
Come realizzare un driver per la gestione di una tastiera, il debounce dei tasti, il riconoscimento corretto dei fronti, le funzioni di codifica e autorepeat dei tasti.
Introduzione
L’articolo descrive in dettaglio la struttura di un driver per la gestione di una tastiera. Saranno descritte le funzioni di basso livello per la lettura corretta dei tasti, le procedure per il riconoscimento dei fronti o dello stato dei tasti e tutte le funzioni del driver: autorepeat dei tasti premuti, gestione del buffer tastiera. I listati di esempio sono scritti in linguaggio ‘C’. Il driver per la gestione della tastiera può essere suddiviso in tre livelli
- Acquisizione dei tasti
- Riconoscimento dello stato dei tasti
- Codifica e interfaccia di alto livello (non sempre presente)
Si comincerà descrivendo un driver per la gestione di 8 tasti per poi passare alla gestione di una tastiera a matrice.
L’acquisizione dei tasti
Si consideri per ora una tastiera formata da 8 tasti. Ogni tasto è collegato ad un ingresso del microcontrollore, l’ingresso viene letto a 1 quando il tasto è premuto. In caso contrario la procedura del driver dovrà semplicemente invertire il dato letto dalla porta di ingresso. I lettori che seguono la rivista dal primo numero avranno già letto l’articolo in cui si affronta il problema dell’acquisizione corretta dei tasti. In breve, il problema è questo: la commutazione di un ingresso associato ad un tasto non è mai netta ma per un piccolo intervallo di tempo il segnale d’ingresso oscilla tra la tensione di alimentazione e la tensione zero. La lettura dell’ingresso in questo intervallo di tempo fornisce uno stato 0/1 casuale e quindi inattendibile che può portare ad un errata interpretazione dello stato della tastiera con le ovvie conseguenze. In questo articolo verrà proposta una tecnica molto semplice e affidabile che non richiede risorse o periferiche del microcontrollore ma si basa sulla lettura periodica dello stato della tastiera. La periodicità T deve essere superiore al tempo di debounce dei tasti così una lettura sbagliata sarà corretta dalla lettura successiva. Normalmente l’aggiornamento dello stato dei tasti può essere fatto ogni T = 20/30ms. Poiché ogni applicazione ha un proprio interrupt di timer periodico che fornisce le temporizzazioni a tutto il sistema, basterà inserire la chiamata alla procedura di lettura della tastiera all’interno di questo interrupt. Per esempio se utilizziamo un interrupt di timer di 5ms basterà definire un contatore software per ottenere il tempo di acquisizione corretto come descritto nel Listato 1.
char kbdtmr ;
#define KBDTMRSET 4 // 20ms/5ms
void interrupt BasicT() // interrupt richiamato ogni 5ms
{
if (--kbdtmr == 0)
{
kbdtmr = KBDTMRSET ;
kbdread() ;
}
}
| Listato 1 |
La lettura è ovviamente asincrona rispetto alla pressione dei tasti, quindi è molto probabile che si facciano delle letture sbagliate mentre un tasto commuta. Per riconoscere ed eliminare le letture sbagliate si utilizza un buffer a tre livelli in cui si memorizzano le ultime tre letture. Se la periodicità della lettura è T=20ms e se KBDPORT è la porta del microcontrollore a cui sono collegati gli ingressi dei tasti, la procedura kbdread() avrà la struttura del Listato 2.
Kbdread()
{
keyn2 = keyn1 ; // lettura fatta a t-2T = t-40ms
keyn1 = keyn0 ; // lettura fatta a t-T = t-20ms
keyn0 = KBDPORT ; // lettura fatta all’istante t
}
| Listato 2 |
La scelta del tempo di acquisizione si giustifica con queste due affermazioni:
- Il periodo T di acquisizione è superiore al tempo di debounce quindi non ci sono due letture consecutive sbagliate. Se la prima lettura è sbagliata la seconda e le successive sono sicuramente corrette.
- Il tasto rimane premuto per un tempo superiore al periodo T di acquisizione e viene riconosciuto in almeno due (in realtà molte di più) letture successive.
L’analisi dello stato
La procedura kbdread() viene richiamata all’interno di un interrupt quindi deve terminare nel minor tempo possibile. La decodifica dello stato dei tasti perciò viene delegata ad una procedura (task) a priorità inferiore inserita nel ciclo principale del programma applicativo. Ci sono molte tecniche per sincronizzare il task con la procedura di interrupt. Il modo più semplice è quello di utilizzare un flag. La procedura kbdread() attiva il flag mettendolo a 1. Il task controlla lo stato del flag e quando lo trova a 1 esegue l’aggiornamento dello stato della tastiera. Prima di terminare azzera il flag. Il listato 3 descrive la procedura Kbdread() in cui si utilizza la variabile systemflags per memorizzare i flags di sistema.
#define FKBDUPDATE 0x01 // definzione del flag agg. tastiera
kbdread()
{
keyn2 = keyn1 ; // lettura fatta a t-2T = t-40ms
keyn1 = keyn0 ; // lettura fatta a t-T = t-20ms
keyn0 = KBDPORT ; // lettura fatta all’istante t
// attiva task aggiornamento dello stato della tastiera
systemflags |= FKBDUPDATE ;
}
Mentre il task di gestione tastiera avrà questa struttura
void KBDtask()
{
If (systemflags & KBDUPDATE) // devo eseguire il task ?
{
// azzera richiesta esecuzione task
systemflags &= ~KBDUPDATE ;
}
}
| Listato 3 |
Il flag KBDUPDATE è il flag utlizzato per la sincronizzazione. La prima operazione che deve effettuare il task è quella di eliminare le letture non corrette. Questa operazione viene effettuata con la formula:
keyfn0 = (keyn0 & keyn1) | (keyn1 & keyn2) | (keyn0 & keyn2)
Dove keyfn0 contiene lo stato della tastiera dopo il filtraggio di debounce.
Per l’ipotesi fatta all’inizio i tasti premuti sono letti come bit a 1 dal microcontrollore. La tabella in figura 1 elenca lo stato delle variabili del driver riferite al generico istante t, mentre la tabella di figura 2 descrive cosa accade in caso di lettura errata.
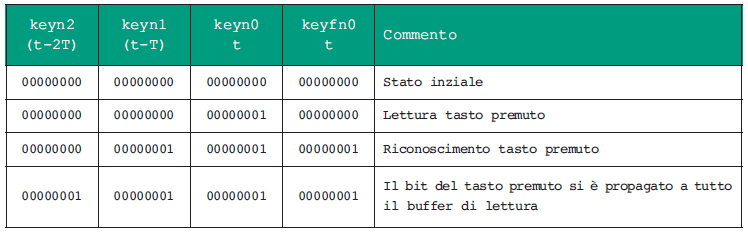
Figura 1. Acquisizione dello stato della tastiera
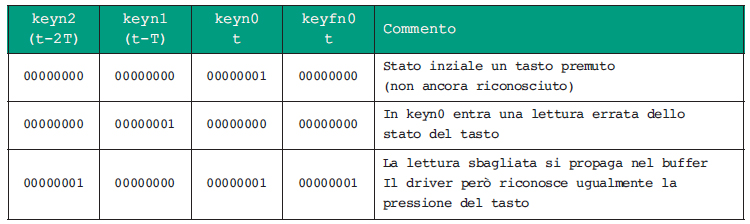
Figura 2. Filtraggio di una lettura errata
Il concetto è molto semplice si applica il criterio della ridondanza 2 su 3. Un tasto è dichiarato premuto quando viene riconosciuto premuto in almeno due letture su tre. Il periodo T di lettura è stato scelto in modo da evitare due letture ambigue consecutive dello stesso tasto. Dopo aver eliminato le letture ambigue bisogna analizzare lo stato della tastiera per ricavare informazioni su tasti permuti (fronti di salita) tasti rilasciati (fronti di discesa) o tasti mantenuti premuti. Per fare questo si memorizzano due letture consecutive dello stato filtrato della tastiera.
char keyfn1 // stato dei tasti filtrati all’istante t-T
char keyfn0 // stato dei tasti filtrati all’istante t
L’aggiornamento delle variabili all’interno del task è il seguente:
keyfn1 = keyfn0 // shift del buffer
keyfn0 = (keyn0 & keyn1) | (keyn1 & keyn2) | (keyn0 & keyn2) // debounce
Le formule per il riconoscimento dei fronti sono molto semplici:
FrontUP = (keyfn0 ^ keyfn1) & keyfn0 ;
FrontDN = (keyfn0 ^ keyfn1) & keyfn1 ;
Dopo l’operazione di xor la maschera conterrà 1 solo se lo stato del tasto è cambiato 0_1 (tasto premuto) o 1_0 (tasto rilasciato) tra le due letture. L’operazione di and con lo stato attuale filtra solo i cambiamenti 0_1 (fronti di salita o tasto premuto). L’operazione di and con lo stato precedente filtra solo i cambiamenti 1_0 (fronti di discesa o tasto rilasciato)). La tabella di figura 3 riassume quanto descritto.
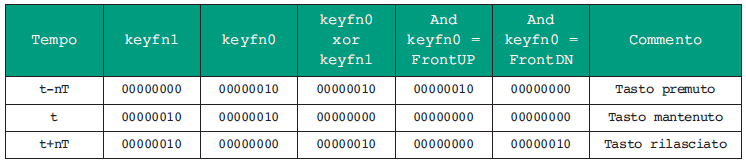
Figura 3. Riconoscimento dei fronti di salita e discesa
I tasti mantenuti premuti devono trovarsi a 1 in entrambe le letture e si possono facilmente ricavare con l’operazione logica di AND:
holdkey = (keyfn0 & keyfn1)
Per evitare comportamenti casuali all’avvio del programma, il driver deve assegnare a tutte le variabili un valore noto come descritto nel listato 4.
void kbdinit()
{
keyn2 = keyn1 = keyn0 = 0 ;
keyfn1= keyfn0 = 0 ;
holdkey = 0 ;
// installa procedura interrupt kbdread
}
Molto spesso il driver di tastiera è inserito direttamente nell’applicazione. In questo caso l’applicazione ha accesso diretto alle tre variabili FrontDN FontUP e holdkey. Altre volte i driver e l’applicazione sono due programmi separati. Chi realizza l’hardware normalmente fornisce solo i driver per la gestione delle periferiche. In questo caso è necessario aggiungere al driver un terzo livello per scambiare i dati con l’applicazione.
L’interfaccia verso l’applicazione
In questo livello si effettua l’analisi dello stato della tastiera. Il driver, dopo aver aggiornato le tre variabili di stato FrontDN FontUP e holdkey, codifica le informazioni per renderle disponibili all’applicazione. La procedure keycheck() ricerca nella variabile FontUP i bit a 1 che corrispondono alla pressione di un tasto. Normalmente il driver passa all’applicazione il codice del tasto premuto ricavandolo dalla tabella di codifica della tastiera keycodes. Molto semplicemente keycodes può contenere i codici ascii dei caratteri associati ai tasti. Questa procedura è descritta ne listato 5.
const char kecodes[] = { ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’}
char keyndx ;
Keycheck()
{
char Key ;
keyndx = 0 ;
for (mask = 0x01 ; (mask != 0) ; mask <<= 1)
{
if (frontUP & mask) // se tasto premuto
{
key = Keycodes[keyndx]; // codice tasto premuto
}
keyndx++ ; // codice tasto successivo
}
}
| Listato 5 |
É anche possibile fornire più tabelle di codifica (lingue diverse) e lasciare all’applicazione il compito di definire quale codifica utilizzare. Per sincronizzare lo scambio dei dati tra il driver e l’applicazione si utilizza un buffer. Il driver scrive in un buffer circolare i codici dei tasti premuti. L’applicazione legge dal buffer lo stato della tastiera utilizzando le procedure messe a disposizione dal driver (API). La dimensione del buffer dipende da diversi fattori, per semplicità, ma non è un vincolo, si utilizza un multiplo di 2 quindi 16 o 32 byte possono essere sufficienti. L’indice putndx definisce la prima posizione disponibile per la scrittura di un nuovo tasto mentre l’indice getndx definisce la posizione del primo tasto non ancora letto dall’applicazione. La nuova funzione keycheck() che inserisce i codici dei tasti premuti nel buffer circolare è riportata nel Listato 6.
#define KBDBUFFSIZE 32
char Kbdbuffer[KBDBUFFSIZE] ;
char* putndx = kbdbuffer ;
char* getndx = kbdbuffer ;
keycheck()
{
keyndx = 0 ;
for (mask = 0x01 ; (mask != 0) ; mask <<= 1)
{
if (frontUP & mask) // se tasto premuto
{
Kbdbuffer[putndx++] = KEYCODETBL[keyndx];
}
keyndx++ ; // codice tasto successivo
}
}
| Listato 6 |
Per non appesantire la procedura sono stati omessi i controlli sull’indice putndx. Prima di inserire il nuovo codice si deve controllare se il buffer è pieno. Dopo l’inserzione si deve controllare se il puntatore ha raggiunto il limite del buffer circolare.
Le API d’interfaccia
Un driver di tastiera deve definire almeno quattro API base:
kbhit() verifica la presenza di un tasto nel buffer.
getc() legge un carattere senza rimuoverlo dal buffer.
getch() legge un carattere togliendolo dal buffer.
kbdflush() azzera il buffer di tastiera.
Il listato 7 descrive le quattro API elencate.
char kbhit() // verifica la presenza di un dato nel buffer di tastiera
{
return (putndx == getndx) ;
}
char getc() //legge un tasto dal buffer senza rimuoverlo
{
char ch = 0 ;
if (putndx != getndx) ch = Kbdbuffer[getndx];
return (ch) ;
}
char getchar() // legge un tasto rimuovendolo dal buffer
{
char ch = 0 ;
if (putndx != getndx) ch = Kbdbuffer[getndx++];
getndx %= KBDBUFFSIZE ; // getndx assume valori 0..KBDBUFFSIZE (*)
return (ch) ;
}
// L’espressione equivale a:
// if (getndx >= KBDBUFFSIZE) getndx = getndx - KBDBUFFSIZE ;
void kbdflush() // Azzera il buffer di tastiera
{
putndx = getndx = 0 ;
}
| Listato 7 |
La codifica dei tasti
La codifica del tasto può avvenire in diversi modi. Normalmente si associa al tasto il codice ascii corrispondente. In genere la codifica non richiede valori maggiori di 127 (codice esadecimale 0x7F) pertanto si può utilizzare il bit più significativo per indicare il rilascio del tasto. Ad esempio se premendo un tasto viene inserito il codice ‘A’ = 0x41 al rilascio il driver inserirà il codice 0x80+0x41 = 0xC1; Sarà compito poi dell’applicazione distinguere e gestire la pressione o il rilascio dei tasti. Un’altra tecnica è quella di codificare ogni tasto in due byte. Un byte rappresenta il codice ASCII del tasto nell’altro si può codificare lo stato premuto/rilasciato. Le procedure getchar e getch in questo caso restituiscono una variabile intera (2byte).
La funzione di autorepeat
Questa funzione inserisce periodicamente nel buffer di tastiera il codice dei tasti che rimangono permuti oltre un certo tempo prestabilito. Quando il driver riconosce la pressione di un tasto, carica il timer di autorepeat con il ritardo di attivazione (600/700ms circa). Se in questo intervallo di tempo il tasto viene rilasciato (esame di FrontDN) il timer viene bloccato, altrimenti al timeout si analizza la variabile holdkey per stabilire quale tasto ha attivato la funzione di autorepeat. Il codice associato al tasto viene inserito nel buffer di tastiera e il timer ricaricato con il ritardo di ripetizione di 300/400ms. Ad ogni successivo timeout il codice del tasto viene nuovamente inserito nel buffer finché il tasto non viene rilasciato o il buffer non è pieno. Il listato 8 descrive una prima versione della procedura kbdcheck() che gestisce la funzione di autorepeat.
kbdcheck()
{
Keyndx = 0 ;
for (mask = 0x01 ; (mask != 0) ; mask <<= 1)
{
if (frontUP & mask) // se tasto premuto
{
Kbdbuffer[putndx++] = KEYCODETBL[keyndx];
// start autorepeat timer con ritardo lungo
}
if (frontDN & mask) // se tasto rilasciato
{
// stop autorepeat timer
}
If (holdkey & mask) // tasti permuti ?
{
If (autorepeat timeout) // timeout del timer di autorepeat ?
{
Kbdbuffer[putndx++] = KEYCODETBL[keyndx];
// reload autorepeat timer
}
}
Keyndx++ ; // codice tasto successivo
}
}
| Listato 8 |
In realtà la procedura del listato 8 nasconde un problema. Se si preme un tasto mentre c’è già un tasto premuto e quindi la funzione di autorepeat è già attiva, il comportamento è casuale. Al timeout del timer di autorepeat il codice di un solo tasto fra tutti quelli premuti viene inserito nel buffer. Per eliminare questo inconveniente la scelta migliore è quella di inserire sempre il codice dell’ultimo tasto permuto ignorando eventuali altri tasti. Per realizzare questa funzione il codice dell’ultimo tasto premuto viene memorizzato in una variabile. Al timeout del timer di autorepeat questo codice viene copiato nel buffer. Premendo due o più tasti solo l’ultimo verrà gestito dal timer di autorepeat. La versione corretta della procedura kbdcheck() è riportata nel listato 9.
char lastkeycode ; // memorizza il codice dell’ultimo tasto premuto
kbdcheck()
{
keyndx = 0 ;
for (mask = 0x01 ; (mask != 0) ; mask <<= 1)
{
if (frontUP & mask) // se tasto premuto
{
Lastkeycode = Kbdbuffer[putndx++] = KEYCODETBL[keyndx];
// start autorepeat timer con ritardo lungo
}
if (frontDN & mask) // se tasto rilasciato
{
// rilascio del tasto gestito in autorepeat
If (lastkeycode == KEYCODETBL[keyndx])
// stop autorepeat timer
}
If (timer autorepeat timeout)
{
Kbdbuffer[putndx++] = lastkeycode ;
// ricarica autorepeat timer con ritardo breve
}
keyndx++ ; // codice tasto successivo
}
}
| Listato 9 |
Se i tasti sono più di 8?
La soluzione intuitiva è quello di aumentare il numero degli ingressi dedicati ai tasti. Ovviamente esistono delle tecniche più efficienti che permettono di ridurre il numero di pin necessari per l’interfaccia della tastiera. Per fare un esempio con gli stessi 8 ingressi con cui il driver descritto in precedenza gestiva 8 tasti si possono gestire 16 tasti (il doppio!!) organizzati in una tastiera a matrice.
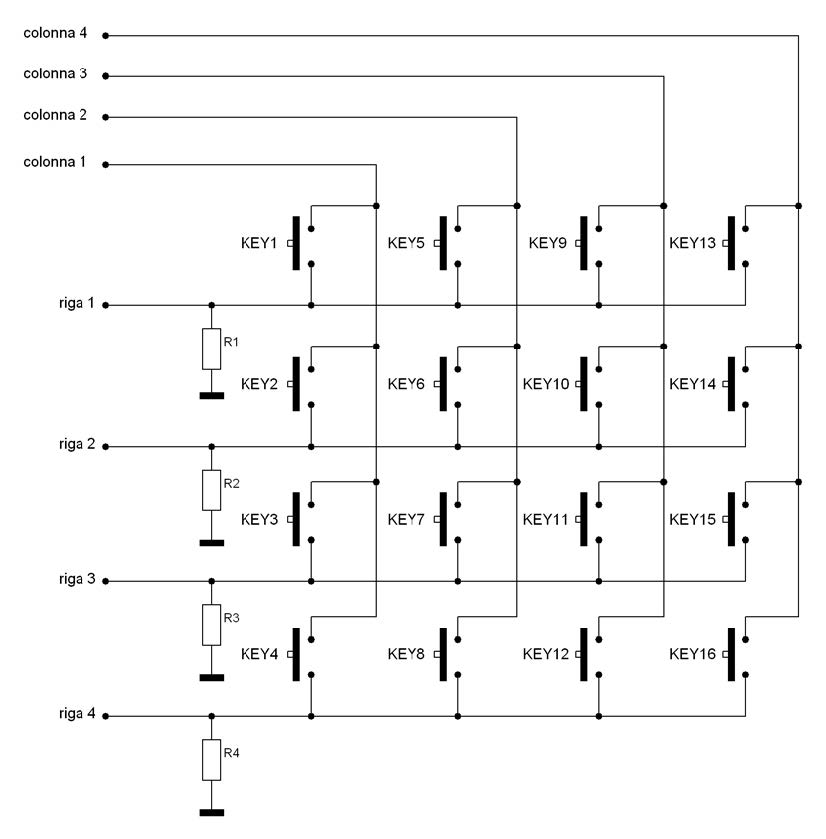
Figura 4. Schema di una tastiera a matrice di 16tasti organizzata 4righex4colonne
Normalmente si parla di righe e colonne della tastiera. L’organizzazione della matrice dei tasti dipende da diversi fattori: disposizione dei tasti, complessità del circuito della tastiera…la matrice non deve essere necessariamente simmetrica (stesso numero di righe e di colonne) anche se a parità di pin la distribuzione simmetrica permette di collegare il maggior numero di tasti. Se la tastiera è asimmetrica (numero di righe diverso dal numero di colonne) allora è preferibile scandire la tastiera utilizzando il numero più piccolo tra i due per ridurre i tempi di acquisizione. Ad esempio in una tastiera 3x5 (3 righe x 5 colonne) conviene scandire la tastiera per righe. Si può effettuare la scansione della tastiera indifferentemente per righe o per colonne. Se si effettua la scansione per righe (colonne) i pin del microcontrollore collegati alle righe (colonne) della tastiera sono configurati in output mentre quelli collegati alle colonne (righe) devono essere configurati in input. Il driver descritto in seguito utilizza la scansione per colonne della tastiera.
La scansione della tastiera
Il driver per la gestione della tastiera descritto in precedenza funziona correttamente anche per una tastiera a matrice. Ovviamente aumentando il numero dei tasti deve aumentare anche la dimensione delle variabili. Non saranno più char ma diventeranno unsigned per gestire 16 tasti o unsigned long per gestire 32 tasti oppure si possono trasformare in vettori di char. Nell’ipotesi di scansione per colonne, queste ultime sono collegate a pin di output del micro. In ogni istante una sola uscita si trova a 1 e il corrispondente pin del microcontrollore si porta alla tensione V. Se nessun tasto viene premuto le righe, cioè gli ingressi del microcontrollore, si trovano tutte a zero perché bloccate dalle resistenze delle resistenze di pull down. Se si preme un tasto che appartiene ad una colonna con uscita a zero la situazione non cambia. Se si preme un tasto che appartiene alla colonna collegata all’uscita a 1 anche il corrispondente ingresso si porta a 1. L’algoritmo di acquisizione della tastiera diventa:
- Il microcontrollore mette a 1 un’uscita.
- Attende del tempo.
- Legge lo stato degli ingressi.
- Riparte dal punto 1.
Quando ha terminato la scansione di tutte le uscite il ciclo riprende. La figura descrive lo stato delle uscite del microcontrollore per la scansione della tastiera a matrice. In ogni istante solo un’uscita si trova allo stato logico1.

Figura 5. Temporizzazione delle uscite per la scansione di una tastiera a matrice a 4 colonne
L’unica procedura del driver che deve essere modificata è la procedura di acquisizione kbdread(). Il listato 10 descrive l’acquisizione di una tastiera a matrice di 16 tasti organizzata in 4 righe e 4 colonne.
unsigned key // ultima acquisizione
unsigned keyn2 // buffer con le ultime tre letture
unsigned keyn1
unsigned keyn0
char kbdcolscan = 0x10 // maschera scansione colonne tastiera
#define KBDMASK 0x0F // maschera ingressi tastiera
void kbdread()
{
key <<= 4 ; // shift della maschera di acquisizione
key += (KBDPORT & KBDMASK); // aggiungi la lettura di una colonna
kbdkcolscan << = 1 ; // sposta la maschera scansione colonne
If (kbdcolscan == 0) // se scansione completa
{
keyn2 = keyn1 ; // aggiorna il buffer di acquisizione
keyn1 = keyn0 ;
keyn0 = key ;
key = 0 ;
kbdcolscan = 0x10 ; // riprendi la scansione delle colonne
systemflags |= FKBDUPDATE ; // richiedi esecuzione del task
}
KBDPORT = kbdcolscan ; // cambia lo stato delle uscite
}
| Listato 10 |
La tastiera è collegata alla porta KBDPORT del microcontrollore, i quattro pin meno significativi sono collegati alle righe (ingressi) e i quattro pin più significativi alle colonne (uscite) Ogni volta che un’uscita viene posta a 1 si attende il tempo T prima di leggere gli ingressi corrispondenti della tastiera. La procedura è identica a quella vista all’inizio. Ora però per completare un’acquisizione sono necessarie più chiamate alla procedura Kbdread() (nell’esempio descritto quattro) prima di aggiornare lo stato della tastiera. Le variabili keynx (x=0,1,2) memorizzano lo stato della tastiera nelle diverse letture con il formato descritto in figura 6.

Figura 6. Maschera bit memorizzazione stato tastiera
Ad ogni operazione di shift key << = 4 lo stato dei tasti acquisiti viene spostato in avanti nella variabile key per fare spazio alla nuova acquisizione come rappresentato in figura 7.
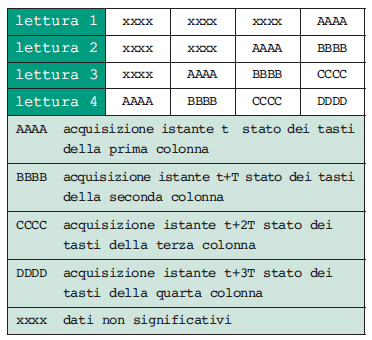
Figura 7. Ciclo di lettura di una tastiera a matrice
Il problema del tasto fantasma
L’acquisizione della tastiera a matrice realizzata come descritto in precedenza nasconde un problema che può portare ad un errata interpretazione dei tasti premuti. Si consideri ad esempio i quattro tasti A B C D di una tastiera a matrice. La colonna rappresentata in figura 8A con una linea più grossa si trova alla tensione V.

Figura 8. Tasto fantasma in una tastiera a matrice
Premendo il tasto A anche la prima riga della tastiera si porta alla tensione V (figura 8B) e il microcontrollore riconosce il tasto A premuto. A questo punto premendo il tasto B per il microcontrollore non cambia nulla perché riconosce solo l’intersezione che corrisponde al tasto A. Premendo il tasto B però anche la seconda colonna si porta alla tensione V (figura 8C) Se ora viene premuto il tasto D anche la seconda riga si porta alla tensione di uscita (figura 8D). Il microcontrollore interpreta la pressione contemporanea dei tasti ABD come se fossero premuti i tasti A e C mentre C non è premuto. Per questo si parla di tasti fantasma. Per eliminare questo inconveniente ci sono due possibilità: la prima intervenire sulla realizzazione della tastiera inserendo dei diodi che impediscono la propagazione della tensione nel modo descritto. La seconda realizzare un filtro software che elimina questa ambiguità. Il filtro è molto semplice: se nella lettura di una colonna si trovano due o più tasti premuti la lettura viene ignorata (alla fine uno si stancherà di mantenere tre o più tasti premuti…). Se è richiesta la pressione contemporanea di più tasti, ad esempio per tasti shift o ctrl, si devono prevedere degli ingressi dedicati per questi tasti comuni.


Ottimo driver C che mette in risalto come funziona una tastiera all’interno di un software di programmazione. Credo che sia possibile anche implementarlo per un classico tastierino numerico.
Salve , sono un appassionato di volo sia reale che quello virtuale.
vorrei realizzare un un sistema che corrisponda ai comandi impartiti dalla tastiera pc; con pulsanti esterni. Il simulatore è XPLAN 11 , ecc.ecc.
Potresti auitarmi per lo scopo. Grazie anticipatamente Antonio.
Mia mail :[email protected]