istruzione successiva. Il procedimento può essere esteso a n istruzioni (5 nel nostro caso), ottenendo così l’importante risultato di eseguire un’istruzione in 1 solo ciclo di clock (più propriamente si dovrebbe dire che si ottiene un CPI=1). Tutto ciò è riassunto dallo schema mostrato in figura 2, in cui viene evidenziata in verde la fase di esecuzione. Questo meccanismo è denominato pipeline, e consente di incrementare le performance del processore senza modificare la frequenza del clock applicato alla CPU (nel nostro caso l’incremento risultante è pari a un fattore 5x). I primi processori RISC, come ad esempio il MIPS R2000 (basato sull’architettura MIPS definita alla Stanford University) e lo SPARC (largamente utilizzato sulle workstation di Sun Microsystems) erano entrambi equipaggiati con una pipeline a 5 stadi, del tutto simile a quella appena descritta. Le macchine RISC sono naturalmente predisposte a implementare un meccanismo di pipeline, poiché le loro istruzioni operano soprattutto sui registri, e la maggior parte delle istruzioni è eseguita in un solo ciclo di clock. Per contro, altri processori della stessa epoca (come l’Intel 80386 o il VAX) utilizzavano un meccanismo di esecuzione delle istruzioni prettamente sequenziale. Il risultato è che uno SPARC operante alla frequenza di 20 MHz era più performante di un 80386 con clock a 33 MHz.
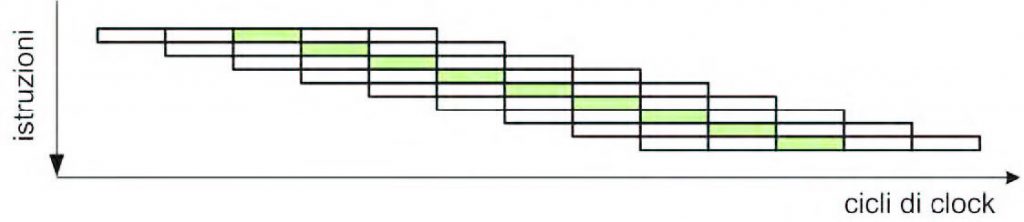
Figura 2: il flusso di esecuzione in un processore “pipelined”.
SUPERPIPELINE
La pipeline classica presenta una limitazione non trascurabile: per sua natura, infatti, la frequenza di clock (o meglio, il periodo di clock) è limitata dalla durata dello stadio più lungo della pipeline. In altre parole, il periodo di clock non può essere inferiore al “rettangolino” di lunghezza maggiore tra i 5 che compongono un’istruzione (si faccia riferimento alle precedenti figure). Per ovviare a questo inconveniente, con l’obiettivo di spingere sempre più verso l’alto le performance ottenibili, si è pensato di suddividere ciascuna fase (soprattutto quelle più lunghe) in più sottofasi, ottenendo quella che viene denominata una “superpipeline”. Si osservi la figura 3: l’esecuzione di ciascuna istruzione richiede ora un numero maggiore di cicli di clock (aumenta la cosiddetta latenza), ma il processore, che ora funzionerà ad una frequenza di clock superiore, sarà comunque in grado di completare un’istruzione in un singolo ciclo. Poiché ora vi sono più cicli per secondo, il processore sarà in grado di eseguire un numero maggiore di istruzioni al secondo, e perciò sarà La superpipeline è stata introdotta per la prima volta sul processore Alpha, lo stesso che equipaggiava i server utilizzati da uno dei primi motori di ricerca Internet, AltaVista di Digital Equipment Corporation. Leggendo le specifiche di vari tipi di processori, è facile costatare come le pipeline di lunghezza maggiore siano utilizzate soprattutto da macchine con architettura x86: il motivo è che tali processori, a differenza dei RISC, hanno istruzioni più complesse e quindi richiedono un numero maggiore di cicli di clock per la loro decodifica (il Pentium 4E aveva ad esempio una pipeline a 31 stadi contro i soli 8 dell’ARM Cortex-A9).
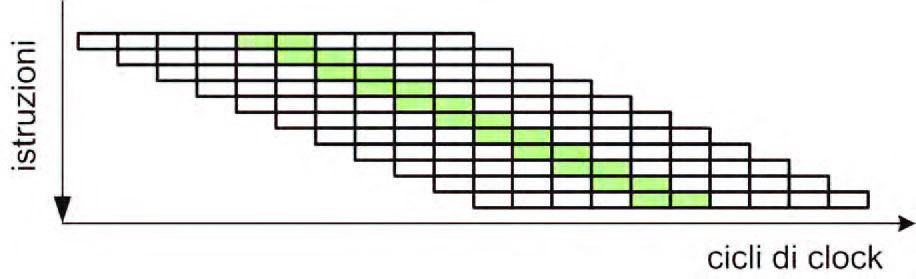
Figura 3: la superpipeline
ARCHITETTURA SUPERSCALARE
L’architettura superpipeline può, sotto certi aspetti, essere assimilata a un insieme di diverse unità funzionali, ciascuna con una propria attività da eseguire. Si potrebbe perciò essere tentati di estendere ulteriormente questo concetto e fare eseguire al processore più istruzioni, in parallelo, ciascuna da una propria unità funzionale. Non solo, poiché ora vi sono delle pipeline indipendenti per ogni unità funzionale, esse possono anche avere lunghezza differente; in questo modo, le istruzioni più semplici possono essere completate in minore tempo. Un’unità funzionale potrebbe ad esempio essere riservata per operazioni con numeri interi, una per operazioni con numeri in virgola mobile e un’altra ancora per le operazioni in memoria. Nei casi reali, i processori dispongono di più unità funzionali per operazioni dello stesso tipo, sono ad esempio in grado di eseguire due istruzioni su interi per ciclo. In figura 4 è mostrato un esempio di architettura superscalare riferita a un processore in grado di eseguire 3 istruzioni per ogni ciclo (CPI=0,33).
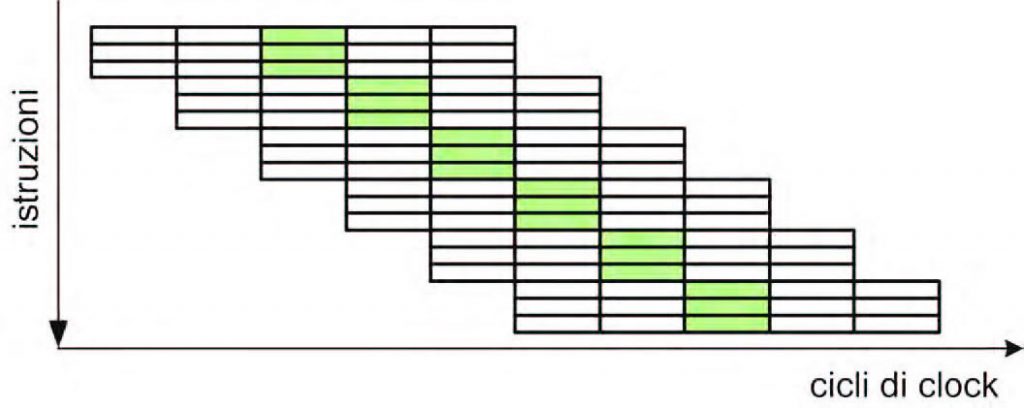
Figura 4: architettura superscalare.
SUPERPIPELINE-SUPERSCALARE
Combinando le due architetture si ottiene un processore superscalare con una superpipeline nello medesimo tempo, come visibile in figura 5. Più in generale, possiamo dire che i processori di ultima generazione sono proprio di questo tipo, e perciò vengono denominati per semplicità superscalari.
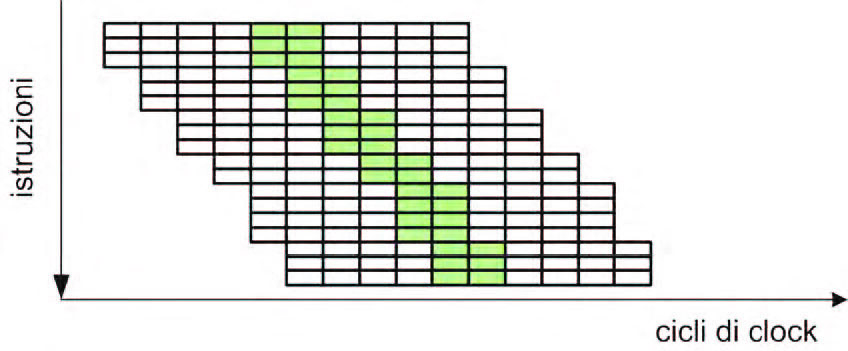
Figura 5: architettura superscalare con superpipeline.
I PROCESSORI VLIW
Sono processori nei quali il set di istruzioni viene espressamente progettato per consentire l’esecuzione parallela di gruppi di istruzioni. Con questa soluzione, adottabile quando non vi siano da rispettare vincoli di compatibilità all’indietro, le istruzioni sono definite come raggruppamenti di sottoistruzioni, e pertanto ne derivano istruzioni relativamente lunghe (spesso superano i 128 bit di lunghezza). Da qui il nome VLIW (Very Long Istrunction Word) con il quale sono indicati questi processori. La maggior parte dei processori VLIW non esegue alcun controllo di dipendenza tra le istruzioni, e non esiste alcun altro modo di mettere in attesa un’istruzione (ad esempio per attendere la disponibilità di un dato dalla memoria) se non mettendo in stallo tutto il processore. Ne consegue che dovrà essere il compilatore a farsi carico di inserire opportunamente dei cicli di attesa tra le istruzioni che sono dipendenti tra loro. Ciò avviene tramite l’aggiunta di opportune istruzioni NOP, se necessario. Il compilatore per un processore VLIW è perciò di complessità maggiore rispetto a quello richiesto da un’architettura superscalare. Esempi pratici di processori VLIW sono i DSP della serie C6X di Texas Instruments, il Transmeta Crusoe (largamente usato per dispositivi mobili e nei DVD player), e l’Intel Itanium (architettura I64). In figura 6 è mostrato il flusso di esecuzione riferito a un ipotetico processore VLIW.
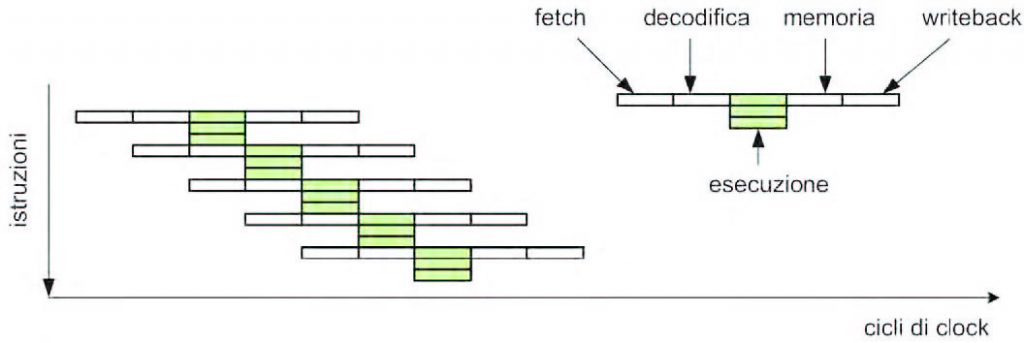
Figura 6: flusso di esecuzione di un processore VLIW.
IL CONCETTO DI LATENZA
Sulla base dei concetti visti finora, sembrerebbe possibile estendere a proprio piacimento le dimensioni sia della pipeline sia dell’architettura superscalare. Nella realtà, tuttavia, ciò non può avvenire per il motivo che ora vedremo. Si consideri anzitutto la seguente coppia di istruzioni in un linguaggio ad alto livello (ad esempio il C):
r = x * y;
s = r + z;
La prima osservazione che possiamo fare è che esiste una dipendenza diretta tra le due istruzioni, nel senso che la seconda utilizza come argomento una variabile che è assegnata nell’istruzione precedente. Non solo, possiamo anche osservare come la variabile in oggetto (r) sia assegnata tramite un’operazione di moltiplicazione. Ciò costituisce un problema, perché la moltiplicazione è un’operazione lenta (richiede diversi cicli di clock per essere portata a termine) e pertanto la seconda istruzione deve attendere il completamento di questa moltiplicazione prima di poter essere eseguita (o meglio, prima di raggiungere la fase di esecuzione). Il processore sarà pertanto costretto a mettere in attesa la seconda istruzione fino a quando il risultato della precedente istruzione non è disponibile. Si definisce come latenza il numero di cicli di clock compresi tra l’istante in cui un’istruzione raggiunge la fase di esecuzione e l’istante in cui il risultato è reso disponibile per l’utilizzo da parte di altre istruzioni. Maggiore è la profondità della pipeline, maggiore sarà anche la latenza. Questo è un motivo serio per cui la profondità della pipeline non viene mai spinta oltre certi valori (tipicamente, la latenza dei processori attuali varia da un minimo di un ciclo per le operazioni sugli interi, a 3-6 cicli per le addizioni in virgola mobile, fino a circa 12 cicli per la divisione tra interi).
PREDIZIONE DEI BRANCH
Questo è un altro concetto che complica la vita alle pipeline. Consideriamo la seguente porzione di codice:
if (s < 1000) w = s * t;
else
w = s - 1000;
Samo ora in presenza di un branch, e il flusso di programma può potenzialmente, a run-time, entrare nel ramo if oppure in quello else. Come fa il processore a mantenere piena la pipeline di istruzioni se a priori non sa quale ramo verrà percorso dal codice? La risposta è molto semplice: il processore prova a indovinare quale sarà il ramo percorso; in altre parole, procede per tentativi. Ad esempio, si supponga che il ramo scelto dal processore sia quello corrispondente all’if. Verranno in questo caso processate le istruzioni macchina associate al ramo if, ma non verrà eseguito il writeback delle stesse in modo tale che, nel caso la predizione si rivelasse errata, sia possibile eseguire il codice del ramo else. Se la predizione fatta dal processore sarà rispettata, il branch verrà eseguito in modalità full-speed (massima efficienza); se invece essa si rivelerà errata, il processore scarterà le istruzioni corrispondenti al ramo non percorso, e dovrà caricare ed eseguire le istruzioni corrispondenti all’altro ramo. Esistono due metodi attraverso i quali è possibile eseguire la predizione dei branch: predizione statica e predizione run-time. Con la prima è il compilatore che indica al processore i rami da eseguire per primi, basandosi meramente sull’analisi statica del codice. Nel secondo caso, invece, il processore esegue la scelta basandosi su una tabella di predizione dei branch interna al chip, la quale contiene lo stato di eseguito/mai eseguito associato a ciascun branch. Questa soluzione richiede una quantità di memoria non trascurabile, ma i processori moderni ne fanno uso per ridurre al minimo le perdite di performance dovute ai branch predetti in modo errato.
OUT OF ORDER
Un elevato valore di latenza, unitamente alla presenza dei branch, può creare una serie di “bolle” (cicli di clock non utilizzati) all’interno delle pipeline. Per ovviare a questo inconveniente, si potrebbe pensare di utilizzare questi periodi per eseguire altre istruzioni, ma come? Una possibile soluzione consiste nel riordinare le istruzioni in modo tale che mentre un’istruzione è in attesa, altre istruzioni possono essere eseguite. Esistono due modi per eseguire questo riordinamento. Il primo agisce a livello hardware, in modalità run-time, e consiste nel riordinare le istruzioni in modo tale da massimizzare l’efficienza di esecuzione delle istruzioni (viene per questo denominata esecuzione out-of-order, o semplicemente OoO). Il secondo modo, invece, affida al compilatore il compito di riordinare le istruzioni. La schedulazione avviene in questo caso al tempo di compilazione, ed è pertanto statica. Il primo tipo di approccio è in genere quello che offre i migliori risultati, ma presenta lo svantaggio di richiedere un hardware più complesso, con logiche sempre attive, e pertanto comporta anche consumi elevati. La maggior parte dei processori attuali per elevate prestazioni adotta un meccanismo OoO hardware, fatta eccezione per alcuni processori come ARM11, Cortex-A8, e Atom che adottano ancora uno schema in-order (il motivo è che devono contenere al minimo gli assorbimenti di corrente).
SMT E MULTI-CORE
L’architettura superscalare, unita al meccanismo OoO, non è comunque sufficiente a ottenere un elevato grado di parallelismo nell’esecuzione di programmi reali. La combinazione tra latenze, tempi di attesa dovuti a dati non disponibili in memoria, branch e dipendenze tra le istruzioni, comporta un limite al parallelismo del processore, che spesso non supera una media di 2 istruzioni per ciclo. Se in un programma non si riescono a trovare molte istruzioni che possono essere eseguite in parallelo, l’idea è quella di eseguire più programmi (oppure più thread all’interno dello stesso programma) in modo tale da aumentare il livello di performance. Si ottiene in questo modo la tecnica denominata SMT (Simultaneous MultiThreading) nella quale il parallelismo viene ottenuto tramite l’esecuzione parallela di più thread, in esecuzione sullo stesso processore. Naturalmente, anche un sistema multiprocessore è in grado di eseguire thread multipli simultaneamente, ma soltanto uno per volta su ciascun processore. Ciò avviene anche nei sistemi multicore, nei quali sono presenti due o più processori sullo stesso chip, ma del tutto analoghi ai sistemi tradizionali multiprocessore. In figura 7 è presentato il flusso di istruzioni in un processore SMT. Il Pentium 4 è stato uno dei primi processori ad adottare la tecnica SMT, che Intel chiamò con il termine “hyper-threading”, e consentiva l’esecuzione simultanea di due thread sullo stesso processore.
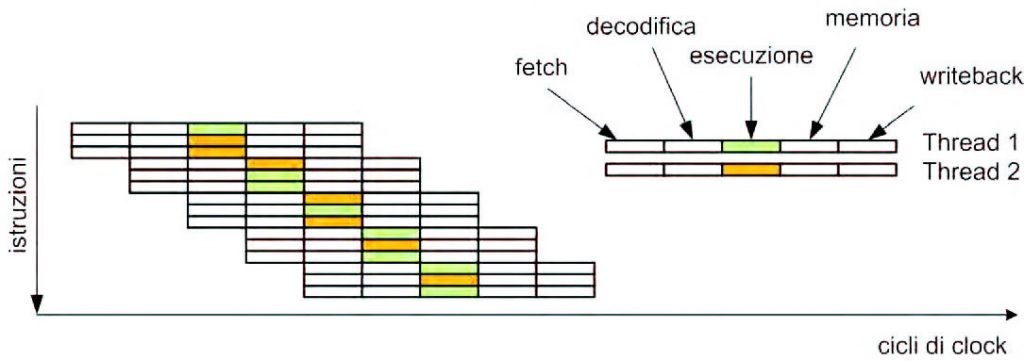
Figura 7: flusso di esecuzione di un processore SMT.

