
In questo articolo proponiamo un interessante dispositivo capace di abilitare due diversi carichi con il semplice comando della voce. La particolarità del circuito risiede nel fatto che non sono utilizzate shields supplementari o circuiti aggiuntivi, per raggiungere lo scopo. L'intero sistema usa, infatti, solo un semplice microfono a condensatore. Il prototipo costituisce un punto iniziale per sviluppare applicazioni più importanti e utili.
La voce che comanda
E' spesso comodo poter attivare un circuito con la voce, magari se si hanno entrambe le mani occupate. Quello proposto di seguito è un didattico circuito che attiva due diversi carichi con altrettanti comandi vocali. Per la precisione, il comando "TV" attiva il diodo Led collegato alla porta 16 di ESPertino, mentre il comando "SCALDABAGNO" attiva il Led collegato alla porta 17 della stessa scheda. Dal momento che si tratta solo di un circuito sperimentale è necessario premere il tasto "Reset" sulla scheda, ad ogni invio del comando. Tale comportamento può essere facilmente modificato.
ESPertino non conosce le parole
Attenzione: il sistema proposto non è in grado di discriminare realmente le parole e identificare i fonemi che le compongono. L'algoritmo, infatti, si limita ad analizzare la forma d'onda prodotta dalla voce e la confronta con dei modelli presenti in memoria. Il modello più simile dovrebbe corrispondere al comando vocale impartito tramite il microfono. La digitalizzazione di parole e frasi, infatti, crea dei segnali audio caratterizzati da una particolare forma d'onda. Uno dei metodi seguiti è quello di rappresentare tale insieme di dati in forma matematica per poi confrontarli con dei modelli standard. La figura 1 mostra le registrazioni delle parole "SCALDABAGNO" e "TV" eseguite da tanti individui appartenenti a entrambi i sessi e a varie fasce d'età. Si nota subito la somiglianza tra i segnali registrati, a parità di parole pronunciate. Il sistema sfrutta proprio tale aspetto.

Figura 1: le forme d'onda delle parole create da soggetti diversi
Nonostante i comandi vocali siano stati dettati da persone diverse, si può notare che il pattern di ogni parola rispetta un modello simile e costante.
La figura 2, invece, focalizza la diversità dinamica tra le due forme d'onda appartenenti, rispettivamente, alle parole "SCALDABAGNO" e "TV".
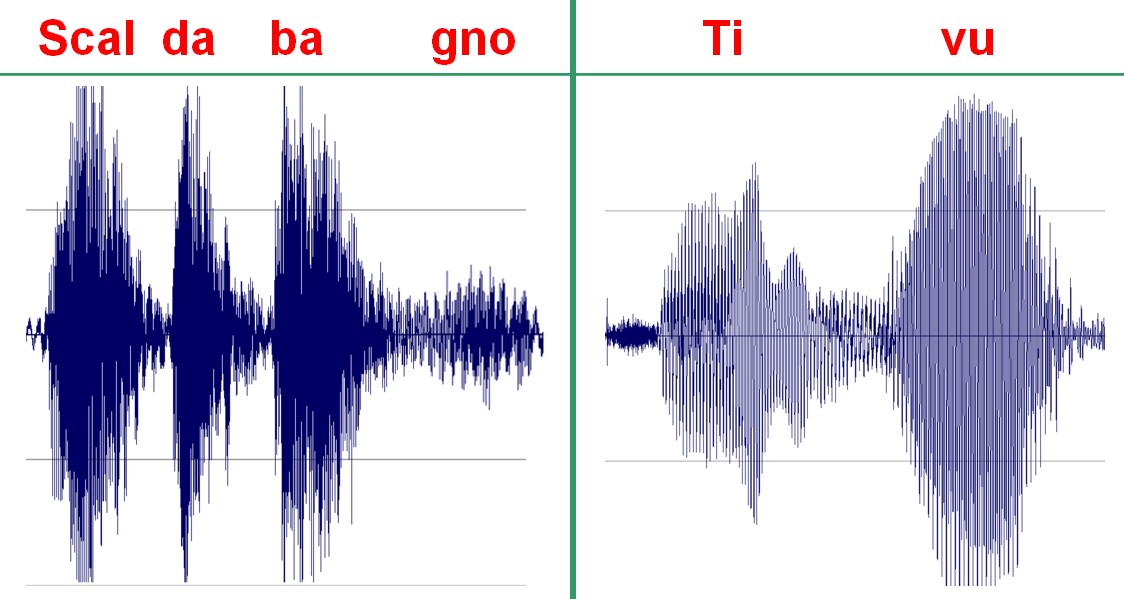
Figura 2: le differenze dinamiche tra le due forme d'onda relative alle parole "Scaldabagno" e "TV"
Come creare un modello di parola/comando
La prima fase da seguire è quella dell'addestramento di ESPertino. E' una procedura, se vogliamo, lontanamente simile a ciò che fa l'uomo. Esso impara a riconoscere dei modelli di suoni, senza analizzarne campione per campione. Per la registrazione dei due modelli di comando, corrispondenti alle parole "SCALDABAGNO" e "TV", utilizziamo il programma Wavosaur, un bel software leggero e semplice per la gestione dei segnali audio. Esaminiamo, dunque, tutte le fasi, al fine di ricavare i modelli da memorizzare nella memoria RAM di ESPertino.
Prima fase: registrazione del comando
Si avvii il programma Wavosaur (a breve pubblicheremo un articolo descrittivo in merito). Si prema il tasto rosso e si può registrare subito il comando, ad esempio "Scaldabagno", parlando vicino al microfono. La figura 3 mostra la videata subito dopo questa operazione. Fate in modo da non tagliare le semionde, parlando troppo forte. Al limite ripetete la registrazione.
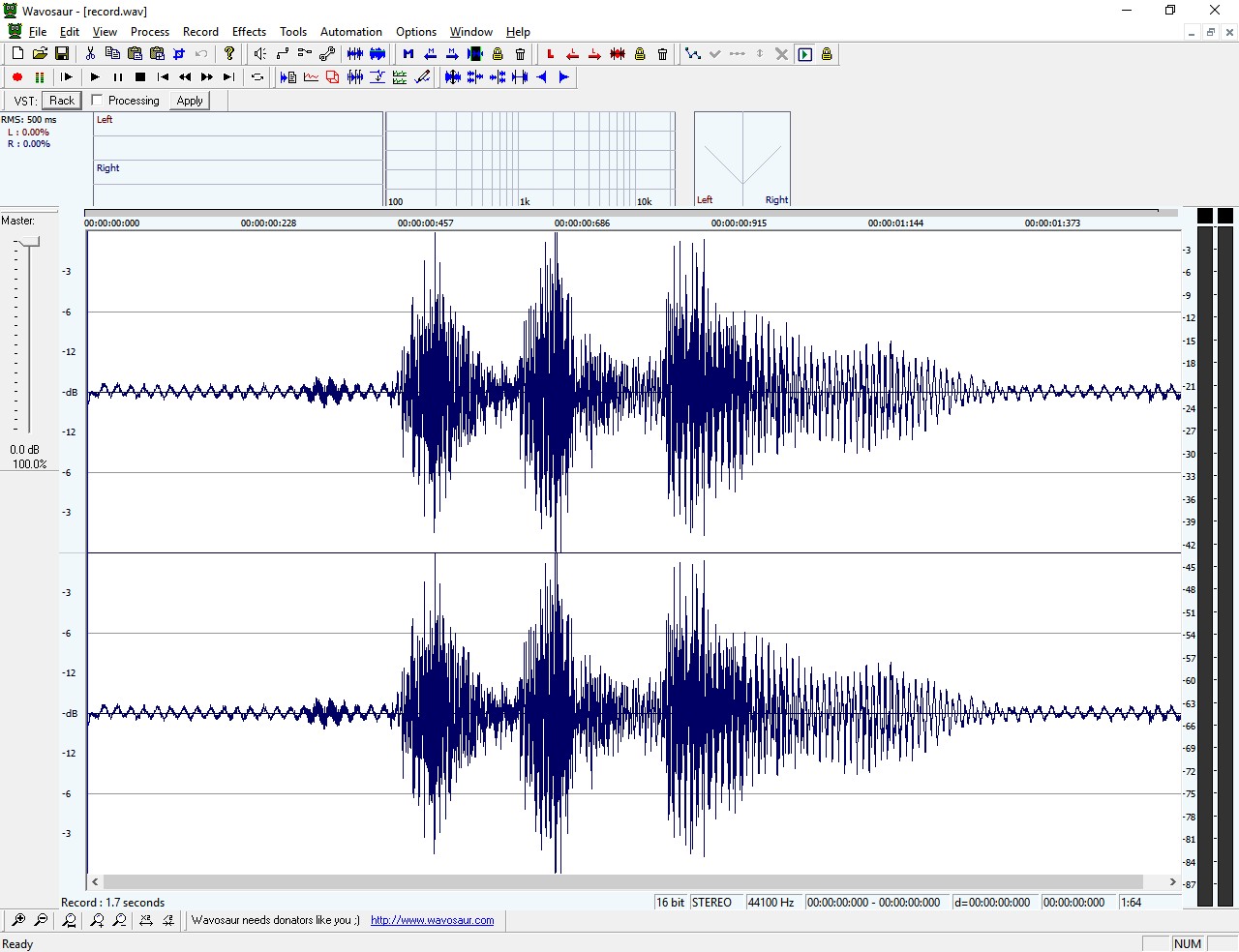
Figura 3: la registrazione del comando "Scaldabagno" con Wavosaur
Il segnale così acquisito non va bene, deve essere post-processato. In particolare occorre:
- Trasformare le due tracce in mono (menù Process);
- Eseguire un resample a 22050 Hz (menù Process);
- Tagliare il silenzio iniziale e quello finale (selezionare con il mouse e premere il tasto Canc).
Solo così si può ottenere una forma d'onda adatta alle successive elaborazioni, come si può osservare nella figura 4.
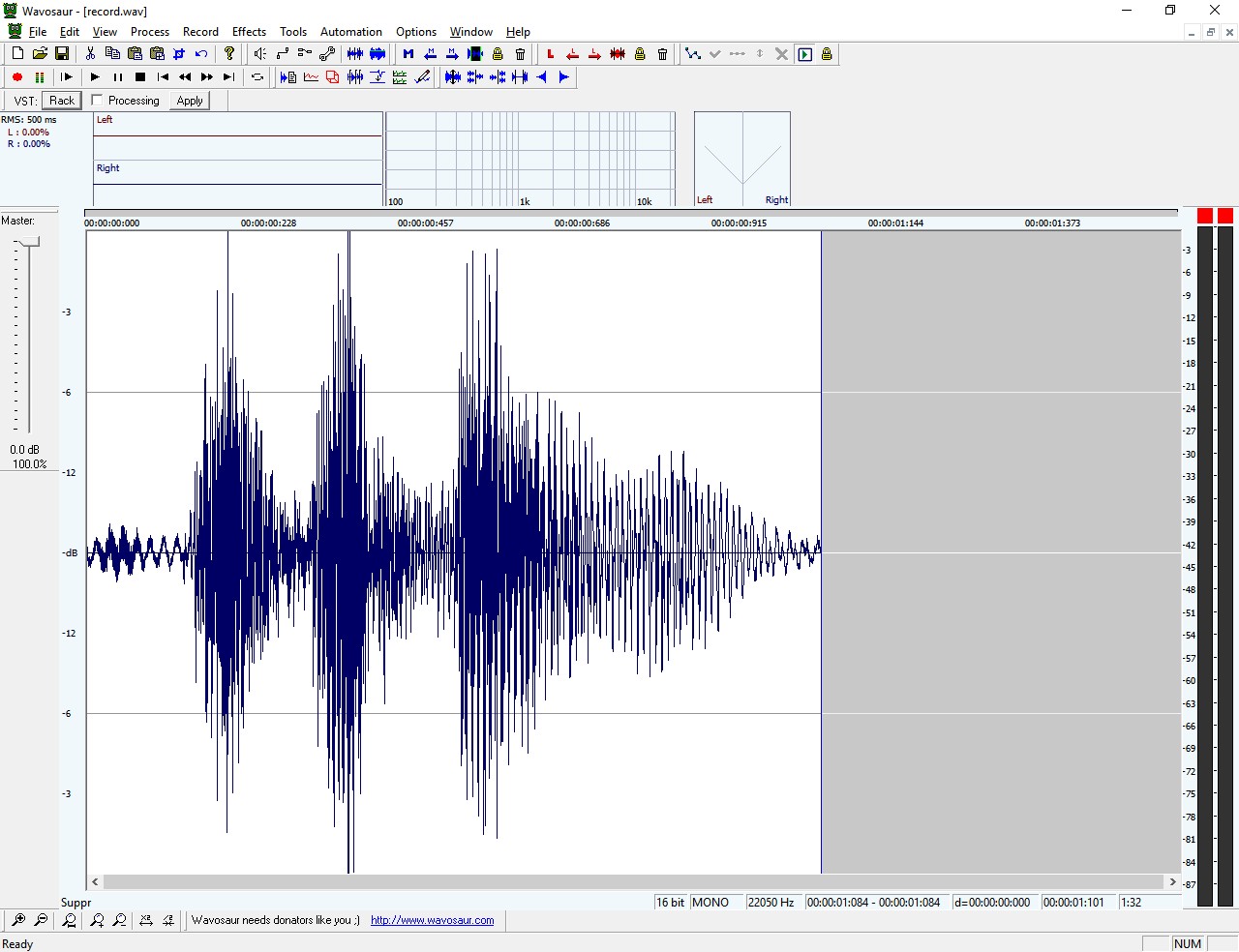
Figura 4: il segnale è stato ripulito e adattato con Wavosaur
Seconda fase: suddivisione in 20 segmenti
La RAM dell'ESP32 non è molto grande. Inoltre non è necessario gestire le migliaia di campioni che fanno parte dell'intera forma d'onda. Ne bastano molti di meno, diciamo venti, per descrivere in forma generale un determinato comando.
Per questo scopo si deve esportare, sempre con il Wavosaur, il segnale registrato in formato TXT, accedendo al menù File, Export e, infine, Export as Text. Sarà creato un file testuale contenente tutti i campioni della forma d'onda registrata, compresi tra -1 e 1. La figura 5 mostra uno stralcio di tale documento.
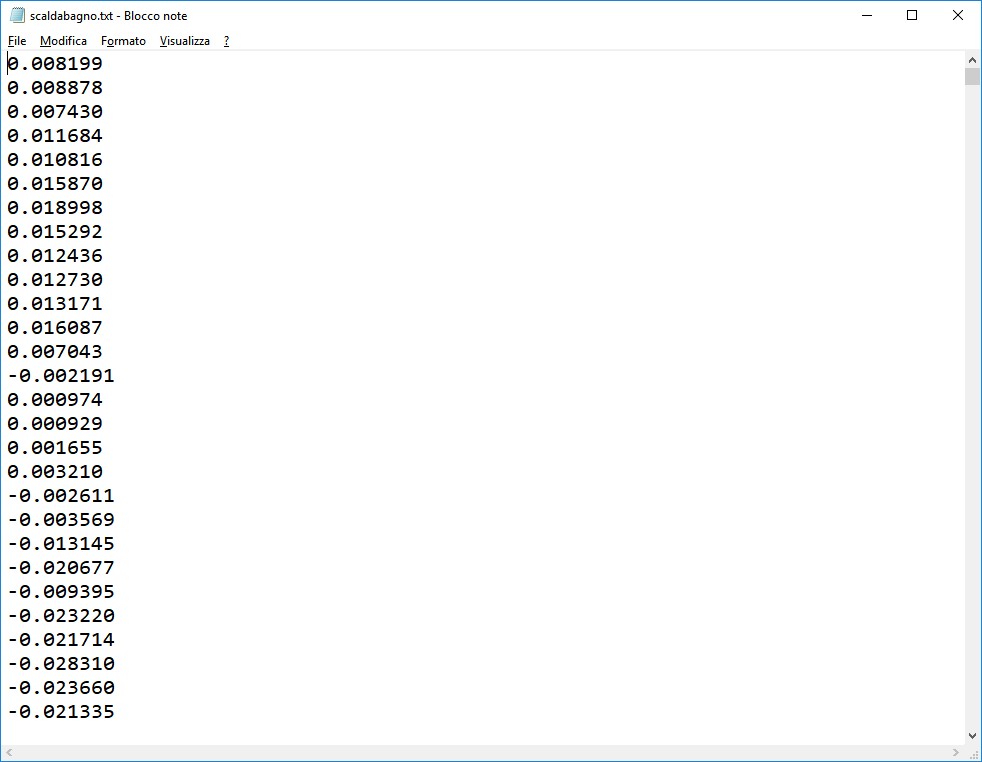
Figura 5: esportazione dei campioni in formato TXT
Tutti i campioni esportati si devono suddividere in venti gruppi e di ogni raggruppamento occorre prendere il valore massimo. Quest'ultimo costituisce il campione modello da considerare nei raffronti successivi. Non si può prendere il valore medio di essi in quanto il segnale contiene semionde positive e negative e il risultato sarebbe, praticamente, nullo. Abbiamo realizzato, a tutti gli effetti, una sorta di rivelazione d'onda di tipo software, radiantisticamente parlando.
Il nostro segnale dell'esempio contiene ben 24280 campioni. Ognuno dei venti gruppi, pertanto, dovrà contenere 1214 campioni (24280/20). La ricerca del massimo di ogni gruppo può avvenire tramite foglio elettronico oppure con l'ausilio di un piccolo script, scritto in qualunque linguaggio di programmazione. I venti valori massimi calcolati per l'esempio sono riportati nella seguente tabella:
| 0 | 0.093282 |
| 1 | 0.0807 |
| 2 | 0.285447 |
| 3 | 1 |
| 4 | 0.609658 |
| 5 | 0.256361 |
| 6 | 0.931281 |
| 7 | 1 |
| 8 | 0.363859 |
| 9 | 0.260479 |
| 10 | 0.941954 |
| 11 | 0.946097 |
| 12 | 0.500263 |
| 13 | 0.43764 |
| 14 | 0.292481 |
| 15 | 0.31729 |
| 16 | 0.319028 |
| 17 | 0.220881 |
| 18 | 0.129024 |
| 19 | 0.070921 |
Essi generano un modello molto più semplice che ben rappresenta la forma sommaria dell'onda, come visualizzato in figura 6. Ribadiamo, ancora una volta, che le parole di comando scelte devono essere molto diverse tra loro, sia a livello di fonetica che di dinamica temporale, al fine di creare il meno possibile occasioni di ambiguità tra i modelli. Si esegua tale procedura per tutte le parole di comando previste nel prototipo.
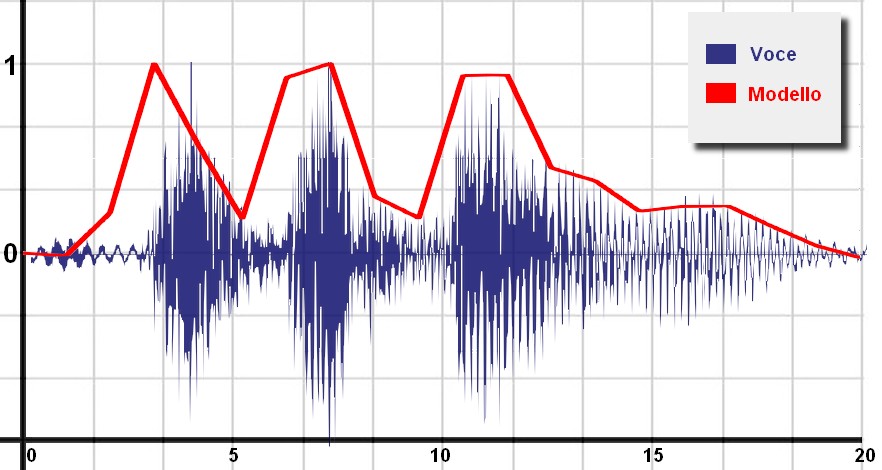
Figura 6: il comando vocale (in blu) e il relativo modello semplificato (in rosso)
Terza fase: adeguamento del modello all'intervallo 0~100
I venti campioni ottenuti con l'operazione precedente, di tipo float e compresi tra 0.00 e 1.00, devono essere adeguati a un nuovo intervallo, per la loro migliore gestione. In particolare, essi saranno compresi tra 0 e 100 e di tipo intero, per le seguenti motivazioni:
- In questo modo essi sono velocemente e più facilmente trattabili dall'ESP32;
- Il fatto di risultare di tipo "intero" migliora la loro elaborazione.
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2519 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:

Oggi esistono circuiti integrati, altamente sofisticati, che contengono hardware e firmware per un perfetto riconoscimento vocale. Quello presentato nell’articolo è semplicemente un primo approccio alla materia, estremamente complessa e sofisticata, come tutte quelle connesse alle sensorialità umane.
Anche questo articolo non riesco a leggerlo tutto.
Mi dite per favore come ovviare a questa limitazione?
Grazie