
Al centro della strada c’è uno degli oggetti più odiati dall’umanità, soprattutto se si è di fretta e lo si trova rosso: il semaforo. Per quanto irritanti, però, dei semafori non si può fare a meno. Un semaforo è lì, da un certo punto di vista, per regolare l’accesso degli automobilisti ad una risorsa condivisa, ossia l’incrocio. Senza il semaforo, è molto probabile che gli automobilisti cerchino di usare contemporaneamente e senza criterio la risorsa condivisa, con i risultati che potete facilmente immaginare. Un semaforo serve per evitare disastri. Con i processi il discorso è identico. I processi sono indisciplinati tanto quanto gli automobilisti: vanno dove vogliono e quando vogliono, e se non li si ferma con delle regole ben precise c’è il serio rischio che combinino anche loro qualche serio disastro. Oggi vi parleremo di come il sistema operativo debba, oltre al resto, regolare il traffico dei processi verso le risorse del sistema.
LAVORO DI SQUADRA
Chi programma tende a vedere il multithreading, quando va bene, con sospetto, e quando va male con timore, e questo vale spesso sia per i programmatori esperti che per i novizi. A ragione? In parte sì. Alla fine dei conti, lanciare qualche thread non è poi questo gran problema. Se programmate per PC, il vostro sistema operativo preferito di sicuro vi metterà a disposizione servizi e/o librerie (e nei casi migliori anche della documentazione) che semplificano l’avvio e la chiusura di un nuovo thread. Se lavorate su microcontrollore, bè, abbiamo visto nelle puntate precedenti come registrare un nuovo thread nello scheduler non sia poi questa cosa fantascientifica. Il problema è tutto nel coordinare i thread. Pensate ai thread come ad un insieme di operai che devono costruire una casa. Se chi tira su i muri non si coordina adeguatamente con chi fa le tubature o l’impianto elettrico, verrà fuori un pasticcio.
Possiamo farne a meno? Del multithreading, intendo. La risposta è semplice: no. Non in parecchi casi, perlomeno. Se la vostra applicazione è semplice, un singolo thread vi basterà. Capita spesso con i sistemi embedded: anche se il sistema operativo vi permette di lanciare più thread, molte volte ci si accontenta di uno solo, un pò perché magari basta, un pò per timore di fare pasticci. Capita però altrettanto spesso che un thread non sia sufficiente. Se il vostro programma deve fare delle elaborazioni e ha anche un’interfaccia grafica, minimo vi serviranno due thread, uno per i conti e uno per la grafica. Se non faceste in questo modo, l’interfaccia si bloccherebbe completamente mentre viene eseguita l’elaborazione, e smetterebbe di rispondere ai vostri click isterici: non si muove, non si riduce a icona, niente di niente fino a che i conti non sono finiti. Con due thread, uno potrà occuparsi dei conti e uno dei vostri click.
Ovviamente, non c’è bisogno di coordinare il muratore con il giardiniere, visto che i loro compiti sono totalmente slegati, e questo capita talvolta anche con il software. Dovete fare due elaborazioni distinte su due insiemi di dati diversi: lanciate due thread, uno per coppia elaborazione/dati e aspettate che finiscano, nulla di più. L’interfaccia grafica passa i dati al thread di elaborazione e si mette in attesa; quando questo secondo thread ha finito i suoi conti, l’interfaccia grafica si riattiva e visualizza i risultati. Questi sono casi facili. Tutte le volte che i compiti da eseguire sono slegati, non occorre poi tutta questa sincronizzazione. Un flag di attesa basta e avanza. Però, come potete facilmente immaginare, ci sono anche casi più difficili. E, ahinoi, anche abbastanza comuni. Il punto con l’esempio dell’interfaccia grafica è che i dati vengono passati una volta all’altro thread, non di continuo.
Prendiamo un esempio un pò più complicato. Prendiamo un compilatore. Un compilatore è quel programma che gira dentro il vostro ambiente di sviluppo preferito, che traduce il vostro codice in istruzioni per il processore. Un compilatore è un attrezzo abbastanza complicato, che fa un mucchio di cose prima di arrivare al codice eseguibile, ma all’inizio deve fare due cose: distinguere i simboli, e dargli un senso. In pratica, prima di tutto un compilatore dice: questa è una parola chiave, questo un operatore, e via dicendo. Questa fase viene detta “analisi lessicale”. Poi organizza questi simboli in costrutti. Dice: questi tre simboli fanno una dichiarazione, questi altri una funzione, e via dicendo. Questo è il “parsing” Sono due fasi distinte che potete decidere o di eseguire una dopo l’altra, o contemporaneamente. Una dopo l’altra significa prima esaminare tutti i file, trovare tutti i simboli, e poi organizzarli in costrutti. Contemporaneamente significa iniziare a creare i costrutti man mano che i simboli vengono individuati. La prima tecnica è semplice, indolore e lenta; la seconda necessita di due thread e di un’opportuna sincronizzazione, ma è molto più efficiente.
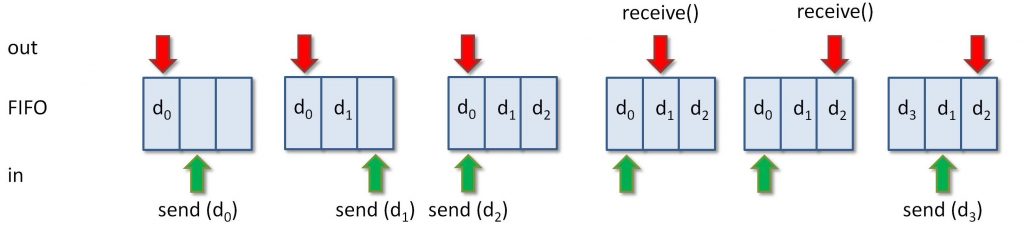
Figura 1: Sincronizzazione con FIFO
Come possiamo far passare dei dati dall’analizzatore lessicale al parser? Una tecnica comune consiste nel condividere un pò di memoria tra i due thread e realizzare, qui dentro, un FIFO. L’analizzatore lessicale lo riempie, il parser lo svuota. Semplice. Sì, semplice ma pericoloso. Pericoloso perché, ad esempio, il parser potrebbe tentare di leggere il FIFO prima che l’analizzatore lessicale l’abbia riempito, oppure potrebbe capitare che l’analizzatore lessicale, in genere più veloce del parser, finisca il buffer, ricominci daccapo, e raggiunga il punto in cui si trova il parser, andandogli a sovrascrivere i dati. In gergo tecnico, questi si chiamano “pasticci”.
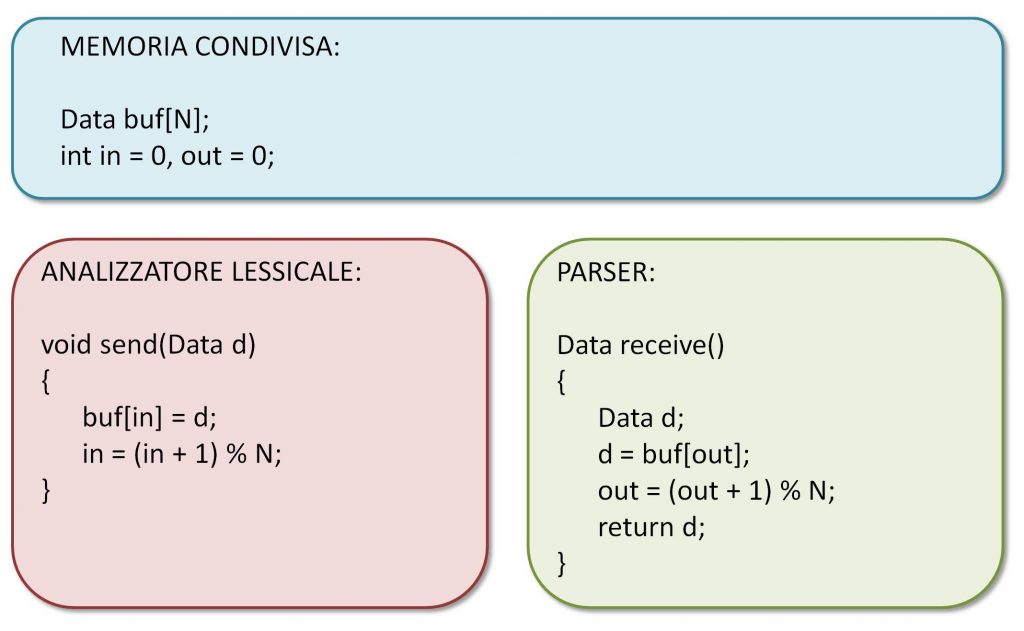
Figura 2: Implementazione del FIFO
Che possiamo fare? Se ci pensate un attimo, vi renderete conto del fatto che una possibile implementazione di questa storia del buffer FIFO è quella mostrata nella Figura 2. L’analizzatore lessicale avrà al suo interno un metodo send() che riempie il buffer e incrementa il relativo contatore di uno (modulo la lunghezza del buffer, s’intende), mentre il parser avrà al suo interno un metodo receive() che preleva un dato dal buffer e incrementa anche lui il relativo contatore. Notare ora come entrambi i contatori si trovino nella memoria condivisa, il che significa che sono visibili da entrambi i thread. Un modo molto stupido per evitare pasticci nel FIFO consiste nel controllare il contatore dell’altro thread: se in è uguale ad out, non ci sono nuovi dati pronti, quindi non li si riceve; se in è maggiore di out, ci sono dei dati che possiamo prelevare. Ci vuole qualche altra accortezza per evitare la sovrascrittura ma, di massima, la strategia pare funzionare. Sostanzialmente, è così che funziona un semaforo.
TU NON PUOI PASSARE
Un semaforo non è niente di che: è un intero che viene inizializzato ad un certo valore. Su un semaforo si possono fare due operazioni: wait() e signal(). Una wait(), come si può facilmente immaginare, aspetta che il valore del semaforo sia maggiore di zero, e poi decrementa l’intero di uno. La signal(), invece, aumenta il valore dell’intero di uno. Se il semaforo è inizializzato a zero, una signal() sblocca una wait() da qualche parte, ovviamente una associata ad uno stesso semaforo.
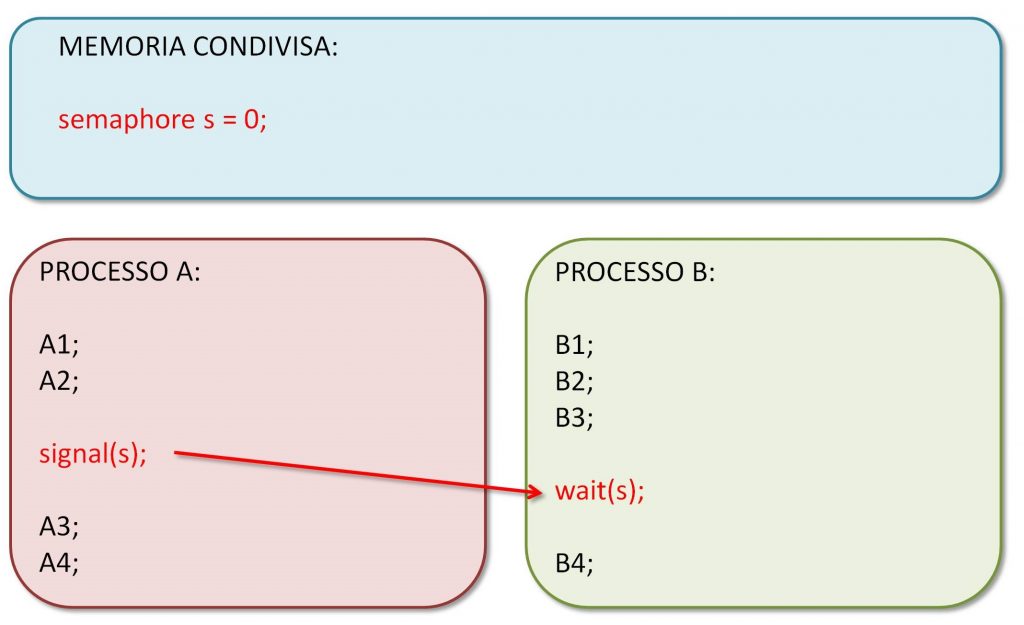
Figura 3: Esempio di utilizzo dei semafori
Tutto qui? Come ci è già capitato di dire, sorprendentemente sì. Con un intero e queste due operazioni si risolvono un sacco di problemi. Prendiamo l’esempio nella Figura 3, e supponiamo che l’istruzione B4 nel secondo thread debba necessariamente aspettare il completamento dell’istruzione A2 nel primo thread, prima di essere eseguita. Basta un semaforo, inizializzato a zero. Dopo l’istruzione B3 mettiamo una wait(). Se il secondo thread è più veloce del primo, arrivato alla wait() troverà il semaforo a zero e si fermerà lì. Quando il primo thread avrà eseguito la sua signal(), il semaforo diventerà uno, la wait() verrà sbloccata e il secondo thread eseguirà l’istruzione B4. Senza pasticci. Se il primo thread fosse più veloce del secondo, allora la signal() verrebbe eseguita prima della wait(), il secondo thread troverebbe già il semaforo a uno e passerebbe oltre senza fermarsi. Di nuovo, senza pasticci. [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2964 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
Protocolli di Comunicazione per l’Internet delle Cose (IoT)
Streaming di temperatura e umidità con l’ecosistema Big Data – Parte 1
Progettiamo i nostri filtri con FilterPro della Texas Instruments
Servomotori e Arduino: come usarli con la scheda a micro-controllore
EOS-Book @A Corso C su Raspberry PI partendo da zero
