
Il linguaggio C è di gran lunga usato nella programmazione dei sistemi embedded ed esistono numerosi volumi che ne illustrano la semantica e la sintassi. Molto più raro è invece trovare una trattazione che illustri le regole principali sull’ottimizzazione degli algoritmi in modo da rendere il codice molto più veloce e compatto. Ecco una breve raccolta di suggerimenti pratici per AVR usando il compilatore AVR-GCC.
Introduzione
Il C è un linguaggio di alto livello il che significa che non è riferito ad un particolare hardware quindi il programmatore non deve accedere alle risorse del microcontrollore come i registri interni, lo stack ecc… Questo, se da un lato facilita molto la stesura del codice, dall’altro impedisce di compiere alcune operazioni che sarebbero sicuramente utili quali:
- possibilità di controllare il verificarsi di un overflow a seguito di una operazione aritmetica (questo può essere fatto solo leggendo opportuni flag);
- possibilità di eseguire operazioni in parallelo (per eseguire operazioni multi-thread è necessario salvare il contesto quindi accedere ai registri interni).
Questi problemi vengono però comunque aggirati grazie ad apposite librerie di sistema (ad esempio la io.h)
Le cose si complicano se la CPU alla quale il codice è destinato non ha una architettura von Neumann bensì una Harvard. Nel primo caso memoria dati e memoria programma usano lo stesso spazio di memoria, ma nel secondo caso possono essere usate memorie di vario tipo come ad esempio Flash, EEPROM, RAM le cui caratteristiche differiscono notevolmente da un tipo all’altro ed il linguaggio C tradizionale non prevede il supporto per diverse tipologie di memoria per cui è necessario utilizzare funzioni diverse. Ad esempio, si supponga di dover scrivere 10 caratteri in una variabile file che risiede su disco, quindi trasferirli in RAM. Il codice C dovrà essere il seguente:
ram char buffer[10]; // Array in RAM
disk char file[10]; // Array su Disco
for (i=0;i<10;i++)
{
file[i]=’0’;
}
// Scrittura in memoria
strncpy(file,buffer,10);
Si noti che le variabili vengono dichiarate allo stesso modo, ma differisce la funzione utilizzata per accedervi: nel caso della variabile su disco viene usata la funzione di assegnazione diretta (file[i]=’0’), mentre per la variabile in memoria viene usata la funzione strncpy.
Meglio strutture o array?
Tutti i manuali di C sottolineano quanto le strutture (intese come tipi di dati) siano utili per rendere il codice chiaro e leggibile, ma nel mondo embedded non sempre questa è una scelta ottimale.
Si consideri ad esempio un array di strutture del tipo:
struct SENSOR
{
unsigned char state;
unsigned char value;
unsigned char count;
}
struct SENSOR Sensors[10];
La lettura del valore value di un singolo sensore comporta una moltiplicazione ed una addizione e questo non è certamente ottimale in un sistema in cui le risorse sono limitate. In questo caso si possono usare tre array:
unsigned char Sensor_states[10]; unsigned char Sensor_values[10]; unsigned char Sensor_counts[10];
Questa seconda soluzione rende meno leggibile il codice, ma allo stesso tempo ne velocizza l’esecuzione. Come prova di questo, è stato utilizzato un sorgente C per la lettura e la copia di byte dalla struttura e dall’array e compilato con AVR-GCC utilizzando le opzioni di ottimizzazione “-O0” (nessuna ottimizzazione) e “-O3” (ottimizzazione sulla velocità). I risultati sono riportati nella tabella 1: si noti come nella lettura sia molto più performante utilizzare un array, mentre nella copia la struttura dà i risultati migliori.
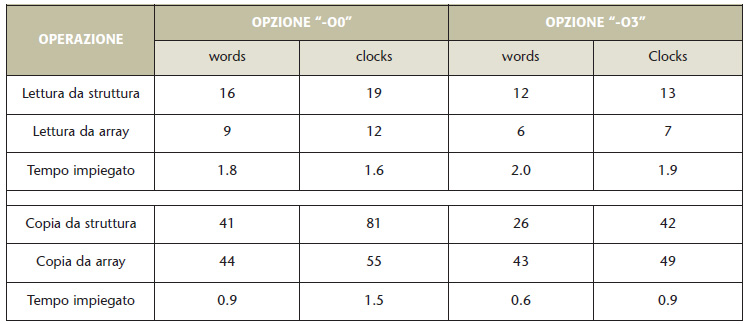
Tabella 1. Risultati delle prove di prestazioni
Se statisticamente il programma prevede frequenti operazioni di lettura è consigliato dunque l’utilizzo dell’array, mentre se sono previste frequenti operazioni di copia è più indicato l’uso di una struttura.
Salti condizionati
Un altro punto molto importante nella programmazione dei sistemi embedded sono le condizioni di salto. Sicuramente l’uso del costrutto switch() faciliterà senz’altro la lettura del codice, ma anche qui non sempre risulta essere la scelta migliore. La tabella 2 riporta i risultati della prova effettuata con il codice del listato 1.
char a;
char With_switch()
{
switch(a)
{
case ‘0’: return 0;
case ‘1’: return 1;
case ‘A’: return 2;
case ‘B’: return 3;
default: return 255;
}
}
char With_if()
{
if(a==’0’) return 0;
else if(a==’1’) return 1;
else if(a==’A’) return 2;
else if(a==’B’) return 3;
else return 255;
}
| Listato 1 |
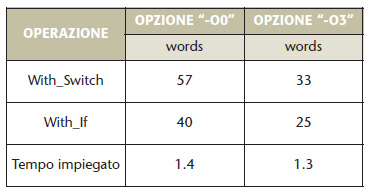
Tabella 2. Risultati delle prove sul listato 1
Allocazione dinamica della memoria
In un computer l’allocazione dinamica della memoria viene gestita dal sistema operativo, ma nei sistemi embedded privi di un vero e proprio sistema operativo è il compilatore che crea appositi segmenti di memoria. Anche in questo caso dunque è bene valutare prima di scegliere se fare uso o meno della memoria dinamica. Si consideri ad esempio il seguente codice che non utilizza la memoria dinamica:
char a[100];
void main(void)
{
a[30]=77;
}
Poiché l’indirizzo dell’elemento in cui scrivere è noto, il codice generato è molto ridotto (50 words) e la scrittura nell’array avviene in due cicli di clock. La stessa azione può essere effettuata utilizzando l’allocazione dinamica della memoria:
char * a;
void main(void)
{
a=malloc(100);
a[30]=77;
free(a);
}
In questo caso però il programma compilato ha dimensioni molto maggiori (325 words) e la scrittura dell’elemento avviene in sei cicli di clock. Rispetto alla precedente versione il programma è cresciuto di 275 words di cui 157 dovute alla funzione malloc e 104 dovute alla funzione free oltre alle 14 word necessarie per la chiamata di tali funzioni. Inoltre l’array creato dinamicamente viene inizializzato con tutti valori nulli il che comporta un ulteriore uso di risorse. Questo esempio dimostra quindi che l’uso dell’allocazione dinamica della memoria è da evitare in tutti quei casi in cui le risorse sono limitate.
Errori da evitare
Nella lettura di una stringa dalla memoria Flash, il compilatore AVR-GCC non è in grado di riconoscere autonomamente se il puntatore alla stringa si riferisce alla memoria dati o alla memoria programma (per default viene considerata la RAM). Per leggere una stringa da memoria Flash è necessario dunque utilizzare la macro contenuta in pgmspace.h:
#include // include files
#include pgmspace.h
prog_char hello_str[]=”Hello AVR!”;
void puts(char * str)
{
while(PRG_RDB(str) != 0)
{
PORTB=PRG_RDB(str++);
}
}
void main(void)
{
puts(Hello_str);
}
Si consideri ora il caso in cui si deve leggere un bit da una porta specifica:
void Wait_for_bit()
{
while( PINB & 0x01 );
}
È necessario tener conto che se viene abilitata l’opzione di ottimizzazione il compilatore calcola prima il valore di (PINB & 0x01), scrive il risultato in un apposito registro quindi ne esegue il test. Questo meccanismo non prevede che il valore del pin in esame può variare in maniera asincrona, quindi cambiare durante l’esecuzione del test. Per prevenire questo inconveniente è necessario utilizzare la macro contenuta in sfr_gefs.h (che è parte della libreria io.h):
void Wait_for_bit()
{
while ( bit_is_set(PINB,0) );
}
Una cosa analoga avviene nel caso in cui una funzione è in attesa di un interrupt visto che il flag può cambiare in qualsiasi momento:
unsigned char flag;
void Wait_for_interrupt()
{
while(flag==0);
flag=0;
}
SIGNAL(SIG_OVERFLOW0)
{
flag=1;
}
In questo caso la soluzione è utilizzare una variabile volatile:
volatile unsigned char flag;
void Wait_for_interrupt()
{
while(flag==0);
flag=0;
}
SIGNAL(SIG_OVERFLOW0)
{
flag=1;
}
Altro tipico errore è quello di utilizzare un ciclo vuoto per la generazione dei ritardi:
void Big_Delay()
{
long i;
for(i=0;i<1000000;i++);
}
Una funzione di questo tipo non altera le variabili locali e globali e non ritorna alcun valore, per cui attivando l’opzione di ottimizzazione del compilatore, questa funzione potrebbe essere completamente ignorata.
Per evitare questo basta utilizzare la funzione nop dell’assembler nel seguente modo:
define nop() {asm(“nop”);}
void Big_Delay()
{
long i;
for(i=0;i<1000000;i++) nop();
}
Altri suggerimenti utili
Per quanto visto in precedenza nella programmazione di sistemi embedded con linguaggi di alto livello, si deve sempre giungere ad un compromesso tra dimensioni del codice e velocità di esecuzione. Prima di iniziare la stesura di un programma è bene dunque valutare quale dei due fattori sia il più rilevante. In generale è bene tener conto che:
- Utilizzare funzioni in-line permette di evitare chiamate a funzioni remote velocizzando l’esecuzione del programma, ma ciascuna funzione viene copiata nell’opportuna parte di programma, provocando un aumento delle dimensioni del codice talvolta anche significativo. Si consiglia di utilizzare funzioni in-line solo quando queste vengono usate frequentemente e sono costituite da poche linee di codice.
- Utilizzando salti condizionati con il comando switch, è bene mettere nelle prime posizioni i casi più frequenti in modo da arrivare al matching delle condizioni nel più breve tempo possibile. In questo modo ne gioverà il tempo di esecuzione del programma.
- Utilizzare istruzioni in-line in assembler per le parti di codice che risulterebbero poco ottimizzate se scritte in C.
- Se nel programma vi sono delle variabili usate molto frequentemente, è utile dichiararle con la parola chiave Register in modo che queste vengano assegnate ad un registro generale velocizzando i tempi di accesso.
- Utilizzare il più possibile variabili globali in modo da ridurre le operazioni di push/pop nello stack in fase di chiamata e ritorno da una funzione.
- Evitare il più possibile aritmetica floating-point in micro privi di FPU. Se il micro non è datato di FPU, il compilatore esegue una serie di funzioni per emulare il comportamento della FPU con conseguente incremento delle dimensioni del codice. Spesso è possibile effettuare divisioni e moltiplicazioni semplicemente scorrendo a destra o a sinistra il contenuto di una variabile.
- Utilizzare tipi di dati strettamente necessari: se si necessita di un intero su 8 bit, evitare l’uso del tipo int (che normalmente viene espresso su più di 8 bit – tipicamente 16 o 32) preferendo il tipo unit.
- Utilizzare il comando goto in alternativa a complesse strutture condizionali: questo permette di ridurre i tempi di esecuzione evitando le operazioni di comparazione.



Davvero un ottimo articolo su una tematica interessante e (purtroppo) sempre meno considerata! Inoltre ci sono vari spunti per ulteriori articoli: architetture di CPU (hai accennato a Von Neumann e Harvard), opzioni di ottimizzazione per compilatori, approfondimento sulle parole chiavi del C (pragma, volatile, inline, register ecc). Tutti argomenti che, nel mondo dell’odierno “tutto e subito”, vengono spesso non curati o totalmente ignorati dagli sviluppatori! Ciao Emanuele, ci vediamo sabato a Pescara!
Salve Davide,
sicuramente il campo è molto vasto, in quanto il C embedded è mio avviso un mondo parallelo del classico ansi/c per PC. In questo ambiente, come dici tu giustamente, sono fondamentali le direttive al compilatore e quindi bisogna avere piena conoscenza sia del compilatore stesso che della macchina (microcontrollore) sulla quale si sta lavorando.
Personalmente ho sempre preferito programmare in ASM (non dico assembler altrimenti si scatena la bagarre nei commenti) fino agli 8BIT mentre su micro a 16 o 32 BIT la compilazione riesce ad essere più ottimizzata. Purtroppo in giro si vede di tutto, anche compilatori BASIC per micro ad 8BIT….
P.C. Ci vediamo sabato all’Arduino Day 🙂
Ciao,
è molto encomiabile l’idea di scrivere un articolo del genere, complimenti!
Credo però sia utile chiarire i limiti dei casi a cui ti riferisci… ad esempio che il caso dell’array rispetto alla struttura è vero solo per tipi con sizeof = 1 (altrimenti la moltiplicazione ha ovviamente luogo lo stesso). Varrebbe anche la pena, forse, suggerire modi efficienti per visitare gli array (puntatori) ove possibile.
Buon lavoro!
Sono stati messi in risalto i principali temi che legano il C con i micro: ad esempio i salti condizionati e le strutture/array. Disporre di una serie di regole per ottimizzare i sistemi embedded non è banale e in pochi (pochissimi) libri vengono analizzate in dettaglio.
Trovo questo articolo non solo interessante ma “indispensabile” per chi opera col linguaggio C nel mondo dei sistemi embedded.
Se dovessi dare un voto darei 9.; ma questo solo perchè poi Emanuele potrebbe avere la tentazione di non superarsi ancora.
Tornando serio: una serie di consigli, considerazioni, idee e “dritte” che solo una persona esperta come Emanuele poteva “confezionare” per noi di EOS.
Pillole di “saggezza embedded” allo stato puro; da stampare, tenere sul comodino e rileggere prima di addormentarsi !!!
Grazie Emanuele e a presto.
Ciao,
Da non molto tempo mi sto riavvicinando al mondo dei microcontrollori che ho purtroppo lasciato negli anni in cui programmavo gli ST6 utilizzando Realizer. Ho realizzato alcune applicazioni con Arduino e la sua IDE. Leggendo questi articoli ho cercato di utilizzare Netbeans come IDE e configurare tutto ciò che è utile per creare l’interfaccia corretta.
Mi sono scontrato con tutta una serie di problemi ed errori che man mano ho risolto. Ad ora sono fermo sul riconoscimento dei file header che Netbeans non trova. Penso che il problema sia all’interno del makefile, perché tutte le configurazioni dell’IDE sono corrette. Volevo sapere se esiste documentazione più accurata rispetto a quella esistente su internet che rispecchi le procedure corrette. Io lavoro su Mac OS 10.10.5 Yosemite, grazie e cordiali saluti
Valter