
Una descrizione dettagliata della struttura interna dei blocchi logici configurabili delle nuove FPGA Spartan-6.
Spartan-6 è la famiglia di FPGA a basso costo e ridotta dissipazione di potenza proposta tempo fa da Xilinx. Realizzati in una tecnologia a 45 nm con processo dual-oxide e 9 piani di metallizzazione, con una tensione di core di 1.2 V (1.0 V nella versione low-power), i dispositivi Spartan-6 rendono disponibili oltre 150.000 celle logiche, integrando CLB con LUT a 6 ingressi, slide DSP con moltiplicatori embedded 18x18, transceiver seriali low-power a 3.125 Gbps, end-point PCI Express e controller DRAM dedicato con capacità di trasferimento dati fino a 12.8 Gbps. Disponibili in packaging green RoHS, rappresentano soluzioni ideali per applicazioni su grossi volumi caratterizzate da costi contenuti, elevata integrazione, bassa potenza, discrete prestazioni e connettività high-speed. Il paragrafo seguente riporta uno sguardo di dettaglio dell’architettura interna dei blocchi logici configurabili (Configurable Logic Block).
LUT A 6 INGRESSI
Xilinx ha da sempre basato l’architettura delle proprie FPGA su blocchi logici configurabili, denominati CLB, dotati di LUT (look-up table) e di elementi di memorizzazione e connessi tra loro da una matrice di routing ad elevate prestazioni. Le LUT sono delle tabelle di consultazione e possono essere usate per generare una qualsiasi funzione logica di un numero di variabili pari alle sue linee d’indirizzo. E’ infatti sufficiente utilizzare gli ingressi della funzione come linee di indirizzo della LUT e memorizzare in ogni sua locazione il risultato che la funzione logica produce quando, appunto, i suoi ingressi hanno i valori corrispondenti all’indirizzo della locazione stessa. Con la serie Spartan-6, Xilinx migliora ulteriormente architettura e prestazioni delle CLB. Una delle caratteristiche principali è certamente la disponibilità di LUT a 6 ingressi. La figura 1 mostra uno schema di principio dell’architettura di tali blocchi.
![Figura 1: l’architettura delle FPGA Stratix V (da [1]).](https://it.emcelettronica.com/wp-content/uploads/2018/10/architettura-delle-FPGA-Stratix-V-1-1024x511.jpg)
Figura 1: l’architettura delle FPGA Stratix V (da [1]).
FLIP-FLOP E LATCH COME ELEMENTI DI MEMORIA
Le LUT sono organizzate in slice; ogni CLB ne include due. Vi sono slice di tipo X, L ed M. Le slice di tipo X, ad esempio, includono 4 LUT ed 8 elementi di memorizzazione. In generale, tali elementi sono flip-flop edge-triggered di tipo D; quattro di essi possono però essere configurati, in alternativa, come latch levelsensitive. Gli ingressi di clock, abilitazione di clock e set/reset sono comuni a tutti gli elementi di memoria della slice ma i controlli possono essere abilitati singolarmente per ognuno di essi. Oltre che come elementi di memoria, i latch possono essere usati anche per generare funzioni logiche di tipo AND ed OR a 2 ingressi, come mostrato schematicamente in figura 2 nel caso di una porta OR. In questo caso il latch ha gli ingressi di enable e clock sempre attivi e i due ingressi della porta OR sono realizzati usando le linee dato e di preset asincrono del latch. Usando al posto di quest’ultimo la linea di reset, si ottiene invece una porta AND.
![Figura 2: implementazione di una porta OR con un latch (da [1]).](https://it.emcelettronica.com/wp-content/uploads/2018/10/implementazione-di-una-porta-OR.jpg)
Figura 2: implementazione di una porta OR con un latch (da [1]).
LOGICA DI RIPORTO E MULTIPLEXER DEDICATI
Alle LUT ed agli elementi di memoria, le slice di tipo L aggiungono poi la disponibilità di multiplexer dedicati e logica di riporto per l’implementazione di funzioni aritmetiche. La logica di riporto, in particolare, consiste di 4 bit per ognuno dei quali sono previsti un multiplexer ed una porta XOR connessa direttamente alle uscite delle LUT, così da non utilizzare risorse di routing e ridurre i tempi di propagazione del segnale. I multiplexer possono invece essere usati per implementare funzioni logiche complesse con un elevato numero di variabile mediante combinazione appropriata delle uscite di diverse LUT. Ad esempio, le uscite di quattro LUT possono essere combinate in modo da realizzare una qualsiasi funzione logica di fino a 8 variabile con una singola slice o particolari funzioni di un numero maggiori di variabili, come in particolare, multiplexer 16:1. LUT e multiplexer all’interno di una slice sono connessi da connessioni dedicate, con minori ritardi di propagazioni. Ovviamente le slice possono poi essere connesse tra loro mediante la matrice di routing per creare funzioni logiche di più di 8 variabili; maggiore è il numero di variabili e quindi di LUT utilizzate, maggiore è il ritardo di propagazione della funzione e quindi minore la massima frequenza di clock raggiungibile dal circuito.
MEMORIA EMBEDDED
Più complessa è invece la struttura delle slice di tipo M, la cui architettura è mostrata in figura 3 e nelle quali le LUT possono in alternativa essere configurate come memoria RAM distribuita o registri a scorrimento.
![Figura 3: struttura di una sliceM (da [1]).](https://it.emcelettronica.com/wp-content/uploads/2018/10/struttura-di-una-sliceM-912x1024.jpg)
Figura 3: struttura di una sliceM (da [1]).
…E REGISTRI A SCORRIMENTO
Oltre che come generatore di funzioni e memoria distribuita, una LUT nelle slice di tipo M può essere configurata anche come registro a scorrimento; la figura 4 ne mostra la struttura in tale configurazione.
![Figura 4: LUT configurata come registro a scorrimento SRL16E (da [3]).](https://it.emcelettronica.com/wp-content/uploads/2018/10/LUT-configurata-come-registro-a-scorrimento-1024x264.jpg)
Figura 4: LUT configurata come registro a scorrimento SRL16E (da [3]).
UNA MATRICE DI CONNESSIONI CONFIGURABILE AD ALTE PRESTAZIONI
Come mostrato schematicamente in figura 5, le CLB sono connesse da una matrice di routing; ogni CLB può accedere a tale matrice di connessioni mediante una serie di switch locali.
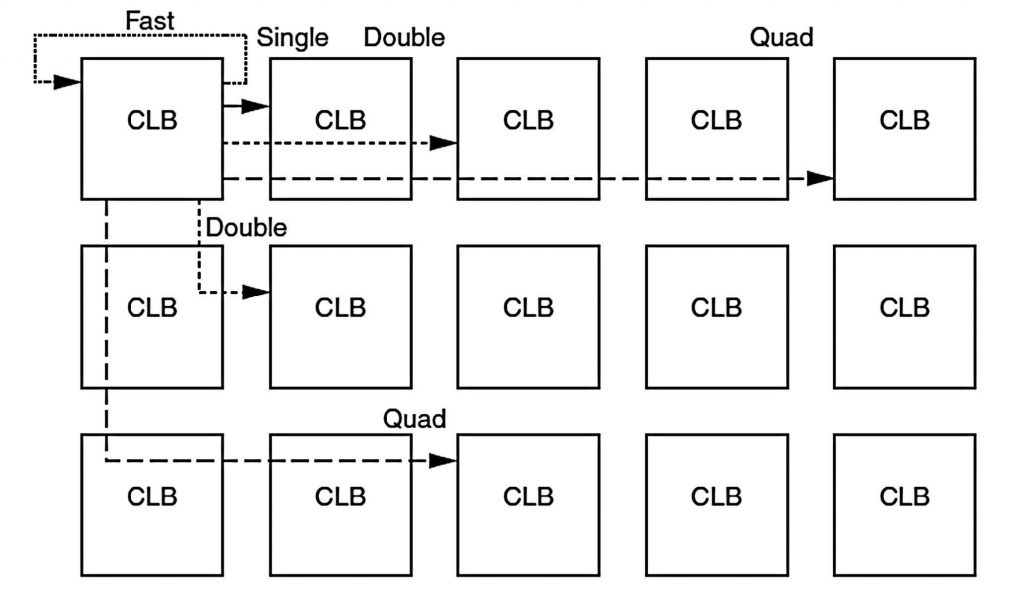
Figura 5: la matrice di routing.
Le interconnessioni rese disponibili sono di vario tipo. Le interconnessioni singole, ad esempio, connettono CLB contigue mentre quelle doppie consentono di connettere CLB una ogni due in direzione orizzontale e verticale e, in direzione diagonale, CLB contigue. Allo stesso modo, le connessioni quadruple connettono CLB una ogni tre in direzione orizzontale e verticale e una ogni due in direzione diagonale. Oltre che dalla lunghezza della linea, i ritardi di propagazione del segnale dipendono dal tipo e dal carico di questa, ovvero dal numero di destinazioni. Da questo punto vista, è interessante osservare come la disponibilità di due uscite indipendenti in ogni LUT permette di replicare una funzione senza consumare ulteriori risorse logiche e di usare quindi connessioni diverse per trasportare il segnale alle diverse destinazioni. Tale possibilità è in genere gestita in automatico dal tool di place&route.

Xilinx, azienda leader di FPGA, ha raggiunto il top dell’efficienza lanciando sul mercato la linea Spartan-6, soprattutto in termini di gestione dell’energia e gestione dell’alimentazione.
Xilinx e Altera/Intel sono i due leader mondiali nella produzione di FPGA. A differenza dei microcontrollori, le FPGA sono sistemi elettronici “configurabili”, ovvero costituiti da un vasto numero di blocchi logici elementari configurabili e tra loro interconnessi a formare blocchi funzionali più complessi detti slice. Tramite la combinazione di slice è possibile implementare qualsivoglia circuito logico/sequenziale di complessità notevole. Le prestazioni di questi componenti sono assimilabili a circuiti ASIC customizzati costruiti con lo stato dell’arte della tecnologia elettronica. Per i blocchi configurabili, se per Xilinx vanno sotto l’acronimo di CLB, per Altera si parla di ALM (Adaptive Logic Module). Il concetto non cambia. Configurare una FPGA equivale a conoscere un linguaggio di descrizione hardware, tipicamente VHDL o Verilog e i relativi ambienti di sviluppo. Si potrebbe quindi pensare che conoscere la logica alla base di un CLB possa risultare inutile e trasparente ai fini della configurazione dell’applicazione finale, ma a mio avviso non è esattamente così. Guardare a come i grandi Big del settore abbiano pensato di implementare determinate soluzioni architetturali apre la mente del progettista finale che potrebbe ritrovarsi ad adottare le medesime idee in progetti non necessariamente basati su FPGA (basti pensare all’utilizzo massivo che se ne fa delle LUT nella programmazione dei firmware per microcontrollori). Una LUT ad n indirizzi (logica combinatoria programmabile) accoppiata ad un’unità di memoria come un Flip Flop o una loro sequenza a formare un registro (logica sequenziale) compongono quanto necessario e sufficiente ad ottenere una qualsiasi funzione logica con risultato accumulabile / memorizzabile.
Per chi non l’avesse fatto, consiglio la lettura dell’articolo correlato sulle FPGA di Altera, al fine di poter porre a confronto CLB e ALM – https://it.emcelettronica.com/fpga-stratix-v-di-altera-prestazioni-high-end
P.S. Articolo davvero ben scritto, voglio solo segnalare una svista nella didascalia alla Figura 1, dove si parla di Stratix V associata a Xilinx mentre la stessa risulta una gamma di FPGA prodotta da Altera.