
La valutazione dell’affidabilità di un sistema a partire dai suoi componenti o dal verificarsi dei guasti è una fase importante dell’analisi dell’affidabilità. Tale aspetto sta assumendo un rilievo tale da impiegare nelle varie realtà aziendali unità operative dedite alla modellazione dei sistemi in fase di sviluppo secondo vari approcci. In questo articolo ci occuperemo principalmente d’introdurre l’argomento ‘previsioni affidabilistiche’, di cercare di capire l’utilizzo che si fa dei dati raccolti nella vita di un qualsiasi componente elettronico e non, infine di conoscere i principali software sul mercato per fare queste predizioni.
Tra gli approcci per l’analisi dell’affidabilità di un sistema ci sono principalmente: i Reliability Block-Diagrams (RBD), che comportano la costruzione di un sistema di componenti dal punto di vista funzionale, dove ciascun blocco rappresenta un componente; la FaultTree Analysis (FTA), un metodo che suddivide il verificarsi di un evento importante non desiderato (ad es. la rottura del sistema) in eventi intermedi e di partenza (fault), collegati tra di loro da bocchi logici; l‘Event-Tree Analysis (ETA), un’analisi che fa derivare sequenze cronologiche da un evento scatenante non desiderato (ad es. un’esplosione) che porta alle conseguenze finali, infine la Failure Mode and Effects Analysis (FMEA), un metodo che opera una costante decomposizione del funzionamento del sistema in modalità di rottura, nelle relative cause e nelle rispettive conseguenze. Tutti questi diversi approcci poggiano in modo strutturale su dati relativi al failure rate (tasso di fallimento) di ogni singolo componente alla base del sistema. Quindi il nostro scopo in questa breve trattazione è fare luce sulle raccolte dati che descrivono il tasso di fallimenti dei sistemi elettronici, capire la gestione e l’aggiornamento di questi dati, infine portare avanti una breve analisi sui tools esistenti sul mercato utili per semplificare e rendere più facilmente computabile il tasso di fallimenti dell’intero sistema o quantomeno stabilire la disponibilità, l’affidabilità e l’inaffidabilità di un sistema elettronico. Sono diverse le finalità delle previsioni di affidabilità in relazione all’uso che viene fatto dei dati calcolati, le più importanti sono le seguenti:
» verificare il raggiungimento degli obiettivi di progetto per un lavoro che prevede la stima di parametri affidabilistici di targa;
» stabilire valori contrattuali da rispettare;
» fissare gli obiettivi per le prove di affidabilità ed un riferimento per i valori osservati;
» effettuare dei confronti tra differenti soluzioni;
» fornire dati di riferimento per le analisi di disponibilità di sistema;
» fornire dati per il dimensionamento logistico a livello di componente ed unità funzionale.
Origine dei dati
I dati di affidabilità che contribuiscono ai diversi handbook provengono principalmente dall’osservazione dei prodotti in campo, operativi principalmente nei seguenti tre tipi di ambienti (naturalmente tra i diversi handbook, in relazione alle finalità per cui sono stati raccolti i dati, si hanno diverse tipologie di ambienti):
» ambiente fisso protetto;
» ambiente fisso parzialmente protetto o non protetto;
» ambiente mobile: apparati portatili o su veicoli terrestri.
I modelli di previsione non intendono fornire una rappresentazione del comportamento fisico dei componenti o una indicazione dei loro meccanismi di guasto, ma rappresentano la miglior stima a partire dai dati osservati. La scelta di preferire dati dal campo a dati di laboratorio è coerente con il significato statistico dei modelli di previsione. I modelli vogliono, in altre parole, rappresentare ciò che accade a regime sui prodotti in condizioni reali di esercizio. Solo in mancanza di dati dal campo si rendono insostituibili quelli derivanti da prove di laboratorio anche se, sia le condizioni di prova che i criteri di guasto, possono differire da quelli dei prodotti in campo. I dati grezzi disponibili che vanno a formare i diversi handbook sono stati trattati secondo criteri opportuni (analisi statistica, stratificazione in funzione del tipo di apparato, località geografica…) in modo da tenere conto dei fattori d’influenza esistenti e di individuare i valori anomali e quelli chiaramente originati da cause esterne. Ciò consente di eliminare dalla posizione osservata quella non ancora matura dal punto di vista affidabilistico, ovvero affetta da sistematicità di guasto, errori di progetto, mortalità infantile. Di solito i diversi handbook sono strutturati in modelli che forniscano un valore del tasso di guasto; peraltro questo non deve far pensare che il calcolo revisionale di affidabilità abbia un carattere automatico. L’affidabilità dei componenti elettronici dipende in gran parte dall’applicazione, oltre che essere una caratteristica intrinseca, quindi è necessaria la conoscenza delle effettive condizioni d’impiego per garantire l’accuratezza delle previsioni. Va inoltre osservato che l’affidabilità non si raggiunge senza sforzi, quindi i calcoli di affidabilità trovano la loro corretta collocazione all’interno di un programma di qualità e affidabilità che preveda l’esecuzione di verifiche e prove durante tutto l’iter di sviluppo del prodotto:
» prove di accrescimento dell’affidabilità;
» prove climatiche ed ambientali;
» dimostrazioni di affidabilità.
Si rimanda alle pubblicazioni IEC 60300-1 e IEC 60300-2 per l’individuazione degli elementi e dei compiti propri di un programma di affidabilità.
Ipotesi generalmente adottate nelle raccolte dati
I modelli generalmente presentati nelle diverse prefazioni o appendici alle raccolte dati fanno riferimento ad un tasso di guasto costante nel tempo relativo al periodo detto di ‘vita utile’ di un componente. Questa ipotesi richiede alcuni commenti alla luce dell’osservazione del comportamento degli apparati in campo durante la loro vita.
Guasti Infantili
Ogni nuovo apparato all’entrata in servizio mostra in generale un andamento decrescente del tasso di guasto. Durante il primo periodo sono presenti guasti dovuti ad errori di progetto, componenti mal utilizzati, difetti di fabbrica ecc... che una volta individuati, inducono azioni correttive con l’effetto di portare l’apparato in condizioni di stabilità e maturità affidabilistica. Questo fenomeno si sviluppa nel breve/medio termine, convenzionalmente si ritiene concluso entro il primo anno di vita. Il periodo dei guasti infantili non viene esplicitamente trattato nei modelli; questa ipotesi semplificatrice è del tutto realistica e confermata dall’esperienza proveniente dall’analisi di apparti per i quali la progettazione sia stata correttamente eseguita. Ciò, inoltre, equivale a considerare gli apparati nel periodo di maturità e risulta coerente col significato che viene dato al tasso di guasto di previsione il quale va considerato un obiettivo della raccolta dati.
Vita utile ed usura
Normalmente il periodo di vita utile dei componenti, prima che insorgano i guasti per usura, è sufficientemente lungo se rapportato a quello di vita degli apparati.
Natura dei guasti considerati
I modelli presenti in ogni handbook sono orientati a descrivere i guasti come originati dal comportamento intrinseco dei componenti in relazione all’impiego ed all’applicazione. In effetti, pur applicando regole di analisi e filtraggio dei dati, è difficile separare il contributo dovuto al solo componente da quello indotto dall’applicazione. D’altra parte, una volta eliminati i comportamenti chiaramente anomali, tale separazione non risulta particolarmente significativa quando si voglia descrivere il comportamento reale degli apparati in campo. In pratica esiste necessariamente una piccola parte di guasti non intrinseci tra i dati esaminati, che non è possibile né significativo identificare come tale. Si constata, ad esempio, che l’affidabilità dei componenti appartenenti alle parti centrali dell’apparato è, a parità di condizioni, migliore di quella dei componenti posti alla periferia, ovvero di quelli che hanno interazione con l’ambiente esterno. Ciò è dovuto, ad esempio, all’effetto di sovratensioni esistenti anche in apparati convenientemente protetti. Questi guasti non intrinseci, purchè la loro entità sia limitata rispetto al valore totale, sono compresi nei valori forniti di tasso di guasto. Può fare eccezione qualche caso particolare, come quello del dimensionamento delle scorte, ove sia utile o necessario considerare errori di progetto o altre cause di guasto esterne ai componenti. In questi casi (per es. il calcolo di scorte) è consigliabile maggiorare i valori forniti sulla base dell’esperienza. In più dei dati presenti negli handbook non si forniscono intervalli di confidenza in virtù della mole considerevole di dati accumulati per la realizzazioni di quei testi. Va sottolineato, infine, che i valori presentati di volta in volta nelle diverse raccolte dati non possono essere usati per effettuare confronti tra componenti per orientarne la scelta essendo essi il risultato di valori medi osservati e non, quindi, basati su considerazioni tecnologiche.
Aggiornamento dei modelli
I modelli e i dati hanno una validità riferita ad un periodo di tempo e sono, quindi, soggetti ad aggiornamento: ciò comporta la pubblicazione di nuove edizioni delle diverse raccolte dati, sia per tener conto dell’evoluzione delle tecnologie, sia perché il tasso di guasto mostra, in generale, un andamento decrescente nel tempo per effetto dei miglioramenti che intervengono su componenti e apparati. Risulta quindi necessario considerare nel tempo l’ipotesi di tassi di guasto costante come una proiezione basata su dati storici che vale su di un orizzonte temporale finito. Un tasso di guasto decrescente si ottiene solo attivando iniziative di prevenzione e miglioramento supportate da adeguati investimenti.
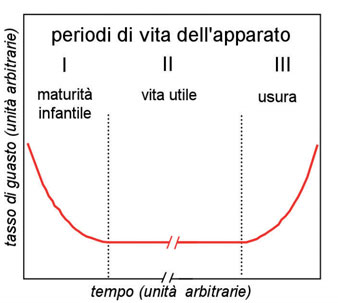
Figura 1: andamento ideale nel tempo dei tasso di
guasto (“bath-tub” curve, curva “a vasca da bagno”).
Utilità ed obiettivi delle previsioni di affidabilità
Le previsioni di affidabilità sono uno strumento di supporto nelle diverse attività di sviluppo di un prodotto. Nella fase di progetto permettono l’eliminazione di criticità esistenti indirizzando:
» la ripartizione dell’affidabilità tra le parti del sistema;
» l’ottimizzazione delle condizioni d’impiego;
» l’ottimizzazione del progetto termico. In questa fase inoltre permettono di stimare gli obiettivi di affidabilità di un nuovo progetto e confrontare soluzioni differenti.
In una fase successiva alla realizzazione di un ben determinato sistema le previsioni servono principalmente all’analisi di disponibilità e nel dimensionamento logistico delle scorte. Infine, le previsioni di affidabilità costituiscono un riferimento che permette di monitorare le verifiche di affidabilità (prove e dimostrazioni) ed evidenziare eventuali comportamenti anomali al fine di porvi rimedio a valle di analisi. Questo processo di miglioramento risulta indispensabile per eliminare fenomeni di mortalità infantile e correggere errori di progetto. Nella realtà si osservano comportamenti anche molto diversi da quelli indicati nelle previsioni: questo non è un limite, ma è anzi un punto di forza delle previsioni.Infatti, la modalità con cui sono definiti i modelli è tale da considerare di principio i dati provenienti da apparati affetti da problemi e quindi valori osservati più alti delle previsioni sono il segnale per intraprendere azioni di miglioramento. Per contro, valori osservati inferiori a quelli previsti, una volta verificati e consolidati, sono il presupposto per l’aggiornamento e la taratura dei modelli in una logica iterativa che costituisce il cosiddetto ‘Metodo dell’Affidabilità’ come sintetizzato in figura 2.
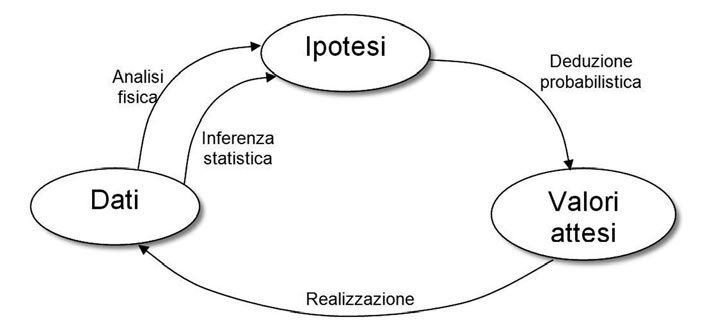
Figura 2: automa analisi affidabilistiche.
Per chiudere il circolo rappresentato risulta di fondamentale importanza l’analisi fisica degli elementi guasti. Ogni guasto osservato ha la propria causa, considerarlo di natura casuale è un modo convenzionale per descrivere tutti quei casi in cui risulta impossibile o troppo costoso ricercare e individuare la causa del guasto, pur sapendo che essa sarebbe l’unico modo per evitarne il ripetersi. La possibilità di individuare la causa del guasto (escludendo i guasti dovuti a cause esterne) dipende dalla capacità offerta dai mezzi di analisi (strumenti, risorse e know-how); questa migliora nel tempo per effetto del miglioramento della tecnologia e quindi i limiti oggi esistenti saranno superati in futuro anche se vi sarà sempre una barriera non superabile rappresentata dai limiti della tecnologia stessa. A questo punto possiamo porre una domanda: fin dove può arrivare la ricerca delle cause dei guasti? I guasti hanno un costo (che comprende sia i costi veri e propri della riparazione che quelli indotti sull’utente e sul servizio offerto, compreso anche il costo legato alla perdita di quote di mercato), l’analisi fisica ha un costo, quindi il punto di convenienza è rappresentato dal bilanciamento di questi due costi come rappresentato in figura 3.
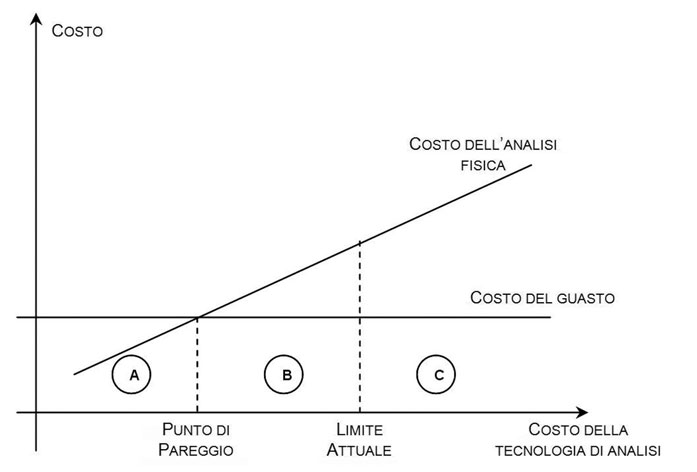
Figura 3: validità della ricerca delle cause dei guasti.
Possiamo identificare tre aree:
■ A- Rappresenta l’area dei guasti la cui analisi (individuazione delle cause) ha un costo inferiore a quello del guasto stesso. Questi guasti vengono rimossi realizzando attività di prevenzione e correzione;
■ B- Rappresenta l’area per la quale il bilanciamento puramente economico sconsiglierebbe di attuare l’analisi dei guasti. Occorre tuttavia notare come, quasi sempre, altre considerazioni spingano invece verso investimenti in queste attività; l’affidabilità dei prodotti costituisce un elemento di eccellenza per l’acquisizione di quote di mercato.
■ C- Rappresenta l’area dei guasti per i quali non sono ancora disponibili le tecnologie di analisi e che, quindi non possono essere definitivamente rimossi. In questo caso occorre investire nello sviluppo della tecnologia, in particolare in quei casi in cui può essere coinvolta la sicurezza delle vite umane.
In definitiva il punto di lavoro ottimale risulta situato all’interno dell’area B; tutti i guasti appartenenti allo spazio alla destra di questo punto sono quelli convenzionalmente considerati casuali e trattati dai modelli di previsione. Questi modelli descrivono quindi guasti di entità nota (statisticamente) ed accettabile.
Figura 4: Reliability Block Diagram Relex Module.
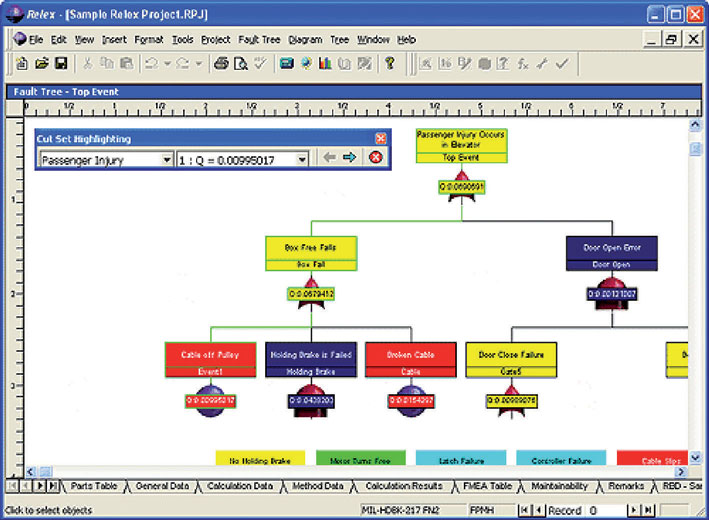
Figura 5: Fault Tree Analysis Relex Module.
Principali fattori d’influenza del tasso di guasto
Di solito nei diversi handbook il tasso di guasto risulta dipendere da un certo numero di fattori, ognuno rappresentato da un pi-factor, cioè un fattore moltiplicativo, possiamo avere:
» fattori relativi al componente (tecnologia, complessità, tipo di contenitore);
» fattori legati all’applicazione (temperatura, stress elettrico);
» fattori legati all’utilizzo (duty cycle);
» fattori ambientali;
» fattori legati alla qualità.
La formulazione dei modelli presenta in generale un valore base del tasso di guasto (relativo alla temperatura di funzionamento che viene assunta tipica o di riferimento) ed alcuni fattori moltiplicativi ognuno relativo ad un fattore d’influenza. Le condizioni tipiche sono riferite alla maggioranza delle applicazioni. I fattori legati all’applicazione sono indicati per ogni tipo di componente precisandone il modello specifico. Per quanto riguarda la temperatura, viene definita la temperatura ambiente di componente come quella che si avrebbe nel punto in cui è montato il componente, supponendo di poterlo rimuovere. A partire da questa temperatura viene calcolata, a seconda dei casi, la temperatura di giunzione o la temperatura del corpo del componente secondo le regole indicate caso per caso.
Le raccolte dati più utilizzate
Analizziamo in breve le diverse raccolte dati in termini di data di pubblicazione (vedi tabella 1) e di aspetti caratteristici, quindi nei prossimi paragrafi ci occuperemo di descrivere in particolare almeno una delle forme di analisi suggerite in questi standard, sarebbe troppo lungo e pedante analizzare tutti i metodi proposti. Ciò non toglie che con una maggiore conoscenza dei dettagli implementativi del sistema risulti possibile implementare forme di analisi diverse (più approfondite), che portino in conto gli ultimi dettagli emersi da un ipotetico ciclo di sviluppo.

Tabella 1: alcune delle principali raccolte dati.
“Militar y Handbook, Reliability Prediction of Electronic Equipment”, MIL-HDBK-217, Revision F, Notice 2
MIL-217 è la raccolta dati più conosciuta e più utilizzata in assoluto per la previsione di affidabilità dei sistemi puramente elettronici. Viene utilizzata sia in ambito commerciale che nella difesa, e risulta uno standard di previsione affidabilistica universalmente riconosciuto ed accettato. La versione più recente è stata rilasciata nel Febbraio del 1995. Contiene i modelli di failure rate di numerosi componenti elettronici e circuiti integrati, ma anche transistor, resistenze, condensatori, relay, switch, connettori ecc. MIL-217 richiede una grossa quantità di dati per poter realizzare una valutazione completa. La stima affidabilistica ottenuta risulta essere conservativa rispetto a quella ottenuta con l’altro standard che andremo a considerare, Bellcore. Ciò è dovuto principalmente all’uso originario per cui è stata pensata la raccolta dati, l’ambito militare ed aerospaziale.
“Reliability Prediction Procedure for Electronic Equipment” Bellcore Technical Reference TR-332
Lo standard Bellcore è figlio della ricerca portata avanti presso ‘AT&T Bell Communications Research’ ed ora in gestione presso Telcordia Technologies Inc. L’handbook Bellcore risulta essere originariamente una derivazione del Mil-217. Tale variante nasce a causa della scarsa fiducia riposta negli handbook disponibili da parte dell’industria delle telecomunicazioni. In più in questo handbook abbiamo la possibilità di tenere in conto nell’ambito della definizione del failure rate anche una fase iniziale di ‘burn-in’ e perfino in parte i dati provenienti dal campo e dal testing di laboratorio. Lo standard Bellcore è datato Dicembre 1997 (TR-332, Issue 6) ed intitolato “Reliability Prediction Procedure for Electronic Equipment”. Può essere utilizzato nelle telecomunicazioni, per computer e prodotti elettronici commerciali. Molte aziende che si occupano dell’elettronica di consumo usano questo standard per le predizioni di affidabilità. Oggi lo standard è in gestione a Telcordia riferito come Telcordia Technologies Special Report SR-332, Issue 1, datato Maggio 2001. Questa revisione ha praticamente lasciato invariato il metodo di valuzione affidabilistica, aggiorna solo qualche informazione relativa al failure rate e spiega con maggiore chiarezza l’uso dei tre metodi (I, II e III) di valutazione proposti nello standard.
NSWC-98/LE1 Reliability Prediction of Mechanical Components
Lo standard di predizione affidabilistica del NSWC (Naval Surface Warfare Center dell’US Navy) è usato comunemente per modellare sistemi o semplici componenti meccanici. La versione attuale in utilizzo è stata resa pubblica il 30 Settembre 1998 dal ‘Naval Surface Warefare Center, Carderock Division’ con il numero di report ‘NSWC-98/LE1’, intitolato “Handbook of Reliability Prediction Procedures for mechanical Equipment”. Il metodo di predizione proposto prevede una serie di modelli per le diverse categorie di componenti meccanici per operare una predizione del failure rate sulla base di fattori come la temperatura e lo stress. Sono previsti vari tipi di dispositivi meccanici tra cui cuscinetti a sfera, motoriduttori, ingranaggi, motori, avvolgimenti, assi, freni, valvole ecc… NSWC è uno standard di predizione affidabilistica relativamente giovane ed è uno dei pochi sul mercato fornito per questo tipo di componenti. La valutazione dell’affidabilità dei componenti meccanici è storicamente molto difficile, a causa della presenza di un’ampia varietà di failure rate per componenti solo apparentemente simili, in quanto componenti meccanici simili possono portare avanti funzioni molto diverse. Failure rate costanti di solito non descrivono componenti meccanici, a causa dell’usura e dello stress che portano al degrado del componente. I dispositivi meccanici sono più sensibili ai carichi, ai modi e alla frequenza di utilizzo a confronto dei componenti elettronici. Lo standard NSWC è stato sviluppato appositamente per questo tipo di previsione affidabilistica a partire da modi specifici di fallimento, considerando ambienti di utilizzo, gli effetti dell’usura, l’utilizzo di lubrificanti, e altri accorgimenti particolari.
MIL-HDBK-217
L’handbook consta di due metodi di predizione della reliability, ‘Parts Stress Analysis’ e ‘Parts Count Analysis’. I due metodi possono essere utilizzati in relazione alla quantità di informazioni disponibili del sistema da valutare. Il metodo ‘Parts Stress’ richiede una certa quantità d’informazioni dettagliate e risulta, quindi, maggiormente utilizzabile nelle fasi della progettazione più avanzate. Il metodo ‘Parts Count’ richiede meno informazioni e si basa esclusivamente su quantità, livello di qualità e ambiente di utilizzo. Tale metodo può essere utilizzato nelle primissime fasi del ciclo di sviluppo di un sistema ottenendo un risultato sicuramente conservativo rispetto ad un modello più dettagliato ‘Parts Stress’.
Parts Stress Analysis
È il metodo di analisi più utilizzato, soprattutto quando il progetto di principio del sistema è vicino al completamento ed è disponibile una lista dei componenti dettagliata. Lo standard si riferisce alle condizioni di funzionamento del sistema come fattori ambientali, temperatura, in tensità di corrente, voltaggio ecc. Lo standard Mil-217 divide i componenti in categorie all’interno delle quali troviamo diverse sottocategorie caratteristiche del metodo di costruzione, per esempio ‘fixed electrolytic (dry) aluminum capacitor’ è una sottocategoria del gruppo ‘capacitor’. Un classico esempio di valutazione del failure rate secondo il MIL-HDBK-217 può essere:
![]()
[Failures/10 ore]
Dove:
λP: Part failure rate
λb: Base failure rate
πT: fattore moltiplicativo temperatura
πA: fattore moltiplicativo relativo all’applicazione
πR: fattore moltiplicativo relativo al Power rating
πC: fattore moltiplicativo relativo ai contatti del componente
πQ: fattore moltiplicativo qualità
πE: fattore moltiplicativo relativo all’ambiente operativo.
In ogni caso esistono veramente molti modelli complessi specialmente per la valutazione dell’affidabilità dei microcircuiti. Per capire che alla fin fine non tutti i pi-factor vengono considerati nei diversi componenti, possiamo considerare l’esempio di un ‘solid tantalum fixed electrolytic capacitor’, dove abbiamo:
![]()
[Failures/10 ore]
Dove:
λP: Part failure rate
λb: Base failure rate
πCV: fattore moltiplicativo base failure rate per componente
πSR: fattore moltiplicativo relativo alla resistenza serie
πQ: fattore moltiplicativo di qualità (i livelli di qualità sono D,C,S,B,R,P,M,L,Lower)
πE: fattore moltiplicativo relativo all’ambiente operativo
Parts Count Analysis
Per questo tipo di analisi sono richieste un numero limitato d’informazioni. La formula generica per questo tipo di previsioni riportata nell’Appendice A dello standard risulta:
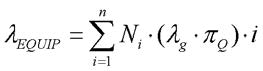
[Failures/10 ore]
Dove:
λEQUIP: Failure rate totale dell’equipment λg: Generico failure rate dell’i-esimo componente
πQ: fattore moltiplicativo di qualità dell’i-esimo componente
Ni: numero di componenti dell’i-esimo tipo
n: numero di differenti tipi di componenti nel modello
πL: fattore moltiplicativo di learning, relativo solo a microcircuiti se in produzione per meno di due anni.
Bellcore (Telcordia) standard TR-332 Issue 6
Le procedure indicate in tale standard sono simili a quelle relative alla ‘Parts Stress Anaysis’ dello standard MIL-217. Attraverso lo stress dei componenti, le condizioni di funzionamento, la temperatura, il voltaggio, ecc. lo standard indica formule per il calcolo del failure rate. Anche con questo handbook abbiamo una divisione dei componenti in categorie e sottocategorie.
La procedura di calcolo viene distinta in tre metodi per la predizione dell’affidabilità, ogni metodo richiede un maggior numero d’informazioni disponibili circa la realizzazione da valutare. Abbiamo:
» Metodo I – è un metodo di tipo “black box” in cui si assume che non siano disponibili dati relativi all’affidabilità dei diversi dispositivi inclusi nel sistema. Le predizioni sono basate sulla discussione di parametri affidabilistici generici. È il più semplice dei tre metodi.
» Metodo II – si usa questo metodo se sono disponibili dei dati relativi a failure rate provenienti da prove di laboratorio per alcuni o tutti i dispositivi e le unità da valutare.
» Metodo III – si usa se esistono una gran quantità di dati provenienti dal campo per alcuni o tutti i dispositivi. È ovvio che si ottiene una migliore predizione con il metodo III avendo molti dati relativi al sistema reale.
Una caratteristica di questo handbook è che tra i diversi fattori moltiplicativi c’è anche un ‘First year multiplier’ (FYM), tale pi factor viene utilizzato per regolare il failure rate nel caso il componente che si sta valutando operi da meno di un anno (8760 ore). Secondo il Metodo I il failure rate di un semplice componente generico può essere valutato come:
![]()
[Failures/10 ore]
Dove:
λSSi: Steady-state failure rate per il componente i-esimo
λGi: Generico steady-state failure rate per il dispositivo i-esimo
πQi: Fattore moltiplicativo di qualità per il dispositivo i-esimo
πSi: Fattore moltiplicativo di stress elettrico per il dispositivo i-esimo
πTi: Fattore moltiplicativo relativo alla temperatura per il dispositivo i-esimo
πAi: Fattore di aggiustamento per il componente.
Mentre per l’unità il failure rate viene valutato come:
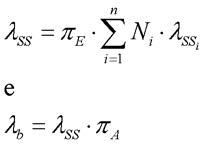
[Failures/10 ore]
Dove:
λb: Block failure rate
πA: Fattore di aggiustamento per il block
λSS: Steady-state failure rate
λSSi: Steady-state failure rate per il com ponente i-esimo
n: numero di diversi tipi di dispositivi nell’unità
Ni: numero di elementi dell’i-esimo tipo
πE: Fattore ambientale
A livello sistema abbiamo un λSys dato da:
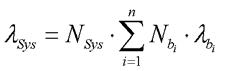
[Failures/10 ore]
Dove:
λSys: System failure rate
NSys: numero di sistemi
Nbi: numero di blocchi del tipo i-esimo
λbi: failure rate per blocco i-esimo
Concludiamo con la valutazione del failure rate nel caso in cui un determinato componente stia operando ancora nel suo primo anno di vita, in tal caso interviene il ‘First year multiplier’ secondo la relazione:
![]()
[Failures/10 ore]
Dove:
λFY: failure rate medio durante il primo anno di vita
λSS: Steady-state failure rate del dispositivo
πFY: First year multiplier.
Principali pacchetti software dedicati alle previsioni affidabilistiche
Relex Visual Reliability Software
La suite di programmazione Relex (gestione dell’affidabilità, della manutenzione e della sicurezza) si propone di migliorare la qualità, ridurre il costo per bassa qualità (COPQ) e migliorare l’affidabilità in ogni fase del ciclo di vita del prodotto. L’idea alla base di questo prodotto software è gestire la qualità e l’affidabilità attraverso tutto il ciclo di vita di un prodotto, acquisendo una visione tale da trovare spunti innovativi per le successive linee di produzione. Relex include i seguenti tools utilizzabili in modo distinto:
» Relex Reliability Prediction: incorporando tutti gli standard progettuali universalmente accettati, Relex offre il più ampio pacchetto di predizione affidabilistica disponibile sul mercato;
» Reliability Block Diagram (RBD): in grado di fornire un’ampia gamma di metodi di calcolo per la definizione delle distribuzioni di affidabilità e manutenibilità;
» Relex OpSim: offre una piattaforma di modellazione dei sistemi per analizzare sistemi complessi in cui i pezzi di ricambio e gli intervalli di manutenzione possano essere ottimizzati rispettando i vincoli di costo e di magazzino;
» Relex FMEA/FMECA: prevede le FMEA di progetto, di processo e personalizzate, nel rispetto degli standard industriali come la MIL-STD-1629 e la SAE J1739;
» Relex Maintainability: offre un approccio organizzato per la definizione delle proprietà di riparazione di un sistema. Basato su MIL-HDBK-471, questo modulo include una biblioteca di compiti e permette all’utente di analizzare un’ampia gamma di caratteristiche manutentive;
- Relex Fault Tree Analysis (FTA): un potente ed articolato calcolatore di alberi degli eventi e dei guasti, graficamente accessibile. Include un insieme di strumenti di calcolo per analisi quantitative e qualitative. Questo modulo consente all’utente d’individuare visivamente quali modi di guasto contribuiscano a causare un guasto finale.
» Relex Life Cycle Cost (LCC): basandosi su una Cost Breakdown Structure, LCC valuta il costo di un sistema nel suo ciclo di vita intero. Molti tipi di costi come la progettazione, la produzione, la garanzia, la riparazione e lo smaltimento possono essere valutati nell’analisi;
» Relex Weibull: fornisce un potente strumento statistico all’interno di un’interfaccia user-friendly, per un’analisi dei dati di campo.
» Relex FRACAS Management System:
FRACAS (Failure Reporting, Analysis and Corrective Action System) è un sistema per l’azienda per gestire dati importanti, come le richieste di servizio, le attività di riparazione ed i rapporti di guasto. Il pacchetto permette all’utente di controllare le prestazioni del sistema, concentrandosi sulle aree critiche e ottimizzare i processi esistenti. Le informazioni for nite da FRACAS possono essere impiegate per migliorare la qualità e l’affidabilità di prodotti e di processi attuali e quelli futuri.
Item Toolkit
IT EM Software è una società leader mondiale nel supporto dello sviluppo dell’affidabilità software. Dalla metà degli anni ’80 ITEM Software ha supportato studi d’ingegneria con lo stato dell’arte della reliability, safety e Risk Analysis Software. I prodotti software sono distribuiti in oltre 37 paesi, presso più di 500 compagnie e organizzazioni che operano nell’ambito difesa, telecomunicazioni, aerospazio, automotive, nucleare, medicale, elettronico ecc… Uno dei prodotti più completi di questa società di software è ITEM Toolkit, ormai giunto alla release 7.08 è una suite comprensiva di moduli per l’analisi e la predizioni di reliability, availability, maintainability e safety di componenti e sistemi complessi elettronici/meccanici. ITEM Toolkit è un framework integrato che offre analisi dello sviluppo delle diverse parti di un sistema riducendo lo sfrido di tempo e risorse. Tra i diversi tools di analisi abbiamo:
» Reliability Prediction;
» MIL-217 (MIL-HDBK-217);
» Telcordia / Bellcore (SR-332/TR-332);
» IEC 62380 (RDF 2000);
» China 299b;
» NSWC (NSWC-06/LE10);
- Failure Mode Effect and Criticality Analysis (MIL-STD-1629);
» Fault Tree Analysis;
» Event Tree Analysis;
» Reliability Block / Network Diagram Markov Analysis;
» MainTain (Maintainability, MIL-HDBK-472);
» SpareCost (Spare Optimization).
A seguito del singolo utilizzo di uno dei moduli, ITEM Toolkit permette attraverso un ambiente integrato di riutilizzare i risultati di un modulo negli altri, questo aspetto può essere molto utile lì dove si valutano sistemi complessi, la cui analisi è stata portata avanti mediante decomposizione funzionale.
Sharpe
SHARPE, (Symbolic Hierarchical Automated Reliability and Performance Evaluator) è un tool per la specifica e l’analisi di modelli di performance, reliability e performability. È un tool free sviluppato a livello universitario che for nisce un linguaggio di specifica e metodologie di risoluzione per i più comuni modelli per la reliability e la performability. I tipi di modelli supportati includono quelli combinatori come faul-trees e reti di code, ma anche modelli a spazi di stato come catene di Markov e semi-Markov, e ancora modelli stocastici come le reti di Petri. Questo tool mette a disposizione strumenti più legati al mondo accademico, con la possibilità di saggiare le capacità di modellazione dei professionisti dei diversi settori interessati allo studio degli aspetti affidabilistici dei sistemi, non sono inclusi dati provenienti dagli handbook elencati per i due programmi commerciali presentati nei paragrafi precedenti, quindi è necessario per l’utente avere a disposizione i dati su cui operare le valutazioni.


